OmniCaptioner统一视觉描述 | UNO多主体定制 | SPF-Portrait消除污染提升肖像定制【AI周报】
OmniCaptioner统一视觉描述 | UNO多主体定制 | SPF-Portrait消除污染提升肖像定制【AI周报】

摘要
本周亮点:OmniCaptioner实现跨视觉域语言描述;UNO统一个性化定制多主体生成;SPF-Portrait解决语义污染;FantasyTalking生成音频驱动数字人;SmolVLM2发布轻量级视频理解模型。其余详见正文。
目录
- OmniCaptioner:统一多视觉域描述生成的创新框架
- UNO:统一多主体个性化定制方法
- OmniSVG:端到端多模态矢量图生成模型
- VisualCloze:统一图像生成任务的视觉上下文学习框架
- SPF-Portrait:消除语义污染的肖像定制微调方法
- FantasyTalking:音频驱动的高保真数字人生成框架
- SmolVLM2:轻量级视频理解模型,适配多设备部署
OmniCaptioner:统一多视觉域描述生成的创新框架
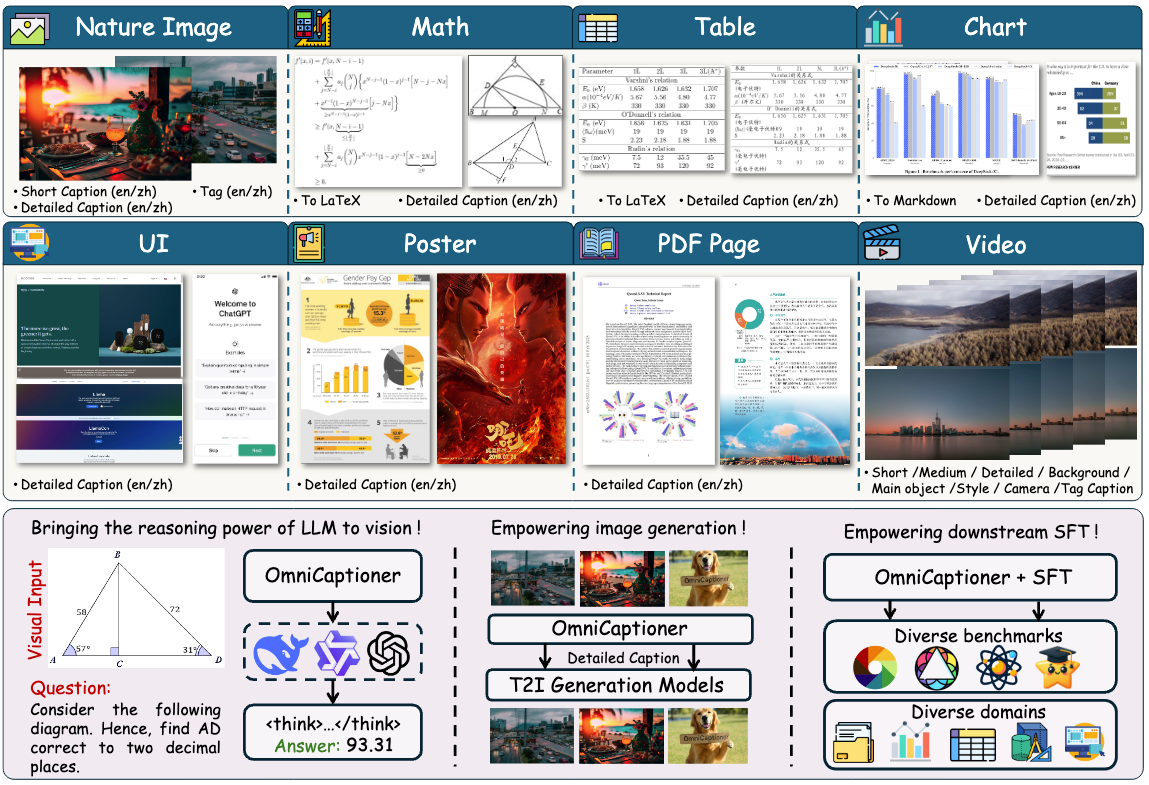
概要:OmniCaptioner 是由 上海人工智能实验室、复旦大学、中国科技大学 等机构提出的创新视觉描述生成框架,旨在统一处理自然图像、结构化图像(如表格、图表)和视觉文本图像(如UI、海报)等多种视觉域。其训练流程包括构建多样化的描述数据集,采用两阶段的描述生成流程(初始描述生成与扩展),并通过统一的预训练机制提升跨领域的视觉理解能力。在推理阶段,OmniCaptioner 首先将图像转化为语义结构化的语言描述,然后利用大语言模型(如 DeepSeek-R1、Qwen2.5)进行任务无关的语言推理,实现感知与推理的解耦,增强了模型的泛化性和适用性。
标签:#视觉描述生成 #多视觉域 #统一预训练 #语言推理 #多模态理解
UNO:统一多主体个性化定制方法

概要:UNO 是由 字节跳动智能创作团队 提出的一种统一个性化定制方法,旨在解决现有图像生成中单一主体定制的局限性。UNO 引入了渐进式跨模态对齐(Progressive Cross-Modal Alignment)和通用旋转位置编码(Universal Rotary Position Embedding, UnoPE),通过两阶段训练流程,从单主体到多主体逐步扩展,提升了模型在多主体生成任务中的一致性和可控性。实验结果表明,UNO 在保持高一致性的同时,实现了从单主体到多主体的统一定制能力。
标签:#图像生成 #个性化定制 #多主体生成 #跨模态对齐 #位置编码
OmniSVG:端到端多模态矢量图生成模型
概要:OmniSVG 是由 复旦大学 与 阶跃星辰(StepFun) 联合提出的端到端多模态 SVG 生成模型,支持从简单图标到复杂动漫角色的高质量矢量图生成。该模型基于预训练视觉语言模型 Qwen2.5-VL,并集成了 SVG 标记化器,将文本和图像输入标记为前缀标记,同时将 SVG 命令和坐标参数化为离散标记,从而解耦结构逻辑与底层几何,实现高效训练和生成。OmniSVG 支持三种生成模式:文本生成 SVG、图像转 SVG、角色参考 SVG 生成。为支持训练,研究团队构建了包含两百万个带注释 SVG 的多模态数据集 MMSVG-2M,并制定了标准化评估协议。实验结果表明,OmniSVG 在生成质量和多样性方面优于现有方法,展示了其在专业 SVG 设计工作流程中的集成潜力。
标签:#SVG生成 #多模态学习 #视觉语言模型 #矢量图形 #图像生成
VisualCloze:统一图像生成任务的视觉上下文学习框架
概要:VisualCloze 是由 南开大学、上海人工智能实验室、北京邮电大学 等机构提出的一种通用图像生成框架,旨在通过视觉上下文学习(Visual In-Context Learning)实现多任务统一与泛化。该方法通过“视觉示例”而非语言指令引导模型理解任务,避免了语言歧义问题,并提升泛化能力。研究团队构建了图结构数据集 Graph200K,涵盖多种任务形式,增强任务密度与可迁移性。VisualCloze 基于图像填充模型 FLUX.1,无需修改架构即可支持统一建模与反向生成,展示了在未见任务上的强泛化能力。
标签:#图像生成 #视觉上下文学习 #多任务泛化 #图结构数据 #视觉指令学习
SPF-Portrait:消除语义污染的肖像定制微调方法

概要:SPF-Portrait 是由 深圳大学、清华大学与快手 KwaiVGI 联合提出的一种创新方法,旨在解决文本驱动肖像定制中常见的语义污染问题。该方法引入了双路径对比学习框架,将原始模型作为参考路径,通过对比学习确保目标属性的适应性,同时保持其他无关属性与原始肖像的一致性。此外,SPF-Portrait 设计了语义感知精细控制图,以空间方式指导对比路径之间的对齐过程,有效保留原模型性能,避免过度对齐。实验结果表明,SPF-Portrait 在实现目标属性定制的同时,显著减少了语义污染,提升了模型的泛化能力和稳定性。
标签:#肖像定制 #语义污染 #对比学习 #图像生成 #模型微调
FantasyTalking:音频驱动的高保真数字人生成框架
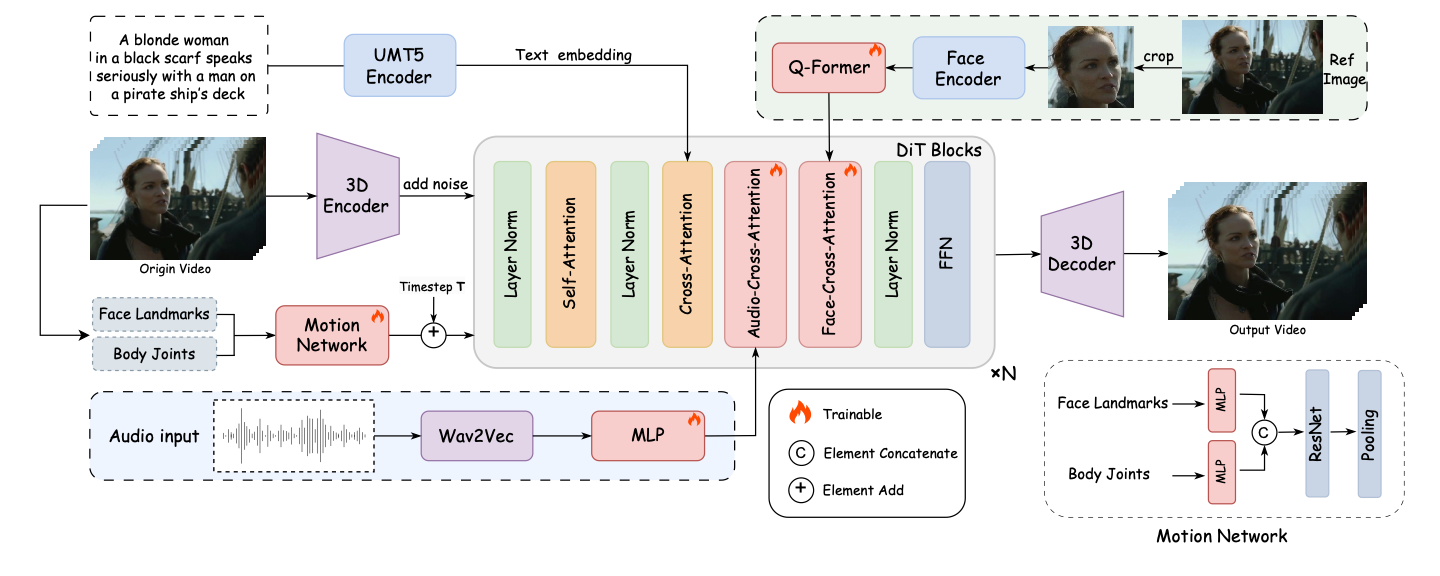
概要:FantasyTalking 是由 阿里巴巴 AMAP 团队 与 北京邮电大学 联合提出的数字人生成框架,基于预训练的视频扩散变换器模型。该方法采用双阶段音频-视觉对齐策略:第一阶段在剪辑级别对齐音频驱动的全局动态,包括参考肖像、上下文对象和背景;第二阶段使用唇部跟踪掩码在帧级别精细化唇部运动,确保与音频信号的精确同步。为保持身份一致性,框架引入面部专注的交叉注意力模块,有效维护视频中的面部特征一致性。此外,集成的运动强度调制模块允许对表情和身体动作强度进行显式控制,实现超越唇部运动的可控肖像动作生成。实验结果表明,FantasyTalking 在真实感、一致性、动作强度和身份保持方面表现优异。
标签:#数字人 #视频生成 #音频驱动 #身份保持 #动作控制
SmolVLM2:轻量级视频理解模型,适配多设备部署
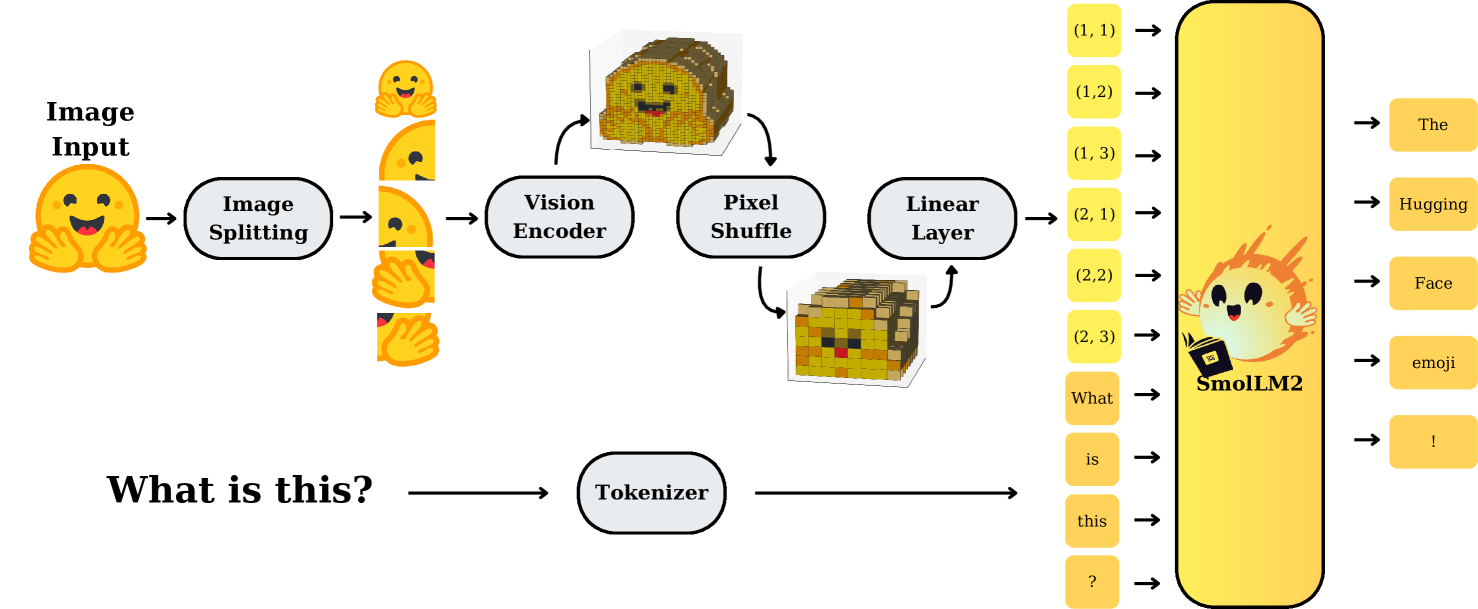
概要:SmolVLM2 是由 Hugging Face 推出的轻量级多模态模型,旨在实现高效的视频理解能力。该模型提供三种参数规模(2.2B、500M、256M),支持图像、视频和文本输入,输出文本结果。SmolVLM2 采用优化的视觉编码器和语言模型架构,能够在低资源设备上运行,适用于从手机到服务器的多种部署场景。实验结果显示,SmolVLM2 在保持较小模型规模的同时,具备强大的视觉理解能力,适合广泛的多模态应用。
标签:#视频理解 #多模态模型 #轻量级模型 #HuggingFace #SmolVLM2
参考链接
- OmniCaptioner 项目主页
- OmniCaptioner GitHub 仓库
- OmniCaptioner 论文链接
- UNO 项目主页
- UNO GitHub 仓库
- UNO 论文链接
- OmniSVG 项目主页
- OmniSVG GitHub 仓库
- OmniSVG 论文链接
- VisualCloze 项目主页
- VisualCloze GitHub 仓库
- VisualCloze 论文链接
- SPF-Portrait 项目主页
- SPF-Portrait GitHub 仓库
- SPF-Portrait 论文链接
- FantasyTalking 项目主页
- FantasyTalking GitHub 仓库
- SmolVLM2 模型集合
- SmolVLM2 GitHub 仓库
- SmolVLM2 论文链接