StoryWeaver重塑视觉故事生成|Edicho实现一致性图像编辑|VideoAnyDoor增强视频对象插入【AI周报】
StoryWeaver重塑视觉故事生成|Edicho实现一致性图像编辑|VideoAnyDoor增强视频对象插入【AI周报】

摘要
本周重点:StoryWeaver提出Character Graph解决角色一致性与语义对齐问题;1.58bitFLUX极低比特量化FLUX;Orient-Anything实现零样本3D方向估计;Edicho推动一致性图像编辑。详情见正文。
目录
- StoryWeaver: 基于 LLM 的交互式故事生成器
- 1.58bit.flux: 高效的 Transformer 量化方法
- Orient-Anything: 从 3D 模型渲染中学习鲁棒的物体方向估计
- Edicho: 野外图像的一致性编辑
- VideoAnyDoor: 高保真视频对象插入与精确运动控制
- LTX-Video: 实时视频潜在扩散模型
StoryWeaver:统一世界模型实现知识增强的故事角色定制

概要: StoryWeaver 是由厦门大学与网易联合提出的统一世界模型,旨在实现知识增强的故事角色定制。该模型通过引入角色图(Character Graph),综合表示故事相关的知识,包括角色、角色属性以及角色之间的关系,从而在单一模型中实现高质量的故事可视化。此外,StoryWeaver 还结合了知识增强的空间引导(Knowledge-Enhanced Spatial Guidance),精确地将角色语义融入图像生成过程。实验结果表明,StoryWeaver 在生成生动的视觉故事情节和准确传达角色身份方面表现出色。
标签: #StoryWeaver #角色定制 #故事可视化 #知识图谱 #人工智能
1.58-bit FLUX:极低比特量化的文本到图像生成模型

概要: 1.58-bit FLUX 是首个将先进的文本到图像生成模型 FLUX.1-dev 成功量化至 1.58-bit(即权重仅取 {-1, 0, +1})的方案,在生成 1024×1024 图像时仍保持相当的性能。该方法无需访问图像数据,仅依赖于 FLUX.1-dev 模型的自监督。此外,研究者开发了针对 1.58-bit 运算优化的自定义内核,实现了模型存储减少 7.7 倍,推理内存减少 5.1 倍,并提升了推理速度。在 GenEval 和 T2I Compbench 基准测试中的广泛评估显示,1.58-bit FLUX 在显著提高计算效率的同时,保持了生成质量。
标签: #1.58-bt FLUX #文本到图像生成 #模型量化 #低比特量化 #FLUX
Orient-Anything:从3D模型渲染中学习鲁棒的物体方向估计

概要: Orient-Anything 是首个专为单视图图像物体方向估计设计的基础模型。由于缺乏标注数据,研究者通过渲染3D模型生成了200万张带有精确方向标注的图像。模型采用概率分布拟合的方法预测物体的3D方向,并通过多种策略提升从合成数据到真实数据的迁移能力。实验结果显示,Orient-Anything 在渲染图像和真实图像的方向估计中均达到了最新的精度水平,展现了在多种场景下的零样本泛化能力。
标签: #Orient-Anything #物体方向估计 #3D模型 #图像理解 #零样本学习
Edicho:野外图像的一致性编辑

概要: Edicho 是一种基于扩散模型的无训练图像编辑方法,旨在实现对野外图像的一致性编辑。通过显式的图像对应关系,Edicho 在推理阶段利用注意力操控模块和精细调整的无分类器引导去噪策略,实现跨图像的一致性编辑。该方法无需额外训练,兼容于大多数基于扩散的编辑方法,如 ControlNet 和 BrushNet。实验结果表明,Edicho 在多种设置下能够有效地实现一致性编辑。
标签: #Edicho #图像编辑 #一致性编辑 #扩散模型 #无训练方法
VideoAnydoor:高保真视频对象插入与精确运动控制
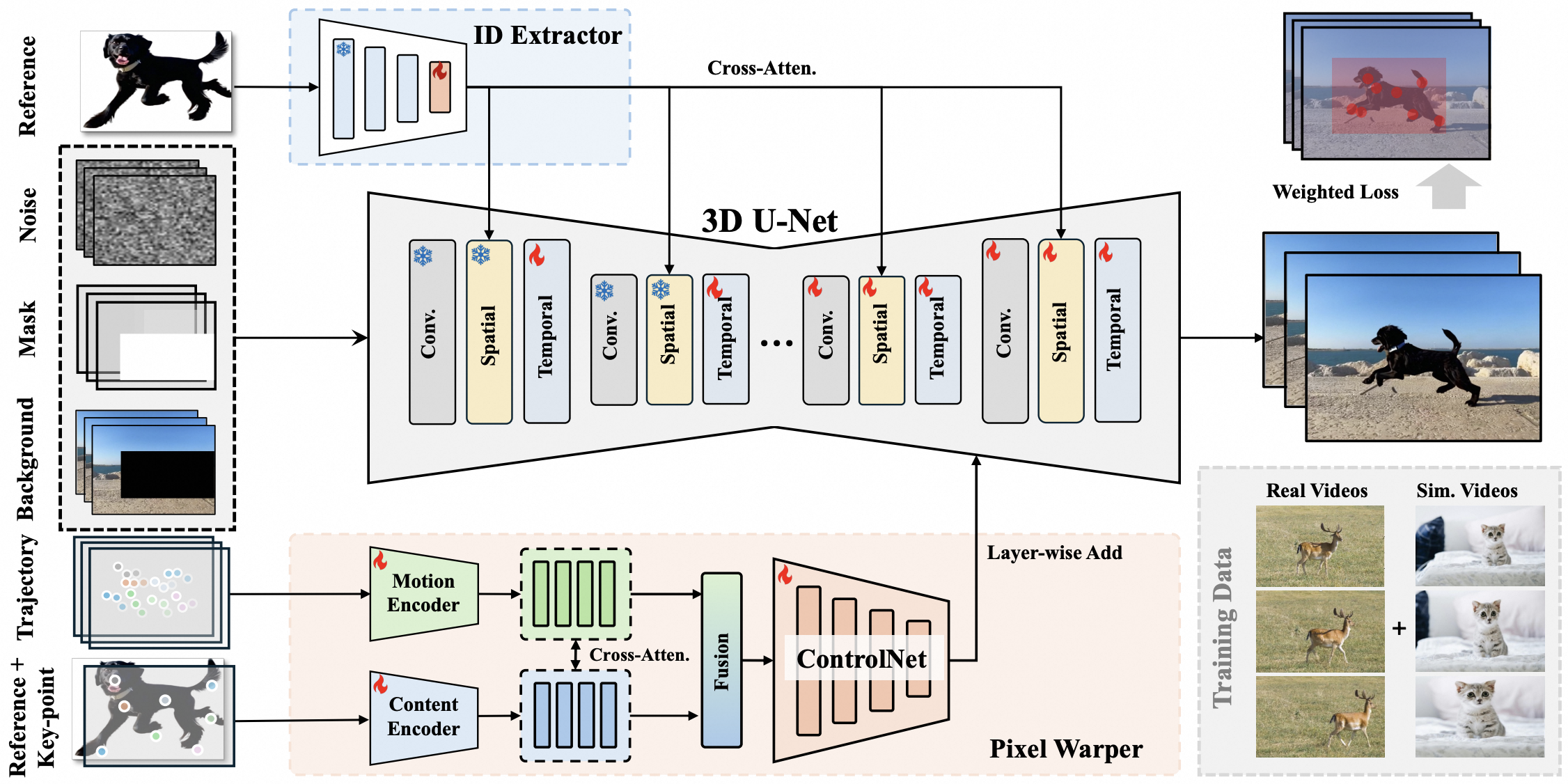
概要: VideoAnydoor 是一个零样本视频对象插入框架,旨在实现高保真的细节保留和精确的运动控制。该方法从文本到视频模型出发,利用身份提取器注入全局身份信息,并通过框序列控制整体运动。设计的像素变形器根据关键点轨迹对参考图像进行像素级变形,融合到扩散 U-Net 中,从而提高细节保留能力,并支持用户操控运动轨迹。此外,提出的训练策略结合视频和静态图像,采用重加权重构损失以增强插入质量。实验结果表明,VideoAnydoor 在视频人脸替换、虚拟试穿和多区域编辑等应用中表现出色,无需特定任务的微调。
标签: #VideoAnydoor #视频对象插入 #运动控制 #零样本学习 #扩散模型
LTX-Video:实时视频潜在扩散模型
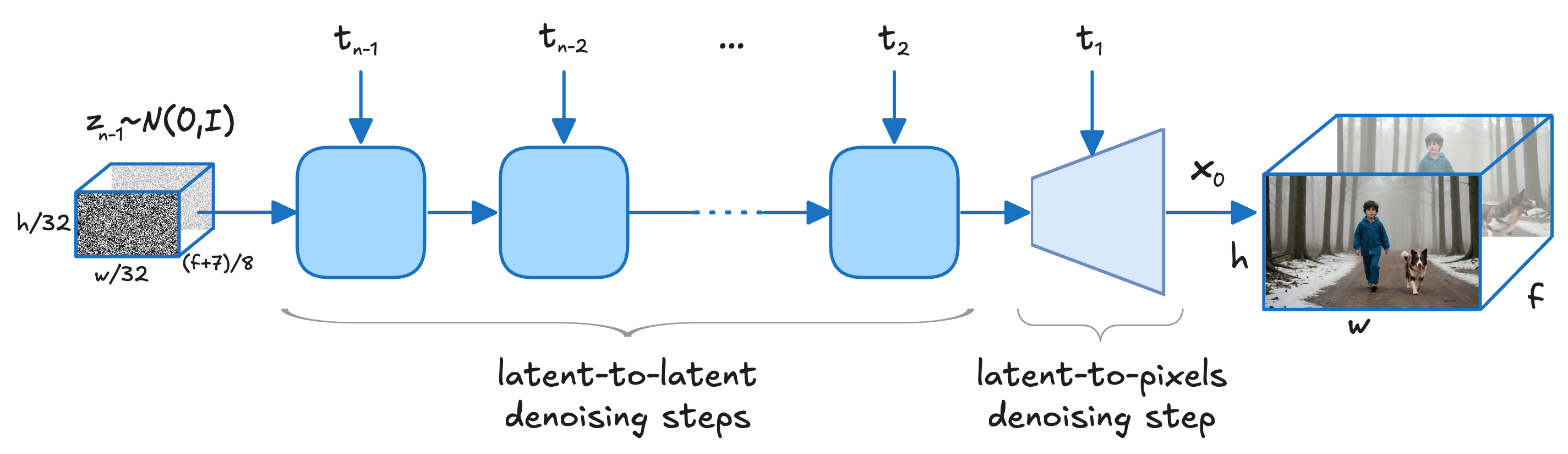
概要: LTX-Video 是由 Lightricks 开发的实时视频生成模型,采用基于 Transformer 的潜在扩散方法。该模型通过精心设计的 Video-VAE 实现 1:192 的高压缩比,使 Transformer 能够高效地执行全时空自注意力,从而生成具有时间一致性和高分辨率的视频。LTX-Video 支持文本到视频和图像到视频的生成,能够在 2 秒内生成 5 秒钟、分辨率为 768×512、帧率为 24fps 的视频,性能优于同类模型。
标签: #LTX-Video #视频生成 #Transformer #潜在扩散模型 #实时生成