AniDoc简化动画上色||ChatDiT聊天解决图像编辑|GenEx生成3D视频【AI周报】
AniDoc简化动画上色||ChatDiT聊天解决图像编辑|GenEx生成3D视频【AI周报】

摘要
本周聚焦生成与编辑:AniDoc简化动画上色;ChatDiT聊天解决图像编辑;GenEx生成3D视频;DynamicControl加强图像生成控制,BrushEdit高效修复编辑图像。其余详见正文。
目录
- AniDoc:简化动画创作的高保真线稿上色工具
- ChatDiT:基于扩散变压器的零训练多任务聊天框架
- GenEx:从单张图像生成可探索的360°3D世界
- DynamicControl:提升文本到图像生成的条件适配能力
- LeviTor:基于3D轨迹的图像到视频合成
- BrushEdit:一体化图像修复与编辑工具
AniDoc:简化动画创作的高保真线稿上色工具

概要:AniDoc 是一款自动化的动画线稿上色算法,利用视频扩散模型将参考图像的色彩高保真地映射到输入线稿序列中。通过显式的对应匹配和两阶段训练策略,AniDoc 能处理不同姿势和比例的线稿,保持时序一致性,减少人工上色成本,提升动画制作效率。
标签:#动画上色 #扩散模型 #自动化工具 #时序一致性
ChatDiT:基于扩散变压器的零训练多任务聊天框架

概要:ChatDiT 是一个无需额外训练的通用交互式视觉生成框架,直接基于预训练的扩散变压器(DiTs)。它允许用户通过自然语言与系统进行多轮对话,生成图像或图文并茂的文章。ChatDiT 采用多代理系统,包括指令解析、策略规划和执行代理,以实现多任务的零样本生成。在 IDEA-Bench 基准测试中,ChatDiT 的表现优于专门设计并在大规模多任务数据集上训练的模型。
标签:#ChatDiT #扩散变压器 #零训练 #多任务生成 #视觉生成
GenEx:从单张图像生成可探索的360° 3D世界
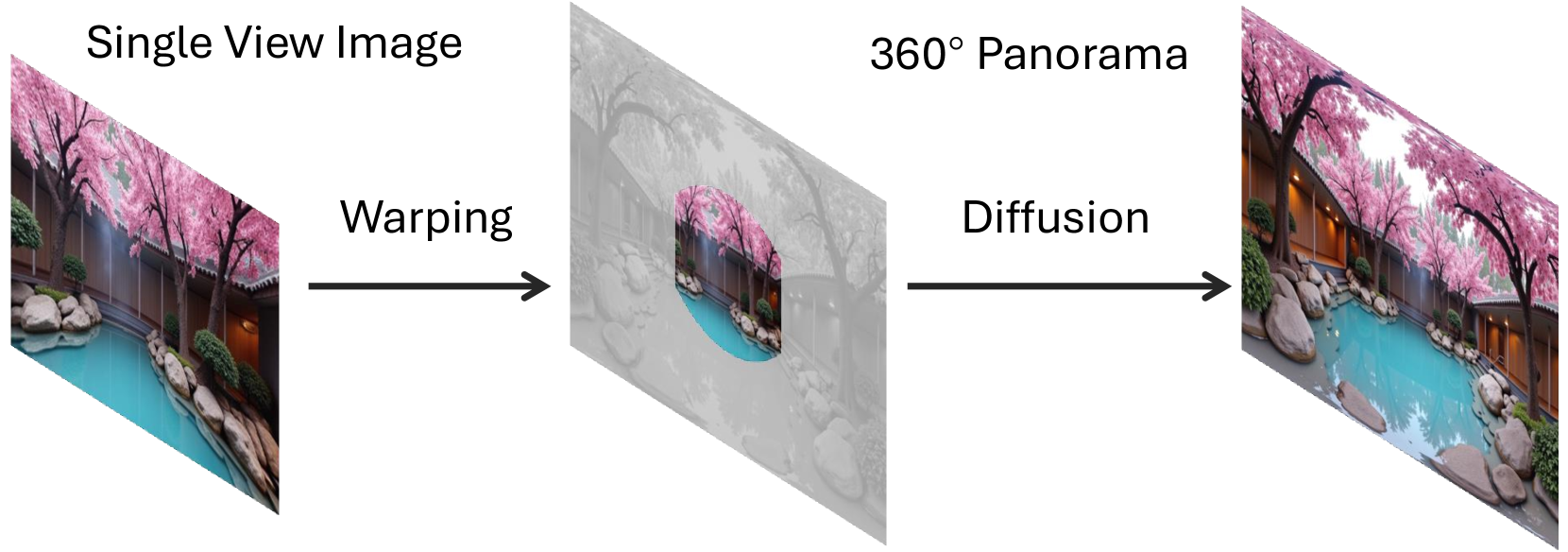
概要:GenEx 是一个 约翰霍普金斯大学 提出的开创性3D视频生成模型,可以从一张RGB图像生成一个完整的、可探索的3D虚拟世界。通过结合强大的生成模型与来自Unreal Engine的3D世界数据,GenEx能够为AI Agent提供丰富的互动空间,并能生成360度环视视频流。此模型不仅为虚拟环境提供了高质量的生成,还具备了高度的连贯性和空间一致性,使AI能够在动态环境中执行复杂的任务,包括无目标探索和目标导向导航。其独特之处在于,通过利用生成的世界预期,AI能够对未知部分进行推测并做出更智能的决策,推动了嵌入式AI在虚拟和现实世界中的探索能力。
标签:#生成模型 #3D世界 #虚拟环境 #AI探索 #机器人导航
DynamicControl:提升文本到图像生成的条件适配能力

概要:DynamicControl 提出了一个创新框架,旨在解决多条件控制信号在文本到图像生成中的冲突和效率问题。该方法通过双循环控制器评估输入条件的相似性,并结合多模态大语言模型优化条件排序,动态选择控制条件。最终,多个条件通过并行多控制适配器融合,提升了图像生成的可控性、质量和细节表现。此方法在各种条件控制下的表现优于现有技术。
标签:#文本到图像 #生成模型 #条件控制 #多模态 #Diffusion模型
LeviTor:基于3D轨迹的图像到视频合成
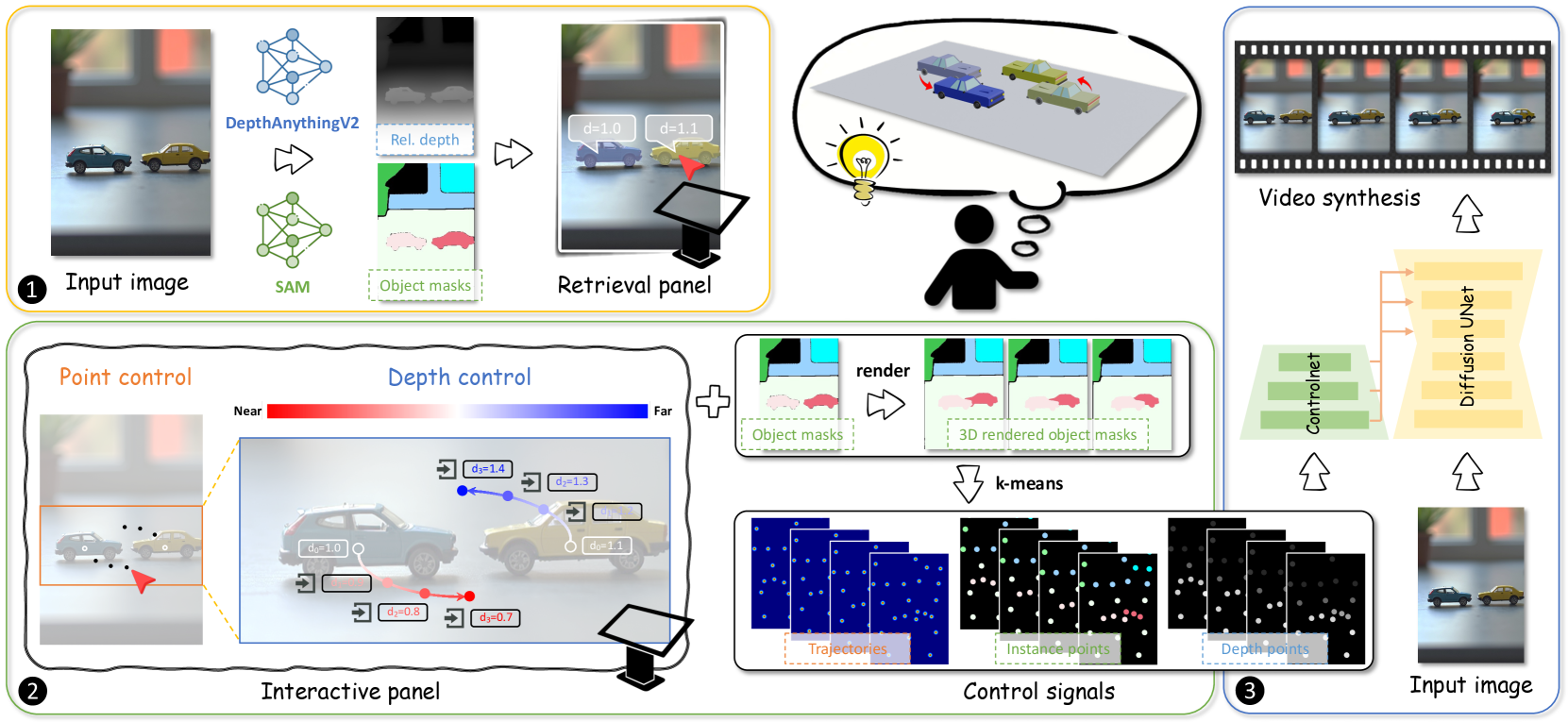
概要:LeviTor 提出了一个新方法,通过结合深度信息和实例信息,将图像中的物体轨迹扩展到3D空间。用户可通过拖动交互指定每个轨迹点的深度,极大提高了图像到视频合成的控制精度。该方法能够生成高度逼真的视频,允许精确控制物体的运动,包括复杂的轨迹和前后运动,是一种在视频生成领域的创新进展。
标签:#图像到视频 #3D轨迹 #深度控制 #视频合成
BrushEdit:一体化图像修复与编辑工具
 概要:BrushEdit 是一个创新的图像修复与编辑平台,结合了多模态大语言模型(MLLMs)与图像修复模型,支持用户通过指令进行自由形式的图像编辑。该系统解决了传统方法在对象添加、删除等重大修改上的限制,允许通过自动化与交互式方式精准控制编辑区域。其四步流程包括编辑分类、主要对象识别、编辑掩模生成和图像修复,最终实现高质量、连贯的图像编辑效果。
概要:BrushEdit 是一个创新的图像修复与编辑平台,结合了多模态大语言模型(MLLMs)与图像修复模型,支持用户通过指令进行自由形式的图像编辑。该系统解决了传统方法在对象添加、删除等重大修改上的限制,允许通过自动化与交互式方式精准控制编辑区域。其四步流程包括编辑分类、主要对象识别、编辑掩模生成和图像修复,最终实现高质量、连贯的图像编辑效果。
标签:#图像修复 #图像编辑 #自由形式编辑 #AI生成