
Illustrious XL v2.0:1536分辨率时代最佳的训练基础模型
简介
Illustrious XL 1.0-2.0系列旨在稳定1536分辨率的原生生成,同时显著提高自然语言理解能力。
虽然用户有时会观察到在1024x1536分辨率下能成功生成,但这些并不稳定。同样,512x512分辨率的生成偶尔也会产生不必要的伪影。
早期版本为何不稳定?
这些不一致的根本原因很简单:模型未在这些分辨率上进行有效泛化或训练。使用小数据集填补这些空白往往会导致在某些分辨率上过拟合。这意味着模型会将特定分辨率与特定概念关联起来,使其在多样化生成时变得不可靠。
一个有用的比喻是"广角效果"。如果数据集通常包含广角镜头,当给定广角分辨率时,模型自然会生成更小的人物,因为这是它学习泛化的方式。
为了解决这个问题,Illustrious XL v2.0需要大规模数据集和大规模训练——与原始v0.1训练相当——以消除各分辨率和数据集之间的偏差。
 prompt: "stylish, no humans, city light, black theme, dim lighting, high contrast, night sky, masterpiece, absurdres, depth of field, butterflies, extremely aesthetic, absurdres, wallpaper, panorama, city background, neon, milky way, photo background, 512x512 generation"
prompt: "stylish, no humans, city light, black theme, dim lighting, high contrast, night sky, masterpiece, absurdres, depth of field, butterflies, extremely aesthetic, absurdres, wallpaper, panorama, city background, neon, milky way, photo background, 512x512 generation"
 "prompt: "The image features two characters,each with distinct black and white outfits,standing back-to-back. The character on the left wears a white coat with black accents,black pants,and boots,and is chained at the wrists and ankles. The character on the right is dressed in a black coat with white accents,black pants,and boots,also chained at the wrists and ankles. Both characters have spiked black hair and wield large key-shaped weapons. The background is white,and the text "Wielder Of The Key" and "Controls Light & Darkness" is displayed above and below the characters,respectively" Negative prompt: "worst quality, low quality, lowres, low details, bad quality, poorly drawn, bad anatomy, multiple views, bad hands, blurry, artist sign" Steps: 28, Sampler: Euler a, Schedule type: Automatic, CFG scale: 7.5, Seed: 3420215296, Size: 1248x1824*
"prompt: "The image features two characters,each with distinct black and white outfits,standing back-to-back. The character on the left wears a white coat with black accents,black pants,and boots,and is chained at the wrists and ankles. The character on the right is dressed in a black coat with white accents,black pants,and boots,also chained at the wrists and ankles. Both characters have spiked black hair and wield large key-shaped weapons. The background is white,and the text "Wielder Of The Key" and "Controls Light & Darkness" is displayed above and below the characters,respectively" Negative prompt: "worst quality, low quality, lowres, low details, bad quality, poorly drawn, bad anatomy, multiple views, bad hands, blurry, artist sign" Steps: 28, Sampler: Euler a, Schedule type: Automatic, CFG scale: 7.5, Seed: 3420215296, Size: 1248x1824*
 prompt: "Generate a highly detailed anime-style illustration of a young man floating serenely above a sprawling, futuristic cityscape. The boy has dark, messy hair and piercing blue eyes. He's wearing a long, flowing white coat over dark, streamlined clothing – think a mix of traditional Japanese garments and futuristic techwear. His expression is calm and confident, almost detached. He is surrounded by a faint, glowing aura of light, possibly blue or white. Below him is a vast sci-fi city, filled with towering skyscrapers, holographic advertisements, and flying vehicles. The city should have a vibrant color palette – neon blues, purples, and pinks contrasting with darker metallic structures. There should be a sense of depth and scale, with buildings receding into the distance. The overall atmosphere should be epic and awe-inspiring, suggesting a powerful and mysterious character overlooking a technologically advanced world. Focus on dynamic lighting and detailed textures to create a visually stunning image. wlop, quasarcake, masterpiece"
prompt: "Generate a highly detailed anime-style illustration of a young man floating serenely above a sprawling, futuristic cityscape. The boy has dark, messy hair and piercing blue eyes. He's wearing a long, flowing white coat over dark, streamlined clothing – think a mix of traditional Japanese garments and futuristic techwear. His expression is calm and confident, almost detached. He is surrounded by a faint, glowing aura of light, possibly blue or white. Below him is a vast sci-fi city, filled with towering skyscrapers, holographic advertisements, and flying vehicles. The city should have a vibrant color palette – neon blues, purples, and pinks contrasting with darker metallic structures. There should be a sense of depth and scale, with buildings receding into the distance. The overall atmosphere should be epic and awe-inspiring, suggesting a powerful and mysterious character overlooking a technologically advanced world. Focus on dynamic lighting and detailed textures to create a visually stunning image. wlop, quasarcake, masterpiece"
与其他模型的基准比较
目标很简单:实现对自然语言的强健理解,同时支持高分辨率。希望Illustrious v2及以上版本能达到一定程度——与现有模型相比。将Illustrious XL v2.0与NoobAI-XL和Animagine XL 4.0进行比较,突显了在提示词符合度、风格保留和细节生成方面的关键改进。

然而,仅仅遵循提示还不够。看看FLUX Schnell的结果。它在提示词符合度方面表现良好,但缺乏表现力质量和风格。我们的目标是,更好的提示词符合度(对齐)以及与插画相关的功能。不仅仅是美学,也不仅仅是单纯的计算能力。

指令调整与基础模型性能
Illustrious XL仍然是一个"可进一步微调的基础模型",类似于未经指令调整的大型语言模型。我们在生产中看到的几乎每个模型都是经过指令调整/或"微调"的变体。这是因为,刚预训练好的模型并不意味着它会生成好的/首选的结果。几乎所有模型都经历美学调整阶段以进行偏好优化,但美学调整可能显著降低模型的"额外训练能力"。许多经过微调的美学模型在视觉上表现良好,但在训练时会出现问题。
美学模型或错误训练的模型对训练是灾难性的——这是Illustrious XL构建的基本原因。我们希望模型能开始训练。然而,无论如何,美学模型看起来都更好——即使只是简单地与LoRA或其他模型合并。
美学调整与性能影响
我们推出了Illustrious XL v2.0的美学调整变体——v2.0 Aesthetic。该模型在保持与v0.1~v2.0训练的LoRA兼容的同时,平衡了泛化和美学优化。
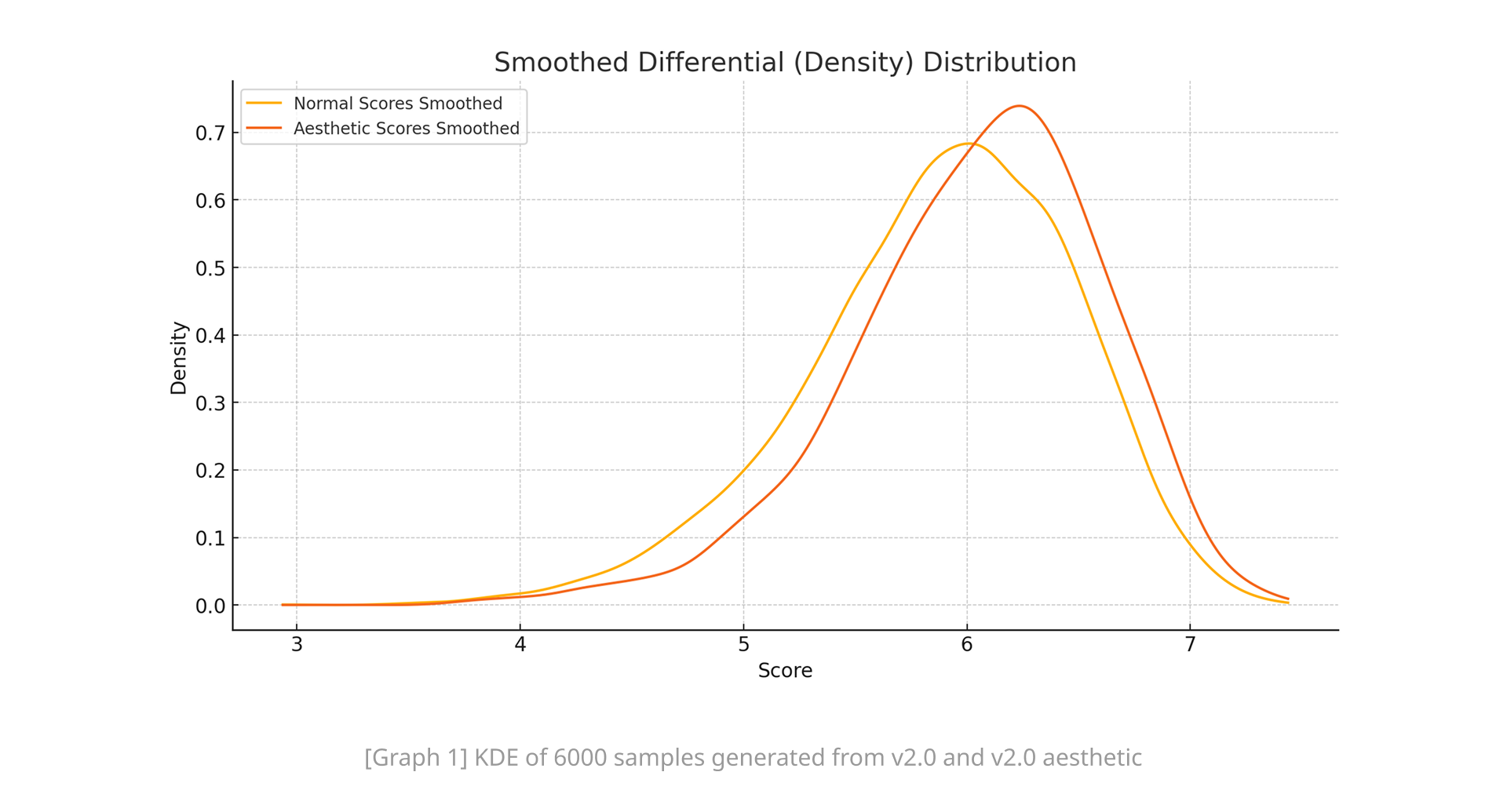
美学调整增强了模型生成赏心悦目的图像的能力,如自动模型评估所示。核密度估计(KDE)图突显了v2.0 Aesthetic在6,000多张图像样本中对"分数优化"的关注。
然而,由于美学调整,训练可能在美学模型上进展不顺利。**我们强烈建议使用v2-base作为训练起点,而不是美学调整变体。**在此,我们再次强调,美学模型确实很难训练。祝你好运。


V2.0 Aesthetic生成图像示例
最后,我们展示了与v2.0+模型兼容的LoRA生成示例。





"可控"功能允许酷炫效果,例如"2girls, standing, side-by-side, crazy mita (miside),yuitsuka inori, lora:new_chars:1, smiling, masterpiece, pixel art, masterpiece"。
LoRA训练方法的学术细节将很快正式公布。敬请期待!