ColorizeDiffusion v2实现最强动漫草图上色 | RepText 多语言文本渲染 | Nexus-Gen 图像生成统一模型【AI周报】
ColorizeDiffusion v2实现最强动漫草图上色 | RepText 多语言文本渲染 | Nexus-Gen 图像生成统一模型【AI周报】

摘要
本周亮点:ColorizeDiffusion v2 提升动漫草图上色质量;RepText 实现多语言文本渲染;ICEdit 多视角保持身份一致性编辑;Insert Anything 灵活插入任意物体;Nexus-Gen 融合 LLM 与扩散模型统一生成流程;X-Fusion 实现多任务图文对齐能力。
目录
- ColorizeDiffusion v2:动漫草图上色的参考增强扩散模型
- RepText:多语言高保真视觉文本渲染框架
- ICEdit:高效指令图像编辑框架,支持零样本编辑与高质量输出
- Nexus-Gen:融合LLM与扩散模型的统一图像理解与生成框架
- Insert Anything:统一的参考图像插入框架,支持多种控制模式
- X-Fusion:冻结大语言模型的多模态扩展框架
ColorizeDiffusion v2:动漫草图上色的参考增强扩散模型

概要:ColorizeDiffusion v2 是由 东京工业大学 与 东京大学 联合提出的参考图像驱动草图上色框架,专为动漫风格设计。该方法引入分离式注意力机制,结合背景与风格编码器,提升对参考图像的空间适应性与细节还原能力。通过前景遮罩与背景漂白等预处理步骤,有效缓解训练与推理阶段的分布偏移问题,显著提升上色质量与稳定性。
标签:#草图上色 #参考图像生成 #扩散模型 #动漫风格 #前后景分离
RepText:多语言高保真视觉文本渲染框架
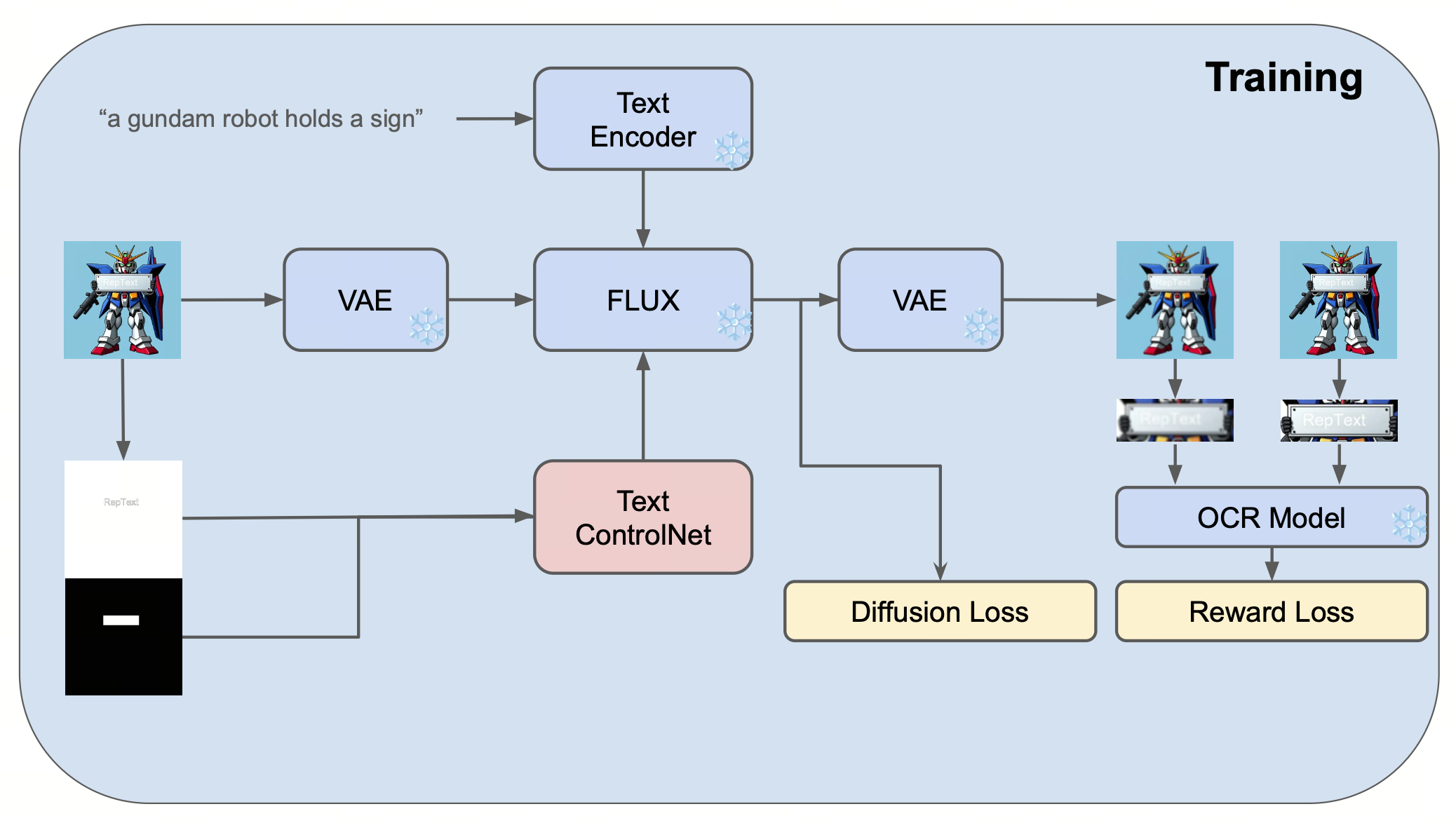
概要:RepText 是由 Shakker Labs 与 Liblib AI 提出的多语言视觉文本渲染方法,受书法临摹启发,创新性地采用"复制"而非"理解"范式。该方法无需理解文本语义,通过字形复制策略(Glyph latent copy)实现对60+语言的支持。技术上结合 ControlNet 架构处理 Canny 边缘与位置信息,推理阶段采用无噪声 glyph latent 替换文本区域的初始噪声,提供准确的结构和颜色指导。创新的区域掩码(Region mask)机制限定控制信号仅影响文本区域,保护背景质量,同时集成 OCR 感知损失提升可读性。模型设计保持高生态兼容性,可与 LoRA、IP-Adapter 等插件无缝结合,为广告设计、UI展示等应用场景提供灵活且低成本的文本渲染解决方案。
标签:#视觉文本渲染 #多语言文本 #文本控制 #字形复制 #ControlNet
ICEdit:高效指令图像编辑框架,支持零样本编辑与高质量输出

概要:ICEdit 是由 浙江大学 与 哈佛大学 联合提出的高效指令图像编辑框架,借鉴语言模型的 in-context learning 思想设计"IC Prompt"结构,实现零样本编辑能力。该方法基于大规模 Diffusion Transformer(DiT),引入三项关键技术:一是将原图与编辑指令并列输入的 in-context 编辑框架,无需结构改动即可理解复杂指令;二是结合 LoRA 与 MoE 的混合微调架构,通过动态路由激活不同编辑专家,在保持参数效率的同时提升多样编辑能力;三是推理阶段的 Early Filter 策略,利用视觉语言模型(VLM)筛选最优初始噪声,提升编辑一致性。
标签:#图像编辑 #VLM #零样本学习 #高效微调 #DiT
Nexus-Gen:融合LLM与扩散模型的统一图像理解与生成框架

概要:Nexus-Gen 是由 ModelScope 团队 发布的统一多模态模型,结合了大语言模型(LLM)的语言推理能力与扩散模型的图像生成能力,支持图像理解、生成与编辑等任务。该模型采用双阶段对齐训练策略:首先,LLM在多模态输入条件下预测图像嵌入;其次,视觉解码器从这些嵌入中重建高保真图像。为解决自回归训练与推理阶段的误差积累问题,Nexus-Gen 引入了预填充自回归策略,使用位置嵌入的特殊标记替代连续嵌入,提升生成质量。该模型在多种图像任务中表现出色,展示了强大的多模态理解与生成能力。
标签:#多模态生成 #图像理解 #扩散模型 #大语言模型 #统一框架
Insert Anything:统一的参考图像插入框架,支持多种控制模式

概要:Insert Anything 是由 浙江大学 等机构提出的统一图像插入框架,支持基于参考图像的对象、人物和服饰插入任务。该方法引入了包含12万对图像-提示对的 AnyInsertion 数据集,涵盖多种插入场景。模型基于 Diffusion Transformer(DiT)架构,结合多模态注意力机制,支持掩码和文本两种控制模式。通过创新的“in-context editing”机制,模型能够在保持插入元素特征的同时,实现与目标图像的自然融合。实验结果显示,Insert Anything 在多个基准测试中表现优异,适用于创意内容生成、虚拟试穿和场景合成等应用。
标签:#图像插入 #多模态编辑 #DiT #参考图像编辑 #虚拟试穿
X-Fusion:冻结大语言模型的多模态扩展框架

概要:X-Fusion 是由 Adobe Research 联合 UCLA 提出的多模态扩展框架,旨在在不微调大语言模型(LLM)参数的前提下,增强其视觉理解与生成能力。该方法采用双塔架构,分别处理语言和视觉信息,通过引入视觉特定的权重,实现图像到文本和文本到图像的双向任务。实验表明,X-Fusion 在多个基准测试中表现优异,尤其在图像生成质量和文本描述准确性方面,优于现有的多模态模型。
标签:#多模态学习 #冻结LLM #图像生成 #文本描述 #双塔架构