Content before more comment is regarded as page excerpt.
January 1, 2020About 1 min
Content before more comment is regarded as page excerpt.

![Image 1: FLUX.1 Kontext [dev]](https://cdn.sanity.io/images/gsvmb6gz/production/d14326c68b9dd45088913aa19580f2c904be31af-940x377.jpg?rect=31,0,878,377&w=960&h=412&fit=max&auto=format)
How using GitHub’s free inference API can make your AI-powered open source software more accessible.

Until recently, the best way to generate images of a consistent character was from a trained lora. You would need to create a dataset of images and then train a FLUX lora on them.
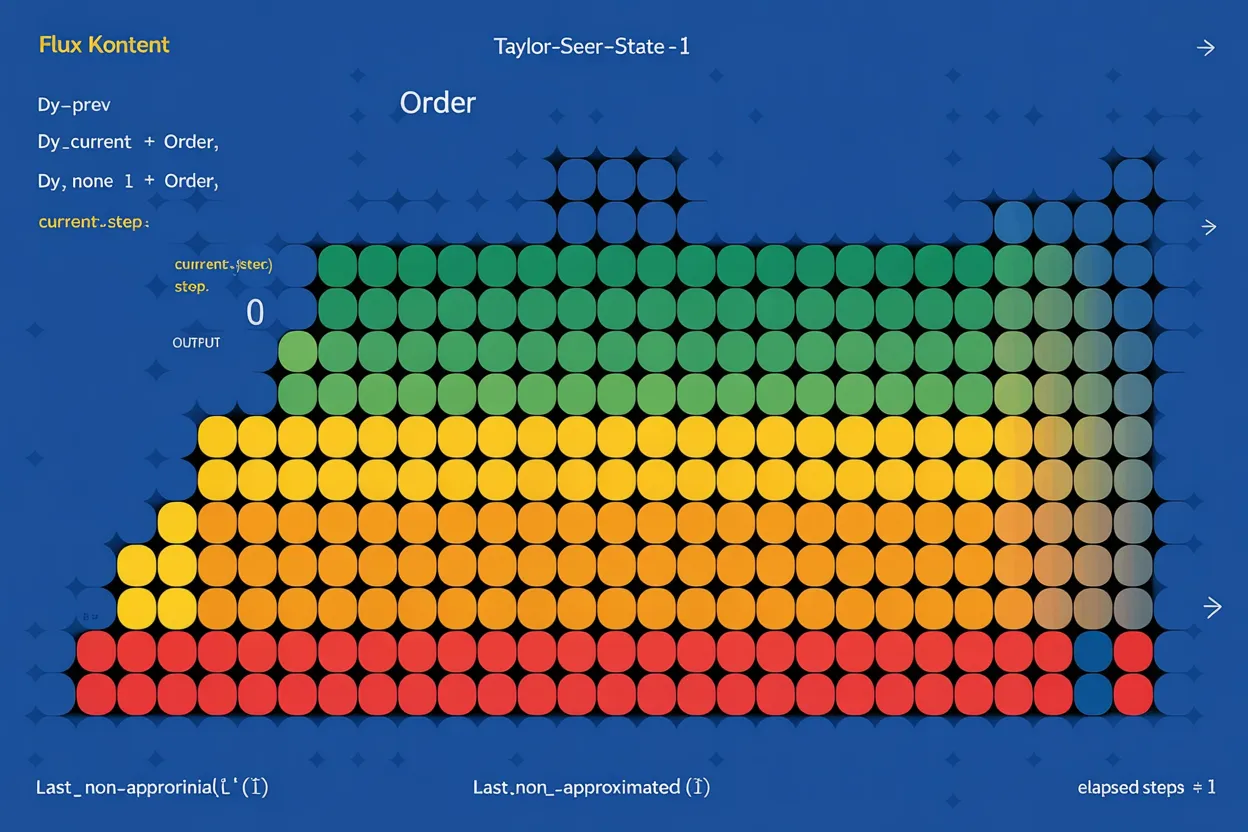
In addition to making our FLUX.1 Kontext [dev] implementation open-source, we wanted to provide more guidance on how we chose to optimize it without compromising on quality.
Long time no see! We've been long overdue for an update.
And this one is really impressive. WE MADE AN ANIME OPENING!!! Er, I mean, Niji can now generate videos!!!!!!!!
While I'm generally psyched about each and every feature we make, I can say for sure that video-fying your pictures is the best damn thing we've shipped in a while. I really hope you enjoy it!
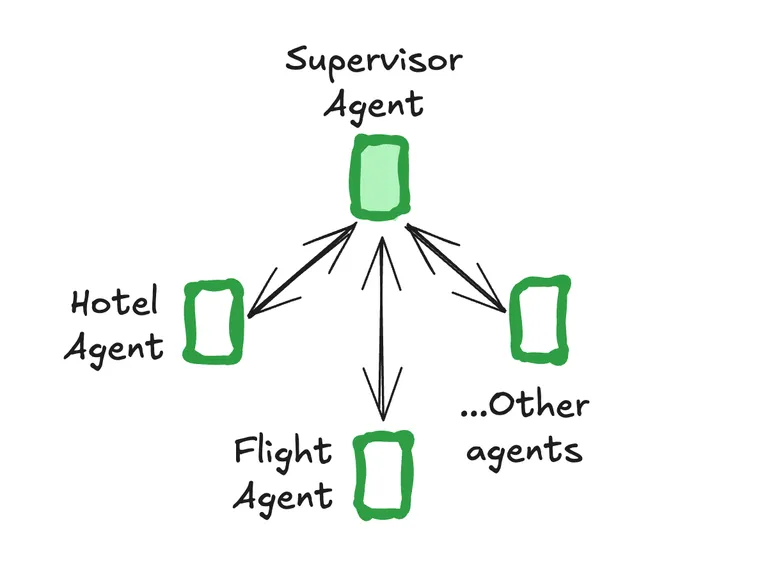
Late last week two great blog posts were released with seemingly opposite titles. "Don't Build Multi-Agents" by the Cognition team, and "How we built our multi-agent research system" by the Anthropic team.

Imagine a young girl named Emma who is fascinated by birds. Every weekend, she visits a nearby park to watch birds with her grandfather. Over time, Emma learns to recognize different bird species by their color, size, shape, and even their chirps. One afternoon, while flipping through a book, she effortlessly points to a picture and says, "Look, Grandpa! It's a robin!" She doesn't measure wingspans or analyze feather types; her brain instantly connects the image to her experiences and memories of robins at the park.