FLUX.1 Kontext-dev精控编辑 | Hunyuan-A13B超长MoE | Kimi-VL-A3B高效多模态【HF周报】
FLUX.1 Kontext-dev精控编辑 | Hunyuan-A13B超长MoE | Kimi-VL-A3B高效多模态【HF周报】

摘要
本周亮点:FLUX多轮一致性编辑、Hunyuan-A13B超长MoE、Kimi-VL-A3B多模态推理等热搜模型持续引领AI社区,涵盖多模态生成、超长上下文、OCR等最新开源进展,推动AI能力边界不断拓展。详见正文,相关参考链接请见文末。
目录
- FLUX.1 Kontext-dev:开源高一致性多模态图像编辑
- Hunyuan-A13B-Instruct:腾讯高效MoE中文大模型
- Magenta Realtime:Google开放实时音乐生成模型
- Nanonets-OCR-s:结构化智能OCR与语义标注
- Gemma-3n-E4B-it:Google高效多模态开源模型
- OmniGen2:统一多模态生成与编辑的高效开源模型
- Kimi-VL-A3B-Thinking-2506:MoonshotAI高效长上下文视觉语言模型
- Jan-nano-128k:Menlo Research超长上下文轻量模型
FLUX.1 Kontext-dev:开源高一致性多模态图像编辑

概要:Black Forest Labs 发布 FLUX.1 Kontext-dev,12B参数的流匹配变换器,专注于高一致性多轮图像编辑。支持文本指令驱动的图像内容修改,具备角色、风格、物体参考能力,无需微调即可实现多轮精细编辑且视觉漂移极小。模型采用指导蒸馏训练,效率高,开源权重支持学术和非商用,适配 ComfyUI、Diffusers 等主流推理框架,并针对 NVIDIA Blackwell 架构优化。官方还提供内容安全过滤、内容溯源等多重安全机制。
标签:#BlackForestLabs #FLUX1Kontext #流匹配变换器 #多模态图像编辑 #ComfyUI
Hunyuan-A13B-Instruct:腾讯高效MoE中文大模型
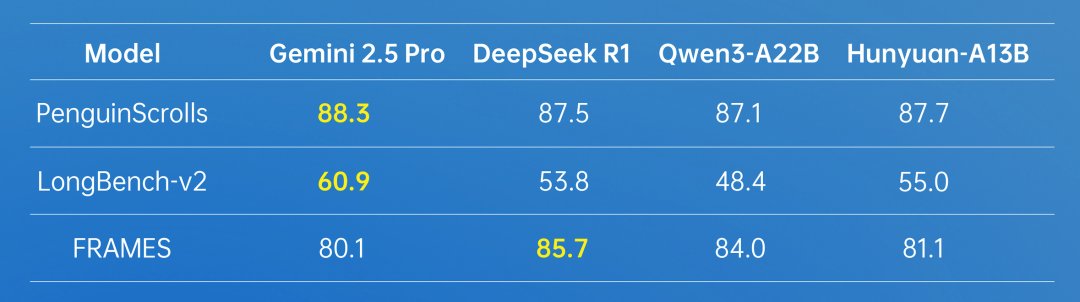
概要:腾讯开源 Hunyuan-A13B-Instruct,采用80B参数MoE架构,13B激活参数,兼顾高性能与资源效率。原生支持256K超长上下文,具备快/慢思维切换、Agent任务优化、分组查询注意力(GQA)、多量化格式等特性。模型在数学、科学、Agent等多项基准测试中表现领先,支持 Huggingface Transformers、TensorRT-LLM、vLLM、SGLang 等多种推理和部署方式。官方同步开放技术报告和训练/推理手册。
标签:#Tencent #HunyuanA13B #MoE架构 #超长上下文 #Agent优化
Magenta Realtime:Google开放实时音乐生成模型
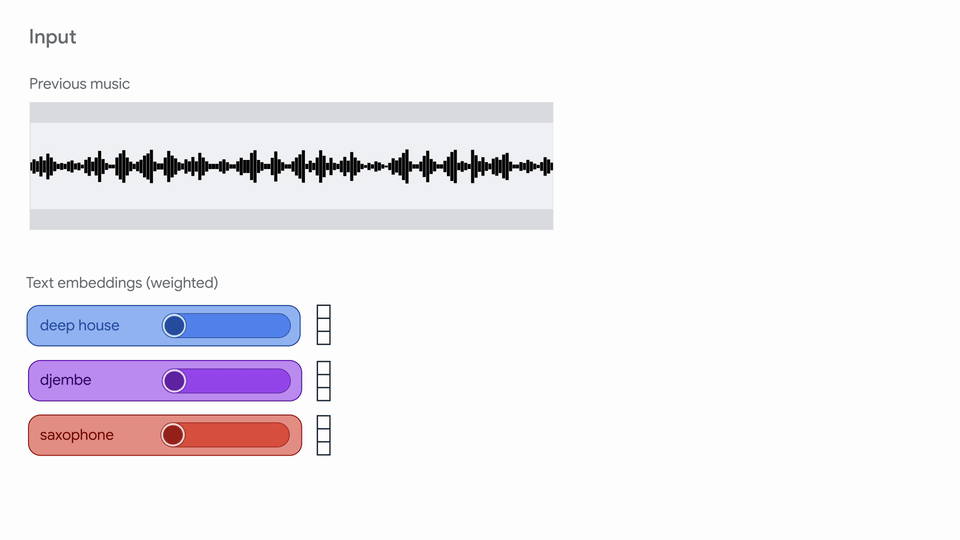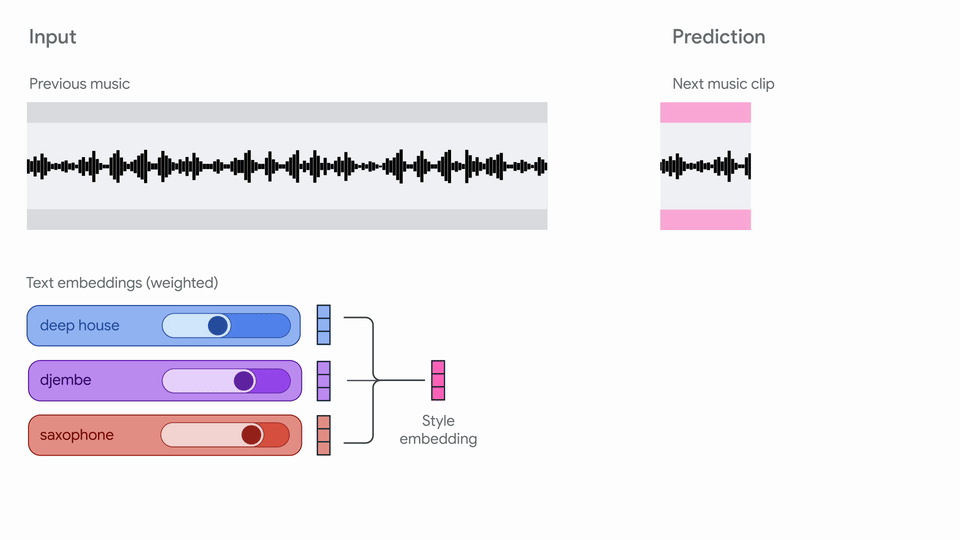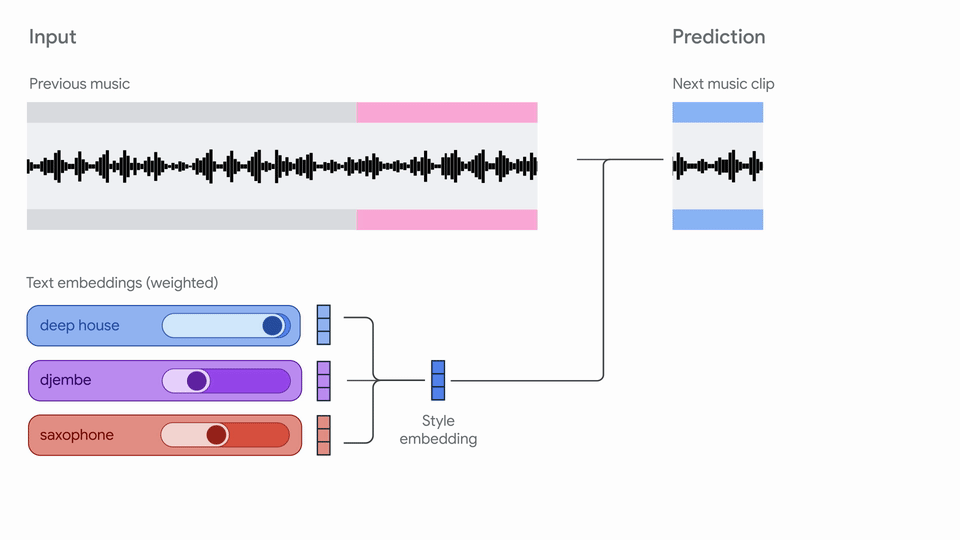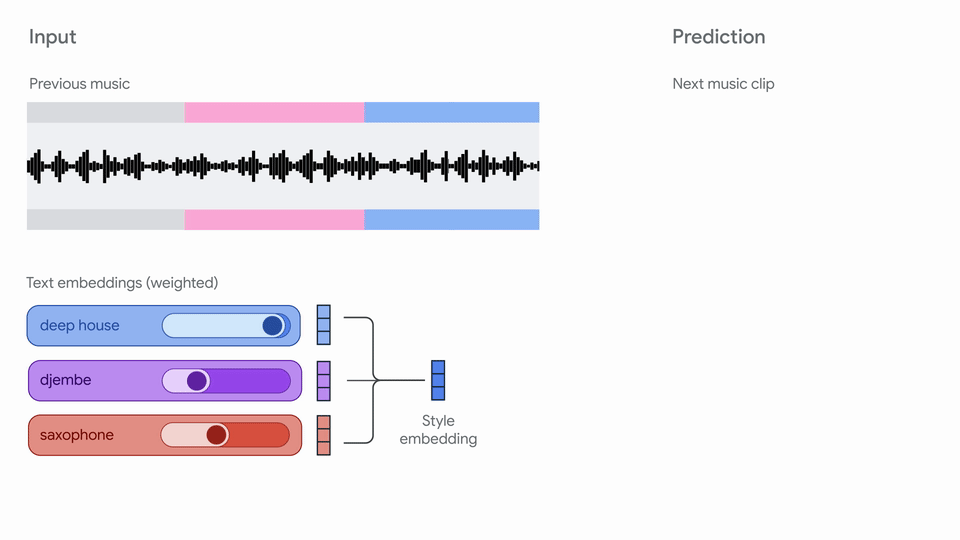
概要:Google Magenta 团队发布 Magenta RealTime,面向实时音乐生成场景。模型由 SpectroStream 音频编码器、MusicCoCa 音乐-文本对比嵌入、Transformer LLM 三部分组成,支持文本、音频、风格混合等多模态输入,能连续生成高保真音乐片段。适用于现场表演、辅助音乐创作、游戏配乐、音乐教育等场景。模型权重和代码分别采用 Apache 2.0 和 CC-BY-4.0 许可,支持本地TPU/GPU部署。
标签:#Google #MagentaRealtime #SpectroStream #MusicCoCa #实时音乐生成
Nanonets-OCR-s:结构化智能OCR与语义标注
概要:Nanonets-OCR-s 是一款基于 Qwen2.5-VL-3B 的视觉语言模型,专为结构化文档OCR设计。支持LaTeX公式识别、智能图片描述、签名/水印检测、表格/复选框提取等,输出结构化Markdown,极大提升下游LLM处理效率。模型在学术、金融、医疗、企业等多行业文档场景表现优异,支持 Transformers、vLLM、docext 等多种推理方式。
标签:#Nanonets #NanonetsOCRs #Qwen2.5VL3B #结构化OCR #语义标注
Gemma-3n-E4B-it:Google高效多模态开源模型
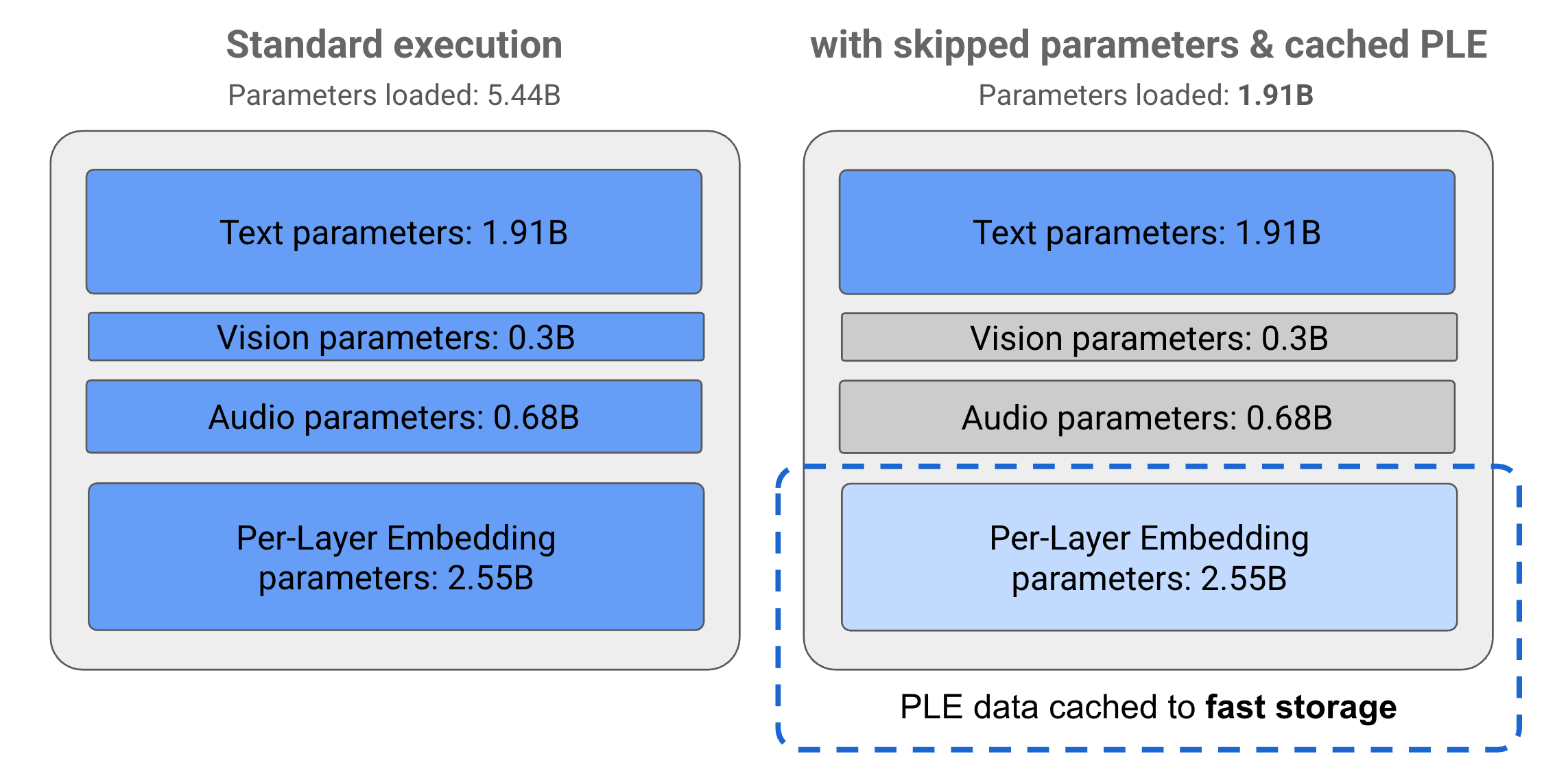
概要:Gemma-3n-E4B-it 是 Google 最新开源的多模态生成模型,支持文本、图像、音频、视频输入,具备32K上下文窗口。采用MatFormer嵌套子模型架构与PLE参数缓存,极大降低推理资源消耗,适配手机、PC等低资源设备。模型在140+语言、代码、数学、视觉等多领域训练,支持条件参数加载,灵活扩展。官方开放权重,支持商业用途,适配 Huggingface Transformers,适合多模态内容理解、生成、对话、音视频分析等场景。
标签:#Google #Gemma3n #MatFormer #多模态 #高效推理
OmniGen2:统一多模态生成与编辑的高效开源模型

概要:OmniGen2 是 VectorSpaceLab 发布的统一多模态生成模型,具备文本-图像双解码通路,参数不共享,图像分词器独立。支持视觉理解、文本生成图像、指令驱动图像编辑、上下文组合生成等能力,性能在开源同类模型中领先。支持CPU/显卡推理,资源占用低,适配Diffusers、Gradio等生态。官方已开放权重、技术报告和多种在线/本地Demo,适合多模态内容创作、编辑、理解等场景。
标签:#VectorSpaceLab #OmniGen2 #多模态生成 #图像编辑 #Diffusers
Kimi-VL-A3B-Thinking-2506:MoonshotAI高效长上下文视觉语言模型

概要:Kimi-VL-A3B-Thinking-2506 是 MoonshotAI 发布的高效MoE视觉语言模型,激活参数仅3B,支持128K超长上下文。该版本在多模态推理、视觉理解、视频分析、长文档处理等任务上大幅提升,支持高分辨率输入,推理效率高。模型在MathVision、MMBench、MMStar、VideoMMMU等多项基准测试中表现优异,适配VLLM、Transformers等主流推理框架,支持多轮推理与思维链输出。
标签:#MoonshotAI #KimiVL #MoE #视觉语言模型 #长上下文
Jan-nano-128k:Menlo Research超长上下文轻量模型

概要:Jan-nano-128k 是 Menlo Research 推出的轻量级大模型,原生支持128K超长上下文窗口,专为深度文档分析、长对话、多文档推理等研究场景设计。采用创新的上下文扩展机制,长文本推理性能无衰减,兼容MCP协议,适配vLLM、llama.cpp等推理框架。
标签:#MenloResearch #JanNano128k #超长上下文 #轻量模型 #MCP
参考链接
- FLUX.1 Kontext-dev Huggingface
- FLUX.1 Kontext-dev 官方公告
- FLUX.1 Kontext-dev ComfyUI 教程
- Hunyuan-A13B-Instruct Huggingface
- Hunyuan-A13B-Instruct GitHub
- Magenta Realtime Huggingface
- Magenta Realtime GitHub
- Magenta Realtime Colab Demo
- Nanonets-OCR-s Huggingface
- Nanonets-OCR-s 官方介绍
- docext Github
- Gemma-3n-E4B-it Huggingface
- Gemma-3n-E4B-it 官方文档
- Gemma-3n 技术博客
- OmniGen2 Huggingface
- OmniGen2 技术报告
- OmniGen2 Gradio Demo
- OmniGen2 GitHub
- Kimi-VL-A3B-Thinking-2506 Huggingface
- Kimi-VL 技术报告
- Kimi-VL GitHub
- Kimi-VL 官方博客
- Jan-nano-128k Huggingface
- Jan-nano-128k GitHub
- Jan-nano-128k 官方文档