
Illustrious XL v2.0—The best training base model in 1536 age
Introduction
Illustrious XL 1.0-2.0 series aims to stabilize native generation at 1536 resolution while significantly improving natural language understanding capabilities.
While users sometimes observed successful 1024x1536 resolution generations, these were not stable. Similarly, 512x512 generations occasionally produced unwanted artifacts.
Why were earlier versions unstable?
The root cause of these inconsistencies is simple: the model was not generalized or trained effectively on these resolutions. Training with a small dataset to fill these gaps often leads to overfitting at certain resolutions. This meant that the model would associate specific resolutions with specific concepts, making it unreliable for diverse generations.
A useful analogy is the "wide shot" effect. If the dataset commonly features wide shots, the model will naturally generate smaller figures when given a wide-shot resolution, as this is how it has learned to generalize.
To resolve this, Illustrious XL v2.0 required an extensive dataset and large-scale training—comparable to the original v0.1 training—to eliminate bias across resolutions and datasets.

prompt: "stylish, no humans, city light, black theme, dim lighting, high contrast, night sky, masterpiece, absurdres, depth of field, butterflies, extremely aesthetic, absurdres, wallpaper, panorama, city background, neon, milky way, photo background, 512x512 generation"
 prompt: "The image features two characters,each with distinct black and white outfits,standing back-to-back. The character on the left wears a white coat with black accents,black pants,and boots,and is chained at the wrists and ankles. The character on the right is dressed in a black coat with white accents,black pants,and boots,also chained at the wrists and ankles. Both characters have spiked black hair and wield large key-shaped weapons. The background is white,and the text "Wielder Of The Key" and "Controls Light & Darkness" is displayed above and below the characters,respectively" Negative prompt: "worst quality, low quality, lowres, low details, bad quality, poorly drawn, bad anatomy, multiple views, bad hands, blurry, artist sign" Steps: 28, Sampler: Euler a, Schedule type: Automatic, CFG scale: 7.5, Seed: 3420215296, Size: 1248x1824
prompt: "The image features two characters,each with distinct black and white outfits,standing back-to-back. The character on the left wears a white coat with black accents,black pants,and boots,and is chained at the wrists and ankles. The character on the right is dressed in a black coat with white accents,black pants,and boots,also chained at the wrists and ankles. Both characters have spiked black hair and wield large key-shaped weapons. The background is white,and the text "Wielder Of The Key" and "Controls Light & Darkness" is displayed above and below the characters,respectively" Negative prompt: "worst quality, low quality, lowres, low details, bad quality, poorly drawn, bad anatomy, multiple views, bad hands, blurry, artist sign" Steps: 28, Sampler: Euler a, Schedule type: Automatic, CFG scale: 7.5, Seed: 3420215296, Size: 1248x1824
 prompt: "Generate a highly detailed anime-style illustration of a young man floating serenely above a sprawling, futuristic cityscape. The boy has dark, messy hair and piercing blue eyes. He's wearing a long, flowing white coat over dark, streamlined clothing – think a mix of traditional Japanese garments and futuristic techwear. His expression is calm and confident, almost detached. He is surrounded by a faint, glowing aura of light, possibly blue or white. Below him is a vast sci-fi city, filled with towering skyscrapers, holographic advertisements, and flying vehicles. The city should have a vibrant color palette – neon blues, purples, and pinks contrasting with darker metallic structures. There should be a sense of depth and scale, with buildings receding into the distance. The overall atmosphere should be epic and awe-inspiring, suggesting a powerful and mysterious character overlooking a technologically advanced world. Focus on dynamic lighting and detailed textures to create a visually stunning image. wlop, quasarcake, masterpiece"
prompt: "Generate a highly detailed anime-style illustration of a young man floating serenely above a sprawling, futuristic cityscape. The boy has dark, messy hair and piercing blue eyes. He's wearing a long, flowing white coat over dark, streamlined clothing – think a mix of traditional Japanese garments and futuristic techwear. His expression is calm and confident, almost detached. He is surrounded by a faint, glowing aura of light, possibly blue or white. Below him is a vast sci-fi city, filled with towering skyscrapers, holographic advertisements, and flying vehicles. The city should have a vibrant color palette – neon blues, purples, and pinks contrasting with darker metallic structures. There should be a sense of depth and scale, with buildings receding into the distance. The overall atmosphere should be epic and awe-inspiring, suggesting a powerful and mysterious character overlooking a technologically advanced world. Focus on dynamic lighting and detailed textures to create a visually stunning image. wlop, quasarcake, masterpiece"
Benchmarking Against Other Models
The objective was simple.
Robustness against natural language, with high resolution. Hopefully, Illustrious v2 and above, will reach a certain point - compared to existing models. Comparing Illustrious XL v2.0 with NoobAI-XL and Animagine XL 4.0 highlights key improvements in prompt adherence, style retention, and detail generation.

However, simply following the prompt is not enough. Take a look at FLUX Schnell's result. It performs well in prompt adherence but lack illustrative quality and style. What we are aiming for is, better prompt adherence (alignment) with illustration-related functionalities. Not just aesthetic, Not just stupid compute.

Instruction Tuning vs. Base Model Performance
Illustrious XL remains a "base model for additional fine-tuning," similar to non-instruction-tuned large language models. Almost every model we actually see in production are instruction tuned/ or 'finetuned' variants. This is because, freshly pretrained model, does not mean it will generate good / preferred results. Almost all models go through aesthetic tuning stage for preference optimizations, but aesthetic tuning can significantly reduce the model's "additional training capability". Many fine-tuned aesthetic models perform well visually but are problematic to train with.
Aesthetic models, or wrongly trained models are a disaster to train with - this was the fundamental reason why Illustrious XL was built. We wanted the model to start training with. However, aesthetic models do look better, no matter what - even if it's just simply merged with LoRA or other models.
Aesthetic Tuning and Performance Impact
We introduce the aesthetic-tuned variant of Illustrious XL v2.0—v2.0 Aesthetic. This model balances generalization and aesthetic refinement while maintaining compatibility with v0.1~v2.0-trained LoRAs.
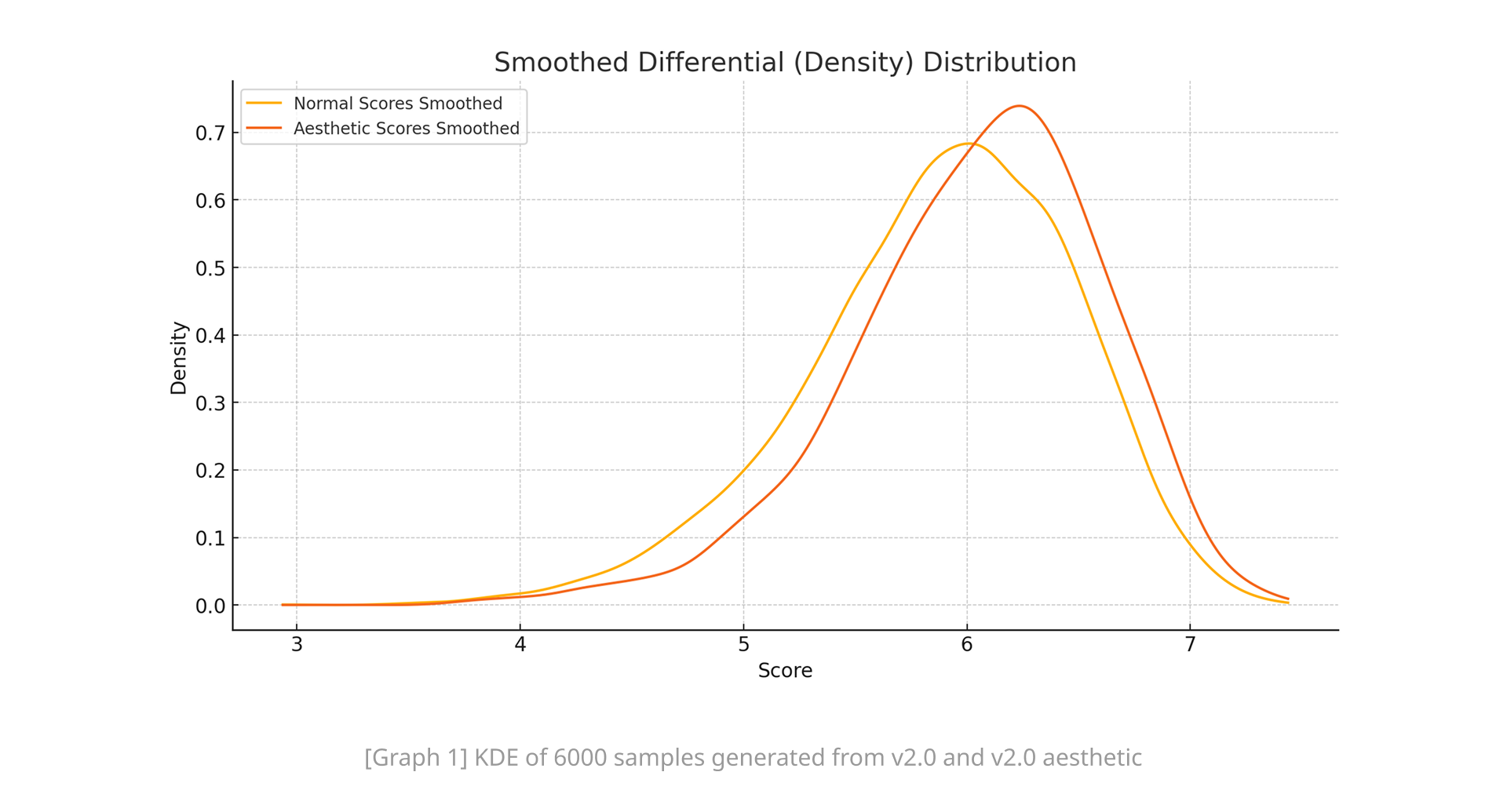
Aesthetic tuning enhances the model's ability to generate visually appealing images, as shown in automated model evaluations. The Kernel Density Estimation (KDE) plot highlights v2.0 Aesthetic's focus on "score optimization" across a sample of 6,000+ images.
However, due to aesthetic tuning, the training may not go well on aesthetic models. We strongly recommend using v2-base as the starting model for training rather than aesthetic-tuned variants. Here, we would like to emphasize again, aesthetic models are really hard to train. Good luck with them.


V2.0 Aesthetic Generated Image Examples
Finally, we present examples of LoRA generations compatible with v2.0+ models.





The "controllable" feature allows cool stuff, such as "2girls, standing, side-by-side, crazy mita (miside),yuitsuka inori, lora:new_chars:1, smiling, masterpiece, pixel art, masterpiece".
The academic details of LoRA training methodology will be officially disclosed soon. Stay tuned!