[Experiment Report] Investigating the Influence of Each U-Net Layer with Model Block Merge #1
[Experiment Report] Investigating the Influence of Each U-Net Layer with Model Block Merge #1

Table of Contents
- Introduction
- Experiment Overview
- Experiment 1
- Analysis 1
- Experiment 2
- Analysis 2
- Side Note 1
- Experiment 2 Setup
- Experiment 2: Results and Analysis
- Analysis Approach and Reminders (to me)
Introduction
Model Block Merge has gained recognition and expectations as a merging technique that can produce different good results compared to conventional methods. The shared results have begun to appear, and the beautiful images continue to heal my heart and fill up my disk space daily. (This is a blessing. I'm grateful to the artists/technical experts.)
(※This technique was presented by kohya_ss in the article below.)
(※I created an Extension for AUTOMATIC1111's Web UI based on this technique.)
However, since it's a new method, it's difficult to say we clearly understand how to achieve the desired effects. One issue is that there are as many as 25 parameters, and the lack of established methods for evaluating output results and models makes verification challenging. (※Here, "model" is used almost synonymously with checkpoint file)
Experiment Overview
Therefore, I planned experiments with the goals of "finding verification methods" and "providing insights and speculations as discussion material."
Specifically, I explored whether it's possible to make a layer transparent in the merging process (Experiment 1) or to increase/decrease its effect (Experiment 2).
※If you want to see the results quickly, please go to "Experiment 2: Results Analysis".
Experiment 1
Analysis 1
Is it possible to make the target layer of the model "do nothing"?
If we could exclude the effect of a specific layer, we could examine its influence by comparing with normal output results.
Since my knowledge of NN and U-Net is limited, I made somewhat speculative predictions. "If the tensor of the target layer of the model acts like an inertia tensor I for the equation of motion ma=F (this part is vague...), then to behave transparently, it should be something like a unit vector" (just a thought) Upon investigation, topics like unit tensor I and identity mapping came up, but thinking more deeply, this would cause data loss. Looking into torch, I found exactly what I needed!
torch.ones_like
Returns a tensor filled with the scalar value 1.
With this, I could make input * ones tensor = output = input! But when I tried it, it didn't work well... why...
Experiment 2
Analysis 2
I decided to change direction. By reducing the merge ratio for specific layers of an existing model, create "a model with weakened influence from that layer" and examine the impact by comparison.
In the current normal merge implementation, the calculation uses merge ratio M (range: 0 to 1) as follows:
Merged model result = (1 - M) * model_A + M * model_BBy changing this calculation as follows, I made it possible for the sum of model A ratio M_A and model B ratio M_B to not equal 100% in the output merged model.
Merged model result = M_A * model_A + M_B * model_B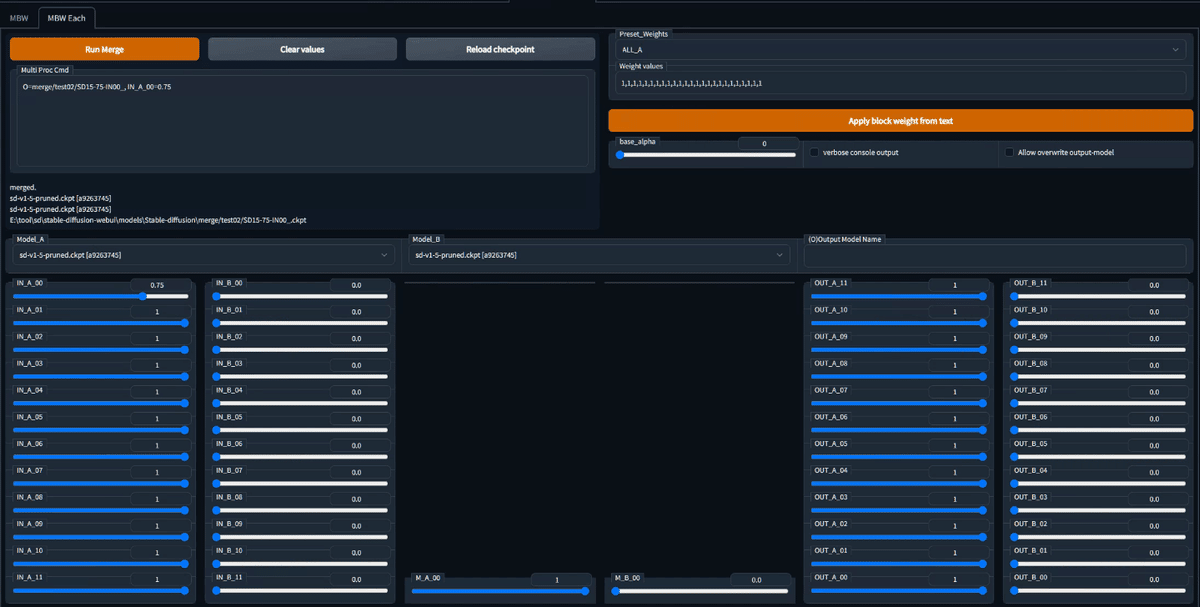
UI of the experimental modified Merge Block Weighted Extension Example of setting model A component of IN_00 to 0.75
Side Note 1
Actually, "Add difference" in AUTO1111 also doesn't maintain "summing to 100%" in the same way. The formula used is O = A + M * (B-C), so the output model O is model A with M% of the difference between models B and C added to it, meaning model O appears to be "larger" than model A.
There is some criticism of this Add Difference process, such as "should we not make it sum to 100% when merging?" or "aren't we just breaking the model?"
Experiment 2 Setup
Target models: model A = Stable Diffusion v1.5 pruned, model B also the same Merge settings: IN_00 to IN_11, M_00, OUT_00 to OUT_11, each multiplied by 0.75. For the target layer only, M_A=0.75, M_B=0. For others, M_A=1, M_B=0 Prepared models: 25 layer-merged models, 1 SD15 model Seeds: 1, 2, 3, 4 Test prompt: In PNG Info format, as follows:
masterpiece, best quality, beautiful anime girl, school uniform, strong rim light, intense shadows, highly detailed, cinematic lighting, taken by Canon EOS 5D Simga Art Lens 50mm f1.8 ISO 100 Shutter Speed 1000
Negative prompt: lowres, bad anatomy, bad hands, error, missing fingers, cropped, worst quality, low quality, normal quality, jpeg artifacts, blurry
Steps: 40, Sampler: Euler a, CFG scale: 7, Seed: 1, Face restoration: CodeFormer, Size: 512x512, Model hash: a9263745, Model: sd-v1-5-prunedExperiment 2: Results and Analysis
I organized the output results in a U-shaped layout for examination and relative comparison. Each layer's output images show Seeds 1-4 arranged horizontally.
※I've attached the images generated in the experiment and the HTML set to display them in the format below. Please use it if you want to see enlarged images.

Analysis Approach and Reminders (to me)
• Focus on character, face (detailed expression), overall composition, and background. • Important note for Experiment 2: Since we're "multiplying the model's capability for that layer by 0.75", my hypothesis is that if we observe certain features in the image, we should interpret it as "the opposite capability has been lost". • I'll write in the structure of "Result observation", "Interpretation/speculation (if any)", and "Summary".
Observation 1: Character placement and composition hardly change in IN_01 to IN_11

The direction of the character's body and the realism/anime style of the face varied, but there were no major changes in composition. Also, no major breakdowns were observed in the character or overall composition.
From this, it seems that "overall composition is largely determined in the upper layers of IN, with no significant changes afterward". Also, there's a possibility that "breakdowns in the overall or background are not due to IN's influence (meaning M to OUT might be responsible)" (discussed later).
(A somewhat extreme hypothesis) Looking at Seed:2 or Seed:3 vertically, we see a back-and-forth between anime and realistic styles. This might indicate the influence of that layer's handling of art style (anime/realistic). If this hypothesis is correct, "the upper layers of IN handle realistic style, while the lower layers handle anime style". (IN_07's seed:4, IN_08's seed:3 look quite realistic)

Observation 2: Expression changes significantly in M_00

In M_00, there were noticeable effects on the character, character details, and color tones compared to the previous IN_11 or standard output images. While the overall composition didn't change dramatically, there were changes in body direction, face size, clothing, and background. A major difference from normal output was that in Seed 4's result, the pink skirt was lost.
The M_00 layer, when losing its model influence, seems to significantly impact the output. (M_00's result loses the pink skirt, while IN_11 and OUT_00 before and after maintain it) On the other hand, the fact that it doesn't completely break down like the upper OUT layer results might be because the upsampling process + skip connection in the OUT block after M_00 somehow manages to maintain consistency. (Going from M_00 to OUT_00, it recovers to the same atmosphere as IN_11)
From this, it seems that "M_00 has an important/non-recoverable influence on overall details".
Observation 3: Everything breaks down after OUT_04

From OUT_04 to upper layers, there were disturbances in overall composition, background, and the entire image. ~The final form? Indeed, one cannot resist the ascending burden...~ In OUT_06, the character was barely hanging on.
The upper OUT layers should be at the stage where the whole is upsampled by U-Net's inverse convolution. Having lost model influence at this point, correct upsampling might be impossible. Also, the fact that the character somewhat remained in OUT_06 suggests that parts that have gained strong features up to that point (in this case, the character) remain, but weaker parts (like the background and other areas) are lost. Furthermore, the fact that the character's face breaks down significantly around OUT_04 to OUT_05 suggests that these layers have a major influence on face formation.
From this, it seems that "the upper OUT layers influence the overall reproduction of the output image". Also, "the upper OUT layers influence expressions other than the main subject (e.g., background)". Additionally, "OUT_04, OUT_05 have a significant influence on face determination".
Remaining Issues and Questions
For the following issues, I couldn't find significant change points or interpretations
(Question) Where does the realism of eyes and hands come from? (Question) Where does the texture of skin, 3D feel, and texture of character form come from? (Question) Why does the character revive when going from OUT_06 to OUT_07? (Question) Why is IN_00 producing significantly different results from others?
Afterword
In this experiment, I used the Stable Diffusion v1.5 model to lower the model's influence on each U-Net layer, and tried to examine the impact on the "image" from the verification results.
It's an achievement that I've obtained several hypotheses and speculations about the workings of each layer. On the other hand, many questions still remain. ~The swamp seems still deep. I'll keep digging!~
For further investigation, the following items might be worth considering:
- Similar studies on other models (single)
- Try the same analysis and organization on other models to see if similar trends can be observed (whether it's a universal trend of U-Net or a trend of the model)
- Whether similar effects and trends can be seen when merging different models
Personal Thoughts
This article is just an amateur's struggle, but thank you for reading this far. Personally, I love the explosive power of technology when openness is maintained, and I have high expectations. It's aptly said that prompts are like magic, but I hope we don't end up with a "concealment to escape persecution" kind of trend like when science and technology were studied as "magic" in the medieval period. The verification and trials we're conducting now might be easily overwritten by next-generation technology, but conversely, "struggling with what will be obvious to future generations" is a pleasure unique to us living in the present!
So, keep your conduct proper, and enjoy your generative AI life!
Side Note 2
By the way, this "Model Block Merge" process seems to be called by various names. Overseas, I've seen block merge, weight merge, etc. In Japan, it's called layer merge, layer-by-layer merge, hierarchical merge, block merge, etc.
Disclaimer
The experiments in this article weren't conducted with deep consideration, so I don't consider whether they're technically or academically correct. (Actually, I couldn't, due to my lack of study, there are many parts without foundation...) In my writing, I've tried to make it clear which parts are "my speculation," so I hope you enjoy it as reading material. Technical corrections are very welcome. (Like "You should study this!")
Acknowledgments & My Works URL Links
kohya_ss's "Merging Stable Diffusion models by changing ratios according to U-Net depth"
Everything started from this article. I'm grateful for the high-quality article.
Multi Block Merge GUI
My work.
Merge board
My work. Extends merging functionality. Allows handling merge combinations as text "recipes," recommended for those experimenting with merges. ※ It's also listed in AUTO1111's official list. Yay!