Step-Video-T2V文本到视频生成|YOLOv12目标检测优化|WHAM游戏内容生成【AI周报】
Step-Video-T2V文本到视频生成|YOLOv12目标检测优化|WHAM游戏内容生成【AI周报】

摘要
本周亮点:Step-Video-T2V提升视频质量和一致性;YOLOv12在目标检测任务中提供更强推理能力和高精度;WHAM模型首次为游戏内容生成提供了创新性解决方案;Dynamic Concepts实现了跨模态的动态概念推理。详情见正文。
目录
- Step-Video-T2V:从文本到视频的先进生成模型
- YOLOv12:基于注意力机制的实时目标检测模型
- WHAM:基于视觉与动作的游戏场景生成模型
- Qwen2.5-VL:千问最新开源多模态大语言模型
- Phantom:跨模态对齐生成一致的主题视频
- Dynamic Concepts:单视频个性化生成动态概念
- ThinkDiff:为扩散模型赋能多模态推理的创新对齐框架
Step-Video-T2V:从文本到视频的先进生成模型

概要:Step-Video-T2V 是一个先进的文本到视频生成模型,旨在将文本描述转化为高质量的视频内容。该项目由中国的AI实验室开发,采用了创新的 变分自编码器(VAE) 和 Diffusion Transformer(DiT)技术,能够在较短的时间内生成高达 204帧 的视频。相比现有的同行模型,Step-Video-T2V 在运动一致性、物理合理性以及视频生成的自然流畅性上表现出色。尽管在视频的美学质量上存在一些差距,但该模型的创新性和高效性在行业中受到了广泛关注。
标签:#文本到视频 #视频生成 #VAE #DiT
YOLOv12:基于注意力机制的实时目标检测模型

概要:YOLOv12 是由国科大提出的结合了创新的注意力机制的目标检测框架。该模型不仅维持了 YOLO 系列的高速推理能力,还在检测精度上超越了许多现有的实时目标检测模型。例如,YOLOv12-N 在 T4 GPU 上的推理延迟仅为 1.64 毫秒,同时 mAP 达到了 40.6%,比 YOLOv10-N 和 YOLOv11-N 提升了 2.1% 和 1.2%。YOLOv12 在与改进版 DETR 模型的对比中展现了更快的速度和更低的计算资源消耗,使得其成为实时应用中的强大工具。
标签:#YOLOv12 #目标检测 #实时检测 #注意力机制
WHAM:基于视觉与动作的游戏场景生成模型

概要:WHAM(World and Human Action Model)是由微软研究院开发的一个生成性AI模型,旨在基于玩家的控制动作或视觉输入,自动生成动态的游戏环境和行为。通过与Ninja Theory(《Hellblade》开发团队)的合作,WHAM在7年《Bleeding Edge》游戏数据的基础上训练,能够生成高达2分钟的3D游戏序列,且保持一致的物理规则和角色行为。WHAM的亮点在于其只需1秒的输入,就能生成长达2分钟的游戏场景,支持开发者和设计师在没有复杂手动编程的情况下进行游戏内容创作。该模型已开源,提供了权重文件、演示工具以及样本数据,用户可以通过Azure AI Foundry和Hugging Face平台进行访问。
标签:#游戏生成 #WHAM #AI模型 #3D生成 #物理一致性
Qwen2.5-VL:千问最新开源多模态大语言模型
概要:Qwen2.5-VL 是阿里巴巴千问团队推出的一款强大的多模态大语言模型,旨在处理多种类型的输入(如文本、图像和视频),并通过生成与输入相对应的文本输出。该模型继承了 Qwen 系列的强大能力,使用了大规模的视觉-语言模型架构,具有图像和视频理解、文本生成和对话功能。Qwen2.5-VL 以其卓越的性能在多个评测任务中领先,特别是在 图像识别、视频理解 和 文档解析 等领域。它支持中文、英文及多语言的文本识别,并能够处理多图像的交互式问答和创意任务。与先前版本相比,Qwen2.5-VL 提供了更高分辨率的输入,并在多轮对话和多模态推理方面展现出强大的灵活性。
标签:#多模态 #Qwen2.5-VL #视觉语言模型 #图像理解 #视频理解
Phantom:跨模态对齐生成一致的主题视频

概要:Phantom 是一个创新的视频生成框架,旨在实现跨模态对齐和生成一致主题的视频。该项目由字节跳动(ByteDance)研究团队开发,采用了新的跨模态对齐技术,可以从单一或多个参考图像生成主题一致、动态自然的视频。Phantom能够保留参考图像中的身份特征,同时根据文本描述生成逼真的视频内容。特别地,Phantom还支持多人交互场景生成,适用于产品展示、虚拟试穿等应用。通过优化文本、图像与视频的对齐,Phantom突破了传统模型在视频生成中的局限,为多模态生成任务提供了新的可能。
标签:#跨模态对齐 #视频生成 #文本到视频 #图像到视频 #人物生成
Dynamic Concepts:单视频个性化生成动态概念
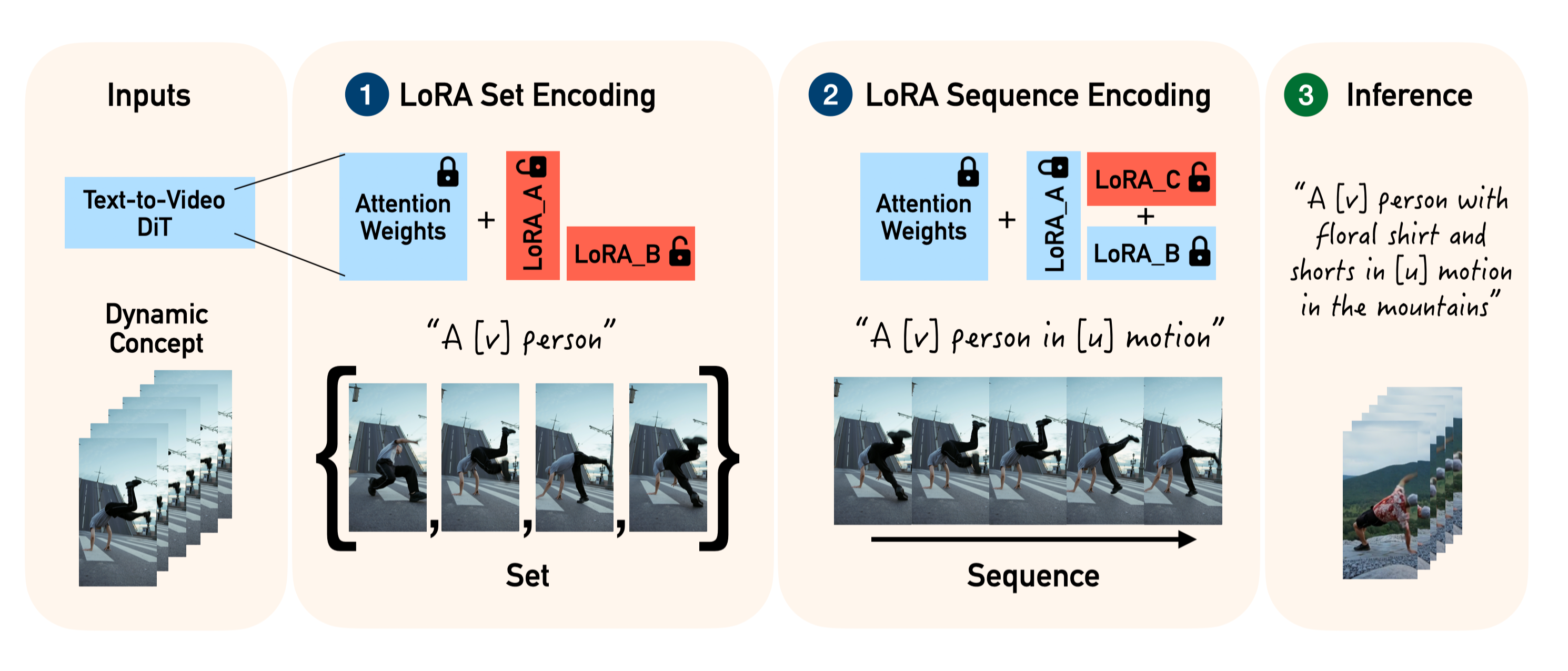
概要:Dynamic Concepts 是一项由 Snap Research 提出的新技术,旨在提升文本到视频生成模型的个性化能力,使其能够捕捉、操控并结合“动态概念”。与静态概念(仅由外观定义)不同,动态概念不仅包含外观特征,还涉及运动特征。该技术使用了一个创新的框架 Set and Sequence,将视频生成过程分为“集合”(Set)和“序列”(Sequence)两部分,分别处理静态外观和动态运动。通过 LoRA(低秩适配)技术,模型能够在训练过程中分别学习这些动态特征,从而生成更加符合个性化需求的视频内容。
标签:#动态概念 #视频生成 #个性化生成 #LoRA #Snap Research
ThinkDiff:为扩散模型赋能多模态推理的创新对齐框架
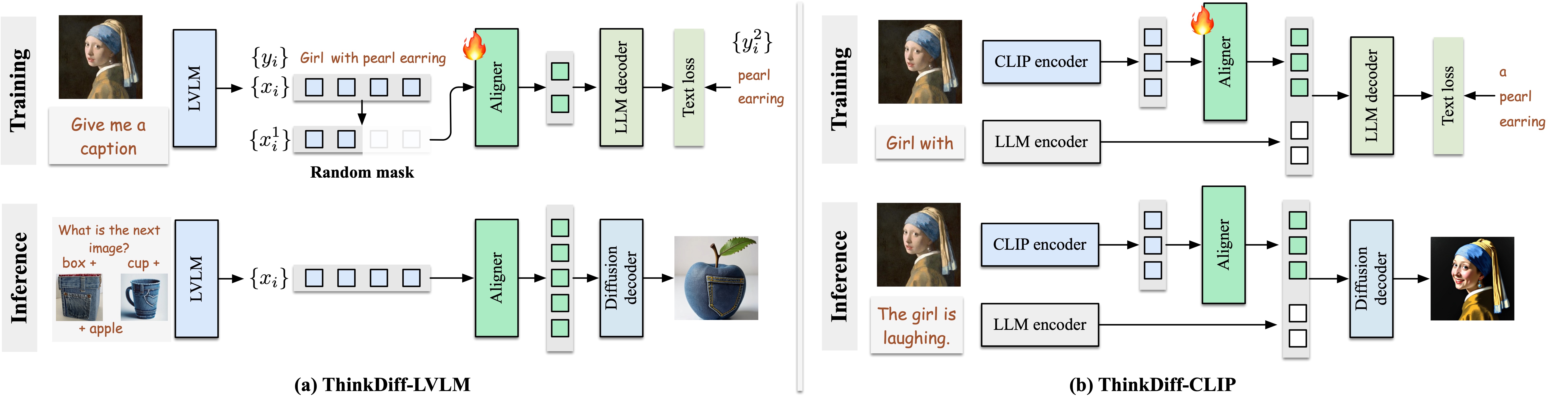
概要:ThinkDiff 是一种新的对齐框架,通过将视觉-语言模型(VLMs)与扩散解码器对齐,实现了多模态上下文推理能力的提升。与传统的扩散微调方法不同,ThinkDiff 通过将 VLM 对齐到大型语言模型(LLM)的解码器上,而不是直接对齐扩散解码器,从而有效解决了推理数据集稀缺的问题。该方法通过共享的输入特征空间简化了对齐过程,使得模型能够在不依赖复杂数据集的情况下,释放出强大的推理和合成能力。实验结果表明,ThinkDiff 在 CoBSAT 基准测试上的准确率从 19.2% 提高到 46.3%,且仅需 5 小时的训练。通过这种方式,ThinkDiff 展现了在图像-文本组合生成以及多图像合成上的卓越表现。
标签:#多模态推理 #扩散模型 #视觉语言模型 #语言模型 #图像生成