CatV2TON利用扩散Transformer实现虚拟试穿|Janus-Pro多模态理解与生成|Qwen2.5-1M扩展输入上限【AI周报】
CatV2TON利用扩散Transformer实现虚拟试穿|Janus-Pro多模态理解与生成|Qwen2.5-1M扩展输入上限【AI周报】

摘要
本周亮点:CatV2TON利用DiT统一视频虚拟试穿;Janus-Pro增强多模态理解生成;Baichuan-Omni-1.5开源全模态模型;Qwen2.5-1M突破128K长文本生成;AtlaAI提出小型语言模型评估器。详情见正文。
目录
- CatV2TON:利用扩散Transformer实现视频虚拟试穿
- Janus-Pro:统一的多模态理解与生成模型
- Baichuan-Omni-1.5:百川最新开源多语言多模态模型
- Qwen2.5-1M:阿里巴巴推出的最新长上下文大语言模型
- Atla Selene Mini:通用评估模型
- OpenAI发布o3-mini模型:提升推理性能
- Animagine XL 4.0:终极动漫主题微调 SDXL 模型
CatV2TON:利用扩散Transformer实现视频虚拟试穿
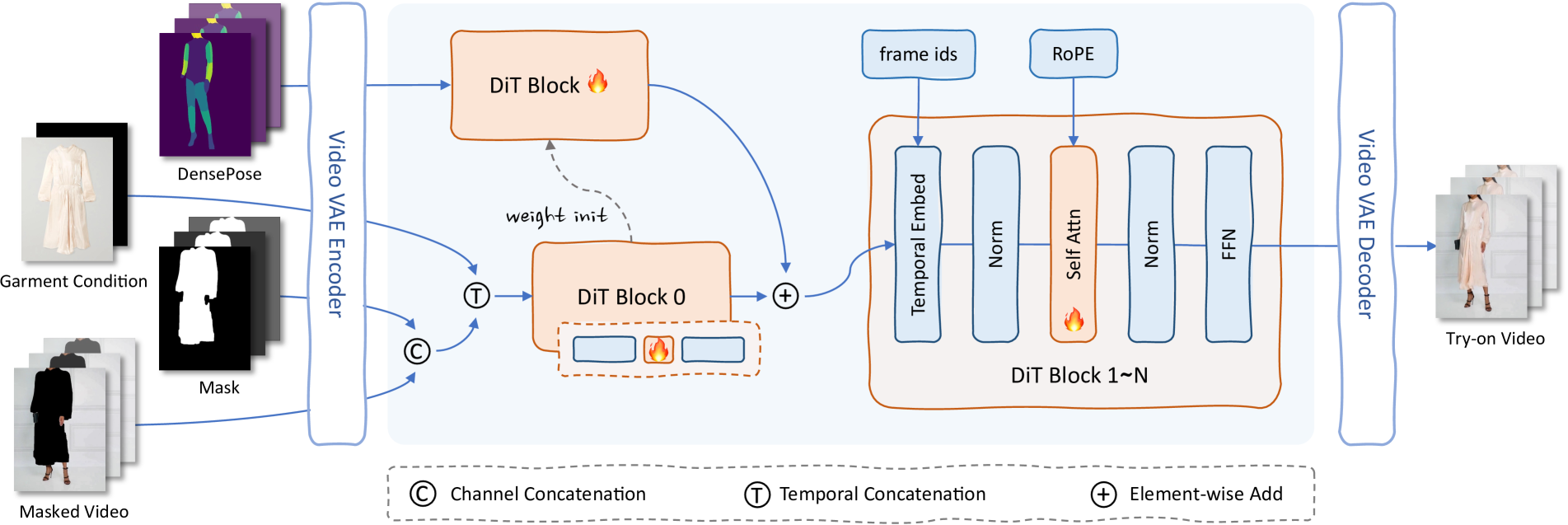
概要:CatV2TON 是一项针对虚拟试穿(Virtual Try-On,VTON)的新研究,提出了一种统一的图像和视频试穿方法。该方法采用DiT(扩散Transformer)架构,通过时间串联技术,确保服装在图像和视频试穿中的一致性。实验结果表明,CatV2TON在图像和视频试穿任务中均优于现有方法,提供了一个多功能且可靠的解决方案。
标签:#CatV2TON #虚拟试穿 #DiT #计算机视觉
Janus-Pro:统一的多模态理解与生成模型

概要:Janus-Pro 是 DeepSeek-AI 推出的 Janus 模型的增强版本,旨在统一多模态理解与生成。该模型通过优化训练策略、扩展训练数据以及扩大模型规模,在多模态理解和文本到图像的指令跟随能力上取得了显著提升,同时增强了图像生成的稳定性。
标签:#JanusPro #多模态 #DeepSeek #图像生成
Baichuan-Omni-1.5:百川最新开源多语言多模态模型

概要:Baichuan-Omni-1.5 是由 百川智能科技 推出的开源 7B 全模态大模型,支持处理文本、图像、视频和音频等多种模态输入,并能够生成高质量的文本和语音输出。 该模型基于 Qwen2.5-7B 语言模型构建,采用了高质量的多模态预训练数据和多阶段训练策略,以实现各模态间的有效协同。 在多模态医疗基准测试中,Baichuan-Omni-1.5 的表现与领先模型相当,展示了其在多模态理解和生成任务中的强大能力。
标签:#Baichuan-Omni-1.5 #多模态 #大语言模型 #百川智能
Qwen2.5-1M:阿里巴巴推出的最新长上下文大语言模型

概要:Qwen2.5 是 阿里巴巴集团 旗下 Qwen 团队 最新发布的大语言模型系列。该模型在最新的大规模数据集上进行了预训练,包含多达 18 万亿个 tokens。相较于之前的版本,Qwen2.5 在知识掌握、编程能力和数学能力方面有了显著提升。此外,模型在指令执行、长文本生成(支持最长 128K tokens)、结构化数据理解(如表格)以及生成结构化输出(特别是 JSON)方面表现出色。Qwen2.5 提供从 5 亿到 720 亿参数的多种模型规模,适用于不同的应用场景。
标签:#Qwen2.5 #阿里巴巴 #LLM #输入扩展
Atla Selene Mini:通用评估模型
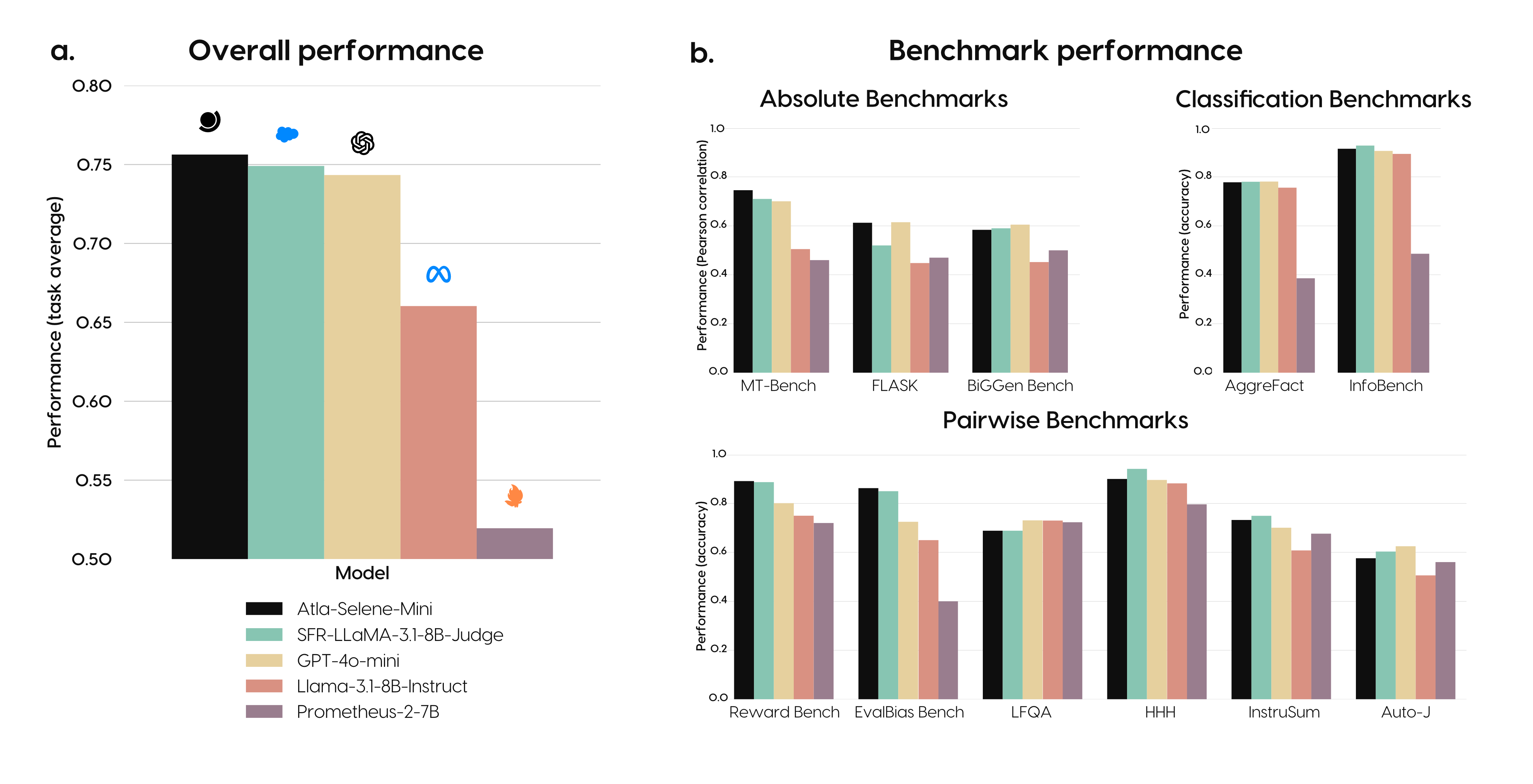
概要:Atla Selene Mini 是由 Atla AI 推出的最先进的小型语言模型评估器(SLMJ)。该模型在11个分布外基准测试中表现出色,超越了其他SLMJ和GPT-4o-mini,涵盖了绝对评分、分类和成对偏好任务。在RewardBench上,Selene Mini成为得分最高的8B生成模型,超过了GPT-4o等强大基线模型。通过引入合成批评数据并进行严格的数据过滤,Selene Mini在金融和医疗等行业数据集上与人类专家评估的零样本一致性显著提高。此外,该模型对提示格式的变化具有鲁棒性,并在社区驱动的评估竞技场中排名第一。模型权重已在HuggingFace和Ollama上发布,鼓励广泛的社区采用。
标签:#AtlaSeleneMini #SLMJ #模型评估 #GPT-4o #AtlaAI
OpenAI发布o3-mini模型:提升推理性能

概要:OpenAI推出了最新的推理模型o3-mini,该模型在科学、数学和编程等STEM领域表现出色。o3-mini在保持低成本和低延迟的同时,提供了更快且更准确的响应。它已集成到ChatGPT及其API服务中,免费用户也可有限制地访问。此外,OpenAI还提供了性能更高的o3-mini-high版本,专为付费用户设计,特别适用于编码任务。
标签:#OpenAI #o3-mini #推理模型 #STEM #ChatGPT
Animagine XL 4.0:终极动漫主题微调 SDXL 模型

概要:Animagine XL 4.0 是由 Cagliostro Research Lab 研发的动漫主题专用生成模型。作为 Animagine 系列最新迭代,该模型基于 Stable Diffusion XL 1.0 架构,通过 840 万张精选动漫图像数据集进行深度微调(耗时 2650 GPU 小时)。其创新性采用标签排序训练法,实现了对角色特征与艺术风格的精准控制,支持中日英多语言 prompt 输入,可生成从 1024x1024 到 2048x2048 的高清动漫图像。与同类模型相比,Animagine XL 4.0 在角色细节还原度(如服饰/五官刻画)和多角色协同生成方面表现突出,已集成至 Hugging Face Spaces、ComfyUI 和 Diffusers 等主流生成框架。
标签:#动漫生成 #SDXL优化 #多语言模型 #高分辨率生成 #Diffusers