DesignLab重构设计协作流程 | Step‑Audio 2实现语音理解与对话统一 | PUSA V1.0低成本生成高质视频【AI周报】
DesignLab重构设计协作流程 | Step‑Audio 2实现语音理解与对话统一 | PUSA V1.0低成本生成高质视频【AI周报】

摘要
本周亮点:DesignLab 引入多角色迭代机制,革新幻灯片设计流程;Step‑Audio 2 集成语音识别与语义理解,构建端到端音频大语言模型;PUSA V1.0 以 $500 成本实现超高质图像/文本驱动视频生成,打破算力门槛。详见正文,相关参考链接请见文末。
目录
- No Humans Required:自动生成高质量图像编辑三元组数据集
- DesignLab:迭代式幻灯片设计优化框架
- CSD‑VAR:视觉自回归模型中的内容与风格解耦框架
- Yume:从图像构建可探索动态世界
- Step‑Audio 2:端到端音频大语言模型,实现行业级理解与对话能力
- PUSA V1.0:低成本高性能图像/文字驱动视频生成模型
No Humans Required:自动生成高质量图像编辑三元组数据集
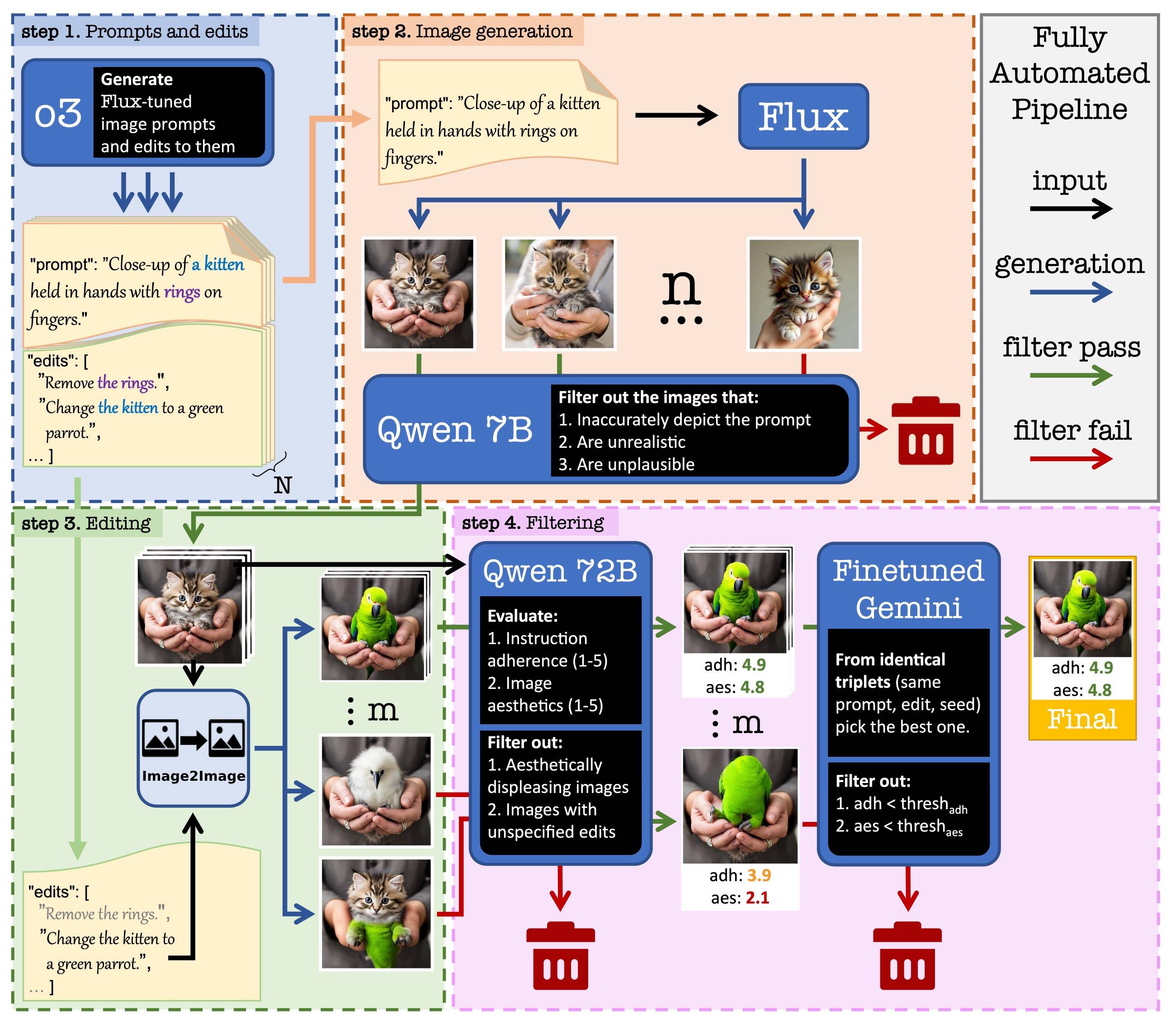
概要:SALUTEDEV 团队开发了一套无需人工参与的图像编辑数据构建流程No Humans Required 。通过自动采样自然图像、生成对应编辑指令与处理后结果,完成了极高保真度的 NHR‑Edit 数据集构建,含达 35.8 万组三元组信息。该数据广泛适用于训练指令驱动的图像编辑模型,生成效果在多个 benchmarks 上已接近或超过人工标注数据模型,推动图像编辑任务的数据自动化发展。
标签:#图像编辑 #自动标签生成 #编辑三元组 #数据构建 #指令驱动
DesignLab:迭代式幻灯片设计优化框架

概要:DesignLab 是由 索尼 与 KAIST 团队联合提出的全新设计协作系统,首次将幻灯片设计流程拆解为“Reviewer 检测→Contributor 修正→循环反馈”的迭代机制,以模拟人类设计师的真实工作流。系统能自动识别布局、配色、排版等问题,并引导修正优化,显著提升非设计专业用户输出幻灯片的视觉一致性与专业度 。
标签:#幻灯片设计 #迭代优化 #人机协同 #视觉质量提升 #设计辅助
CSD‑VAR:视觉自回归模型中的内容与风格解耦框架

概要:CSD‑VAR 由 Qualcomm AI Research 和 MovianAI 研究团队提出,是首个在视觉自回归(VAR)架构中实现图像内容与风格分离的方法。该方法采用尺度感知交替优化策略,将内容与风格分别绑定至不同尺度表示,引入 SVD 校正减少风格表征中的内容泄漏,并使用增强型键值记忆(Augmented K‑V Memory)机制强化内容一致性保存。研究还发布了针对该任务的 CSD‑100 数据集。实验结果表明,CSD‑VAR 在内容保留与风格迁移精度上均优于现有扩散基础方法,在艺术风格重构与内容迁移方面提供更高创作自由度。
标签:#内容风格分离 #视觉自回归 #尺度优化 #记忆机制 #风格迁移控制
Yume:从图像构建可探索动态世界

概要:Yume 项目由中科大联手港科大等团队提出,旨在基于输入的图像、文本或视频,自动生成一个高度真实、动态交互的虚拟世界。用户可以通过键盘控制甚至神经信号进行探索,系统架构包括带记忆模块的 Masked Video Diffusion Transformer(MVDT)、抗伪影采样器(AAM)、时间旅行扩散采样(TTS‑SDE)和世界运动量化模块,训练使用 Sekai 世界探索数据集。当前该预览模型支持实时世界导航探索,展示了从静态视觉内容到连续视频环境的创新路径。项目预计持续迭代更新,已提供 GitHub 和项目官网内容。
标签:#虚拟世界生成 #视频扩散 #记忆网络 #交互探索 #Sekai数据集
Step‑Audio 2:端到端音频大语言模型,实现行业级理解与对话能力

概要:Step‑Audio 2 是由 StepFun 团队开发的多模态大语言模型,可直接从原始音频输入理解语义与副语言信息,并生成连贯的文本与音频响应。模型通过隐向量音频编码器、强化学习(RL)与检索增强生成(RAG)机制,引入工具调用(如 Web 搜索、音频检索)实现对复杂任务的处理;系统支持语义理解、情感音调、方言风格等多维度控制,评测结果显示其在 ASR、多语种音频理解、工具调用以及语音对话任务上显著领先同类开源和商用模型。Step‑Audio 2 可用于真实语音代理、客服助手和智能对话系统。
标签:#音频大语言模型 #端到端对话 #强化学习 #工具调用 #多语言理解
PUSA V1.0:低成本高性能图像/文字驱动视频生成模型
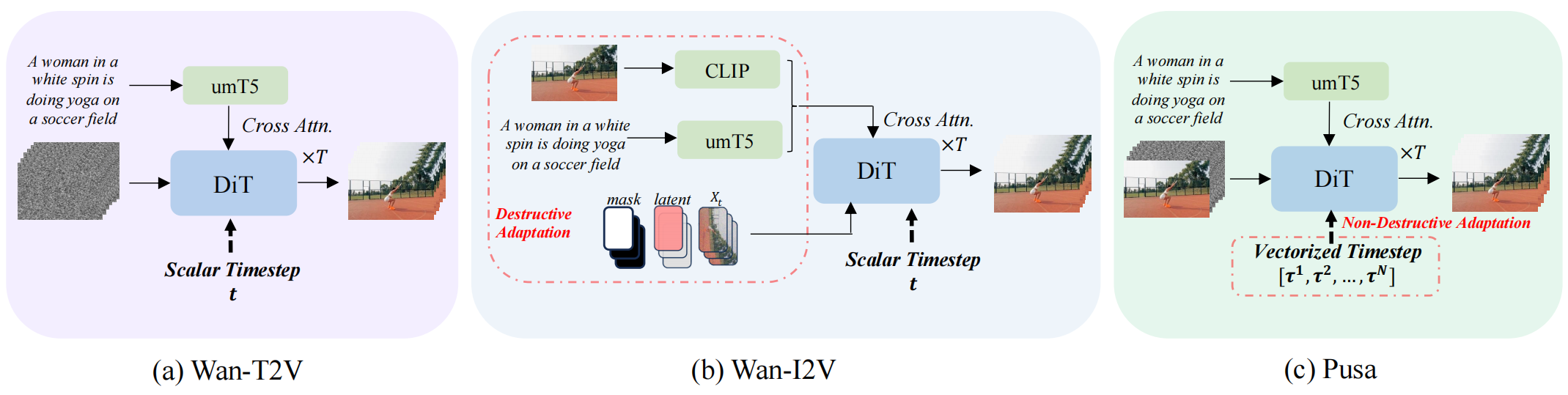
概要:Pusa V1.0 是由 港城大 和 华为 等团队联合提出的创新视频生成模型。该模型引入 Vectorized Timestep Adaptation(VTA) 技术,通过将 Wan‑T2V‑14B 基础模型的时步变量从标量扩展为矢量,实现每帧噪声控制的非破坏性微调。此方法仅使用约 4000 个训练样本、$500 训练成本,即可在 VBench‑I2V 上达到 87.32% 的评分,略优于需 100 K 美元与千万级样本训练的 Wan‑I2V‑14B(86.86%)。Pusa 同时支持文本到视频、图像到视频、关键帧控制与视频延展等多项任务,无需额外训练即可零-shot 扩展功能。该项目完整发布训练与推理脚本、LoRA 模型权重及数据集,极大降低高质量视频生成的研发门槛,是视频扩散领域的一项里程碑进展。
标签:#向量化时步控制 #视频扩散模型 #低资源训练 #多任务零 shot #高效生成