什么是图像识别?算法和应用
什么是图像识别?算法和应用

想象一下,一个名叫 Emma 的小女孩对鸟类着迷。每个周末,她都会和爷爷一起去附近的公园观鸟。久而久之,Emma 学会了通过颜色、大小、形状甚至叫声来识别不同的鸟类。一天下午,在翻书时,她毫不费力地指着一张图片说:“看,爷爷!是知更鸟!”她没有测量翼展或分析羽毛类型;她的大脑立即将图像与她在公园里对知更鸟的经历和记忆联系起来。
这种人类天生的观察、理解和识别能力,让我们能够看到并认识事物。但如果我们想让计算机也做同样的事情呢?这正是图像识别旨在实现的目标。
图像识别是一项计算机视觉任务,它使机器能够解释和识别图像中的物体、人物、地点和动作。它通过分析数字图像中的模式、形状和特征来模仿人类理解视觉数据的能力。
在其核心,图像识别通过分析图像的像素并识别模式来工作。这是通过复杂的算法实现的,最著名的是一种称为神经网络的计算模型。这些神经网络受到人脑视觉皮层的启发,并在大量标记图像数据集上进行训练。通过处理这些图像,神经网络学会识别不同物体的特征和特性。
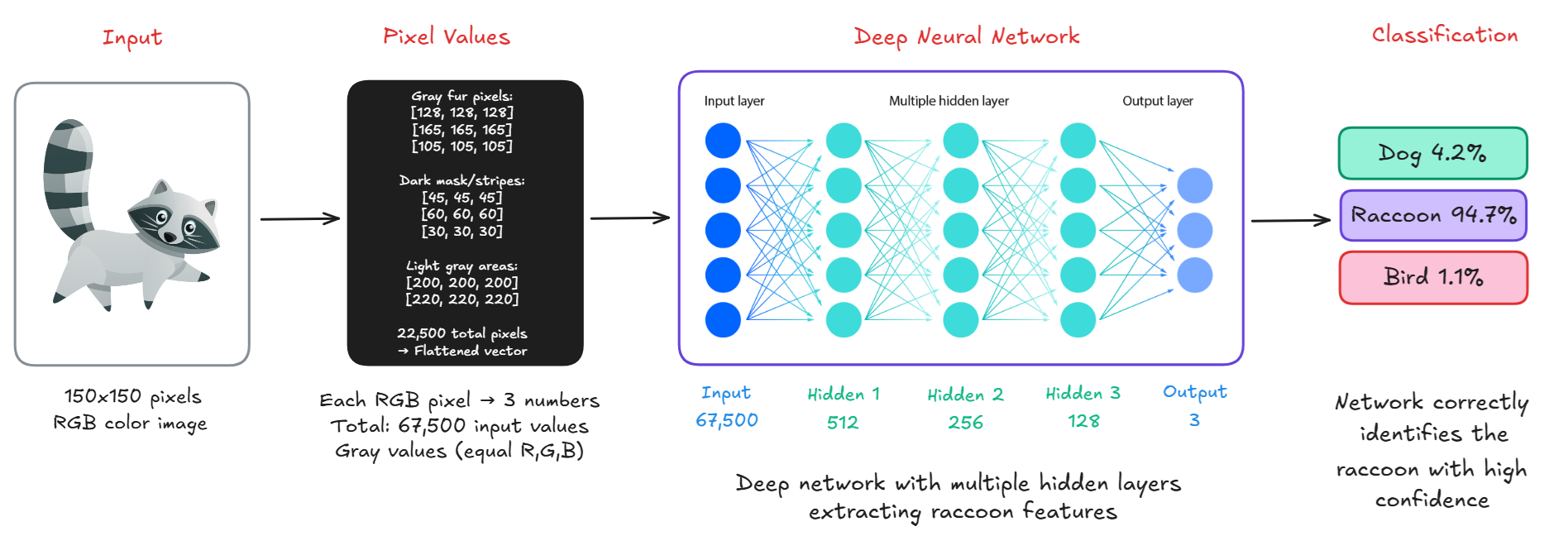
计算机如何识别图像
图像识别如何工作?
对人类来说,看到一张图像意味着立即识别出熟悉的形状、颜色或人物。但对于计算机来说,看东西是完全不同的,图像只是数字。以下是计算机如何“看”图像的分步说明。
步骤 #1:像素(计算机的视觉语言)
每张图像都由称为像素的微小点组成。每个像素都拥有一个代表颜色或阴影的数值。例如,灰度图像是一个二维数字网格(如下所示),其中每个数字的范围从 0(黑色)到 255(白色)。彩色图像有红、绿、蓝 (RGB) 三个通道,使其成为一个三维数组。
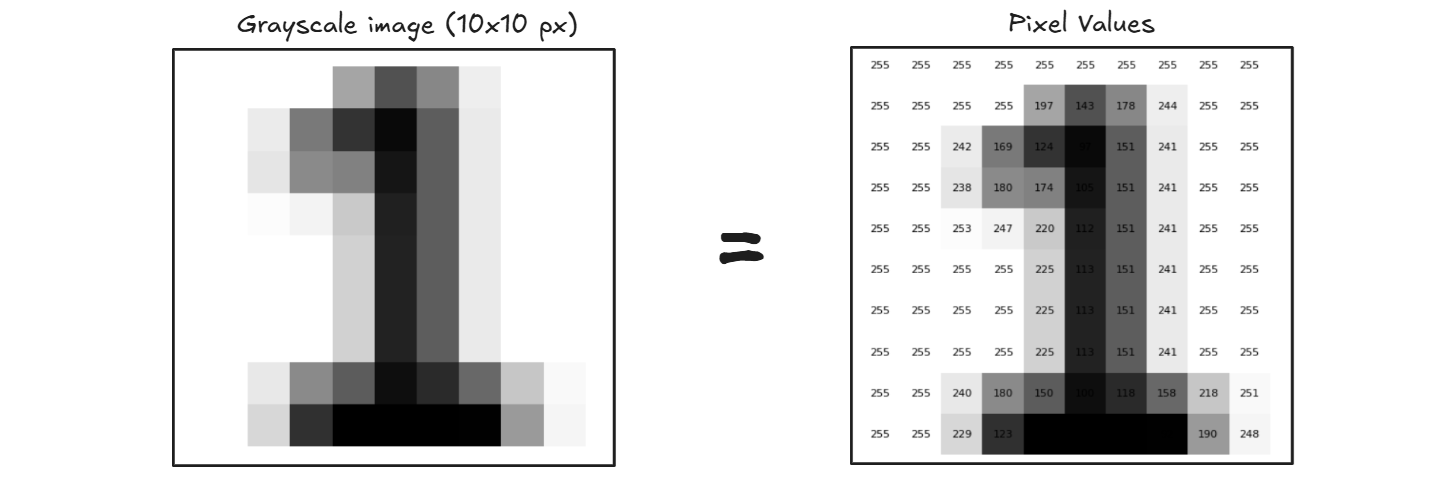
灰度图像表示
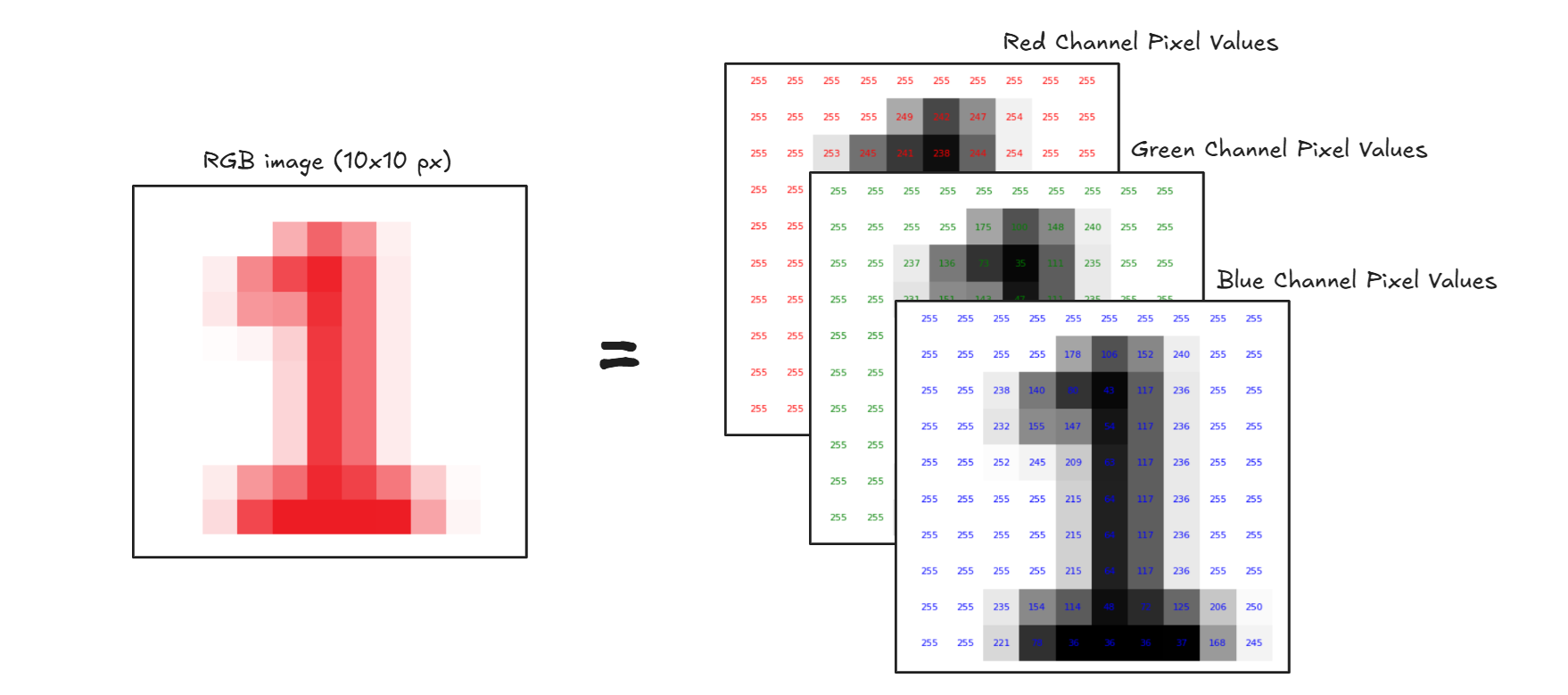
彩色图像表示
步骤 #2:特征检测(寻找模式)
一旦图像被转换成数字,计算机就会寻找边缘、角落和交汇点、线条和曲线、形状、纹理等模式。它使用滤波器或数学运算(如卷积等)来自动检测这些特征。
步骤 #3:从示例中学习(训练)
计算机会看到数千张标记好的图像(如猫、汽车或鸟类)。在训练期间,它会学习每种物体类型的共同特征。它将这些信息存储在神经网络中,这是一个类似于简化大脑的模型。
步骤 #4:分类(预测时间!)
当显示一张新图像时,计算机分析像素,检测特征,将其与所学知识进行比较,并输出一个标签(例如,“浣熊”)和一个置信度分数(例如,94.7%)。
让我们通过 R-CNN 架构来理解整个过程。下面的 R-CNN 架构图说明了计算机如何使用 R-CNN(基于区域的卷积神经网络)方法来观察和识别图像中的对象。在步骤 1 中,计算机接收输入图像,该图像在内部表示为像素值的网格。在步骤 2 中,R-CNN 不会一次性分析整个图像,而是生成大约 2,000 个区域提议,即图像中可能包含对象的较小部分。然后将这些区域变形为固定大小,并在步骤 3 中通过 CNN,该 CNN 应用一系列数学运算,如卷积、池化和非线性激活,以提取独特的特征(如边缘、纹理或图案)。最后,在步骤 4 中,使用分类器(如 SVM)对每个区域提取的特征进行分类,回答诸如“这是一个人吗?”或“这是一个电视显示器吗?”之类的问题。该过程显示了计算机如何不一次性理解整个图像,而是将其分解为多个部分,寻找有意义的模式,并使用学习到的数据来识别其中的内容,模仿人类视觉扫描场景以识别熟悉对象的方式。
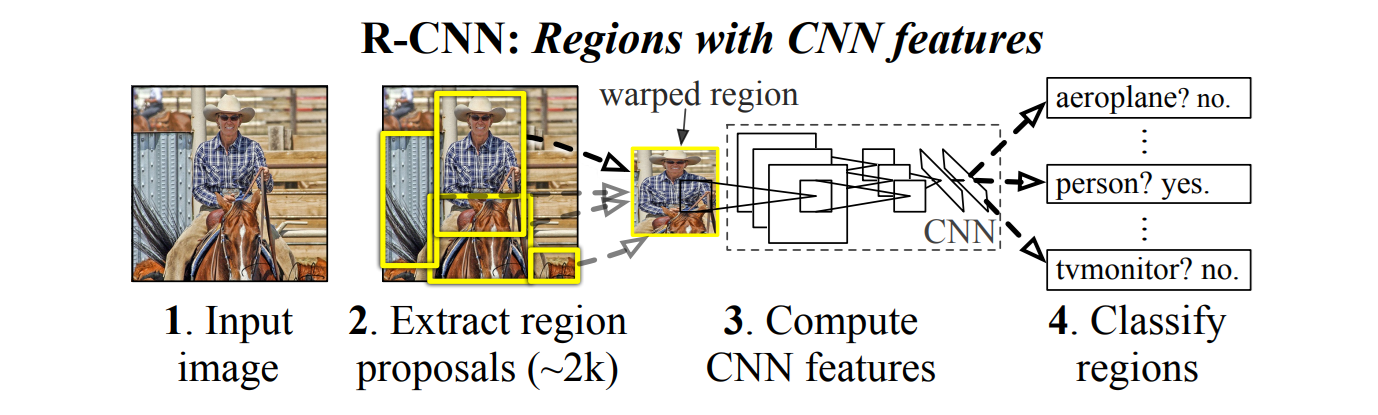
R-CNN架构
计算机不会将图像视为图片,而是将其视为数字网格。通过机器学习,尤其是深度学习,它学会识别这些数字中的模式,并将它们与已知对象进行匹配。就像孩子在看到许多狗之后学会识别狗一样,计算机从数据中学习“看”世界。
AI 中的图像识别模型类型
图像识别应用广泛,有不同类型的模型,每种模型都为特定任务而设计,例如分类、检测、分割、人脸识别或关键点估计。
图像分类模型
图像分类为整个图像分配一个标签。模型查看图像并预测它包含什么对象(或类别),如“猫”、“汽车”或“香蕉”。这些模型为整个图像分配一个标签,用于识别图像中的主要对象或场景(例如,“猫”、“飞机”、“骨折”)。
示例:
- ResNet 32/ ResNet-50:使用残差连接来解决深度网络退化问题。
- Vision Transformers (ViT):Vision Transformer 使用强大的自然语言处理嵌入 (BERT) 并将其应用于图像。
提示
在此处探索更多分类模型 here。
物体检测模型
物体检测模型 通过绘制边界框并分配标签(例如,“人”、“狗”)来定位和分类图像中的多个对象。这些模型通过在图像中的多个对象周围绘制边界框来定位和分类它们,用于识别和跟踪图像或视频中的多个人、车辆、动物或产品等对象。
示例:
- YOLOv12:快速的实时物体检测模型。
- DETR:基于 Transformer 的端到端物体检测模型。
- RF-DETR:基于 Transformer 的实时物体检测模型。
- Grounding DINO:最先进的零样本物体检测模型。
提示
在此处探索更多物体检测模型 here。
实例和语义分割模型
这些模型使用以下方法执行像素级分类:
- 语义分割标记每个像素(例如,天空、道路、人)
- 实例分割还区分单个对象(例如,人 1 与人 2)
这些模型用于理解对象的形状和确切边界,例如,将道路车道、肿瘤或叶子与背景隔离。
示例:
- Mask R-CNN:将 Faster R-CNN 与像素掩码相结合。
- YOLOv8 实例分割:最先进的 YOLOv8 模型支持实例分割任务。
- Segment Anything 2:来自 Meta 的开放世界、基于提示的分割。
- SegFormer:用于语义分割任务的基于 Transformer 的模型。
关键点检测和姿态估计模型
关键点检测模型 识别对象上的特定地标,通常是人体关节(肘部、手腕、膝盖等)。姿态估计使用这些点来确定身体或对象的姿势或方向。这些模型用于估计人体姿势、手势识别、健身分析和运动捕捉。这些模型通常返回每个人 17-33 个身体关节的坐标:
[
{ "x": 100, "y": 200, "label": "left_elbow" },
...
]示例:
- YOLO-NAS Pose:由 Deci AI 开发的关键点检测模型。
提示
在此处探索 Roboflow 支持的关键点检测模型 here。
人脸检测和识别
人脸检测模型在图像中查找和定位人脸,人脸识别模型根据面部特征识别或验证个人。这些模型用于生物特征认证、安全监控、照片中的人脸标记和访问控制系统。
示例:
- RetinaFace:具有地标提取功能的高精度人脸检测器。
- FaceNet / ArcFace / InsightFace:将人脸转换为用于匹配的嵌入。
- DeepFace:支持多种后端(如 VGGFace、Dlib 等)的高级包装器。
视觉语言模型 (VLM)
VLM 将图像理解与自然语言相结合。你可以问它们:
“这张图片里发生了什么?” 或 “狗在哪里?”
它们既能理解视觉模式,又能理解语言,从而给出智能的、基于文本的答案。这些模型使用自然语言解释图像,并可以回答有关图像的问题、生成标题或按名称查找对象。这些模型用于图像字幕、视觉问答、对象定位(“狗在哪里?”)和多模态 AI 应用。
示例:
- MetaCLIP:将图像与文本匹配(零样本)。
- Florence-2 / Kosmos-2:用于使用语言进行定位、字幕和分割。
- GPT-4o:讨论图像、生成标题、解释文档。
如何使用 Roboflow 进行图像识别 AI
Roboflow 允许您 训练、测试和 部署 能够识别图像的计算机视觉模型。只需几个步骤,您就可以构建强大的图像识别系统。以下是使用 Roboflow 构建图像识别 AI 的步骤。
步骤 #1:创建项目
选择您要构建图像识别模型的任务类型。Roboflow 支持以下项目类型。
- 图像分类(为整个图像分配标签。)
- 物体检测(用边界框识别物体及其位置。)
- 实例分割(检测多个物体及其形状。)
- 语义分割(将每个像素分配给一个标签。)
- 关键点检测(识别主体上的关键点/骨架)
- 多模态(使用文本对描述图像)
步骤 #2:上传您的数据集
项目创建后,将您的图像上传/拖放到 Roboflow 中。您还可以从 Roboflow universe、YouTube URL、云提供商 和 上传 API 导入数据。
步骤 #3:标注图像
使用 Roboflow 的内置 标注工具 标记您的图像。您可以使用以下标注技术:
- 手动标注:使用 Roboflow 的基于 Web 的 标注工具 标记对象(例如,边界框、多边形等)。
- 自动标注:使用 Roboflow 的 AI 辅助标注(即 Label Assist、Smart Polygon、Box Prompting、Auto Label)来加快流程。
步骤 #4:预处理和增强您的数据
Roboflow 提供预处理和增强选项以提高模型鲁棒性:
预处理:预处理涉及修改原始图像以使其标准化以进行模型训练。常用技术包括自动定向、隔离对象、静态裁剪、动态裁剪、调整大小、灰度、自动调整对比度、平铺等。
增强:增强通过对图像应用随机变换来人为地扩展数据集。这有助于防止过拟合(当模型记住训练数据而不是学习一般模式时)。常用技术包括
- 图像级增强,例如翻转、90° 旋转、裁剪、旋转、剪切、灰度、色调、饱和度、亮度、曝光、模糊、噪声、剪切、马赛克。
- 边界框级增强,例如翻转、90° 旋转、裁剪、旋转、剪切、亮度、曝光、模糊、噪声。
步骤 #5:生成数据集
单击“创建”以使用您选择的设置创建数据集版本。
步骤 #6:训练模型
您现在可以使用 Roboflow 训练模型。您可以通过“自定义训练”按钮为托管模型选择 Roboflow 的内置自动训练选项。或者,您可以导出数据集以在本地使用 YOLO、TensorFlow 或 PyTorch 进行训练。以下是将数据集导出为 YOLOv8 格式进行训练的示例。
from roboflow import Roboflow
rf = Roboflow(api_key="YOUR_API_KEY")
project = rf.workspace().project("your-project")
dataset = project.version(1).download("yolov8")提示
查看示例 notebooks 来训练您的模型。
步骤 #7:部署您的模型
Roboflow 提供灵活的部署选项,允许您在云、本地或各种边缘设备上运行您的视觉模型。训练完成后,Roboflow 提供:
- 工作流部署,可快速配置、集成和部署模型到应用程序中。
- 托管的图像和视频推理端点部署,这些部署依赖于互联网,易于为非实时和批量处理需求设置。
- 边缘部署,适用于嵌入式设备(如 TPU 或 Android 手机),使用自定义代码,或通过 Docker 容器部署到边缘设备(如 NVIDIA Jetson),以实现可扩展的实时推理。
- 其他部署选项包括由 Roboflow 管理的专用远程服务器、iOS 上的移动部署、Snap AR Lens Studio 集成等,从而实现跨平台和用例的广泛兼容性。
Roboflow 工作流如何用于图像识别
Roboflow Workflows 是一项功能,可让您将多个计算机视觉模型组合成一个管道。工作流不是一次运行一个模型,而是让您自动将对象检测、分类和 OCR(文本识别)等任务链接在一起,只需一次 API 调用即可获得最终结果。在 Roboflow Workflows 中,您可以使用不同的模型类型和功能块构建图像识别管道,每个块负责一个特定的任务。这些块可以按顺序组合以形成一个完整的视觉处理管道。
Roboflow Workflows 是一个强大的工具,因为它支持:
- 预训练模型
- 自定义训练/微调模型
在 Roboflow 中使用预训练模型
Roboflow 提供了几种即用型模型(例如 YOLOv8、YOLOv11、YOLO-NAS、RF-DETR-Base、VLM/多模态模型),您可以在自己的图像上尝试,而无需进行任何训练。您可以借助不同的块在 Roboflow Workflows 中直接使用这些模型。例如,您可以使用 对象检测模型块 使用 RF-DETR-Base 或 YOLOv8 模型,使用 实例分割模型块 使用 YOLOv8n-Seg 分割模型,使用 关键点检测模型块 使用 YOLOv8n-Pose 姿态估计模型,使用 OpenAI 块 使用 GPT-4o 模型,使用 Google Gemini 块 使用 gemini-2.0-flash 模型等等。
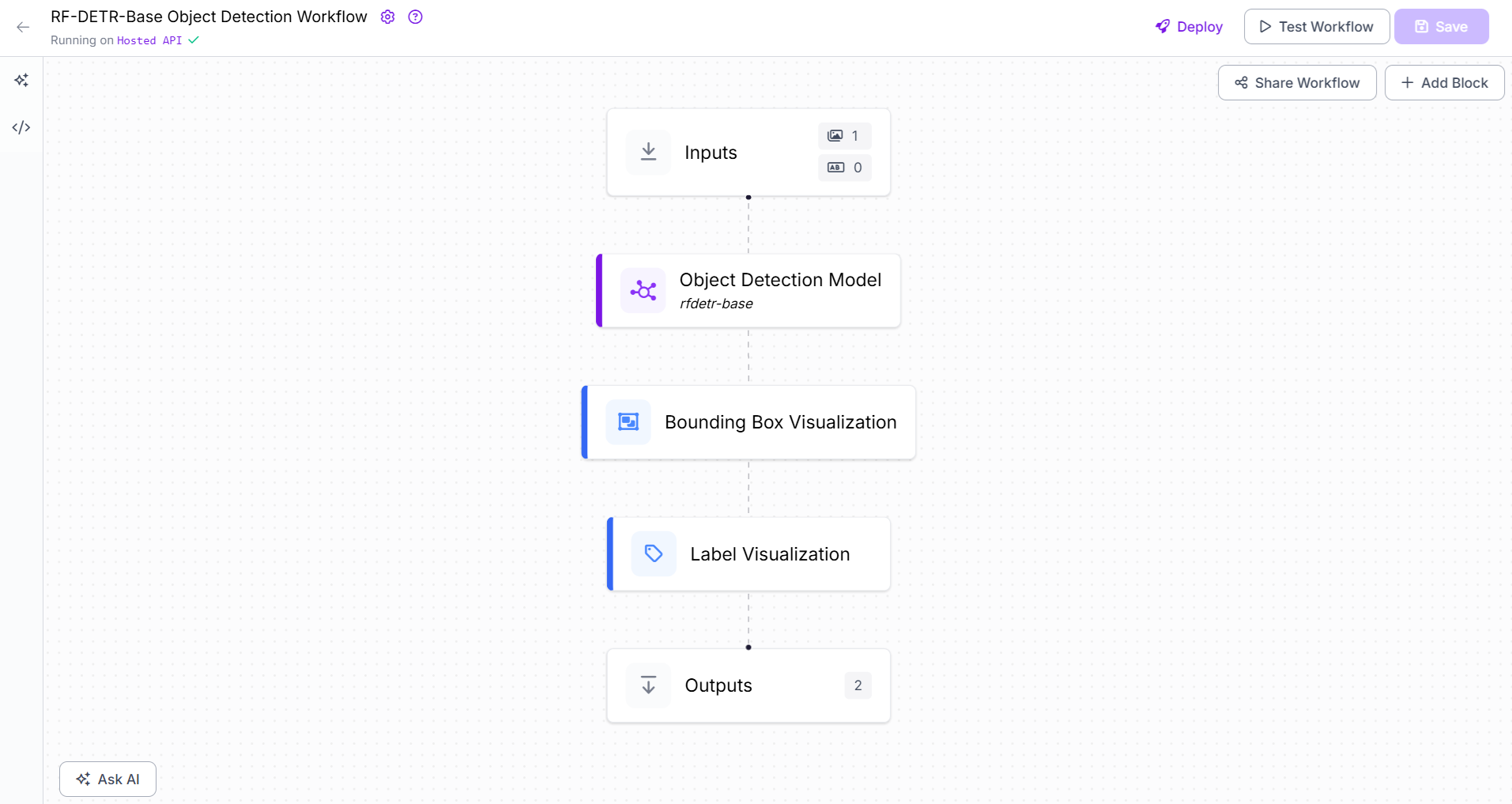
Roboflow 工作流示例
提示
Roboflow Workflows 是一个无代码计算机视觉应用程序构建器,允许用户在 Web 浏览器中创建多步骤、复杂的计算机视觉应用程序。它使用户能够连接各种块(预构建的功能)来设计和构建视觉管道,而无需广泛的编码专业知识。这些工作流可以部署在 Roboflow Cloud 上,也可以自托管在各种硬件上,包括边缘设备。
使用经过训练或微调的自定义模型处理您的数据
Roboflow 是一个端到端的计算机视觉开发平台。它支持构建计算机视觉模型的整个生命周期,从数据收集和标记到数据集生成、训练、微调、推理、部署和与 API 的集成。一旦您使用 Roboflow 训练了自定义计算机视觉模型,它就会被托管并随时可以通过 API 集成到您的应用程序中。您还可以通过您的工作区或 Roboflow 平台中其他用户工作区中的公开可用模型将这些模型集成到您的 Roboflow Workflow 中。
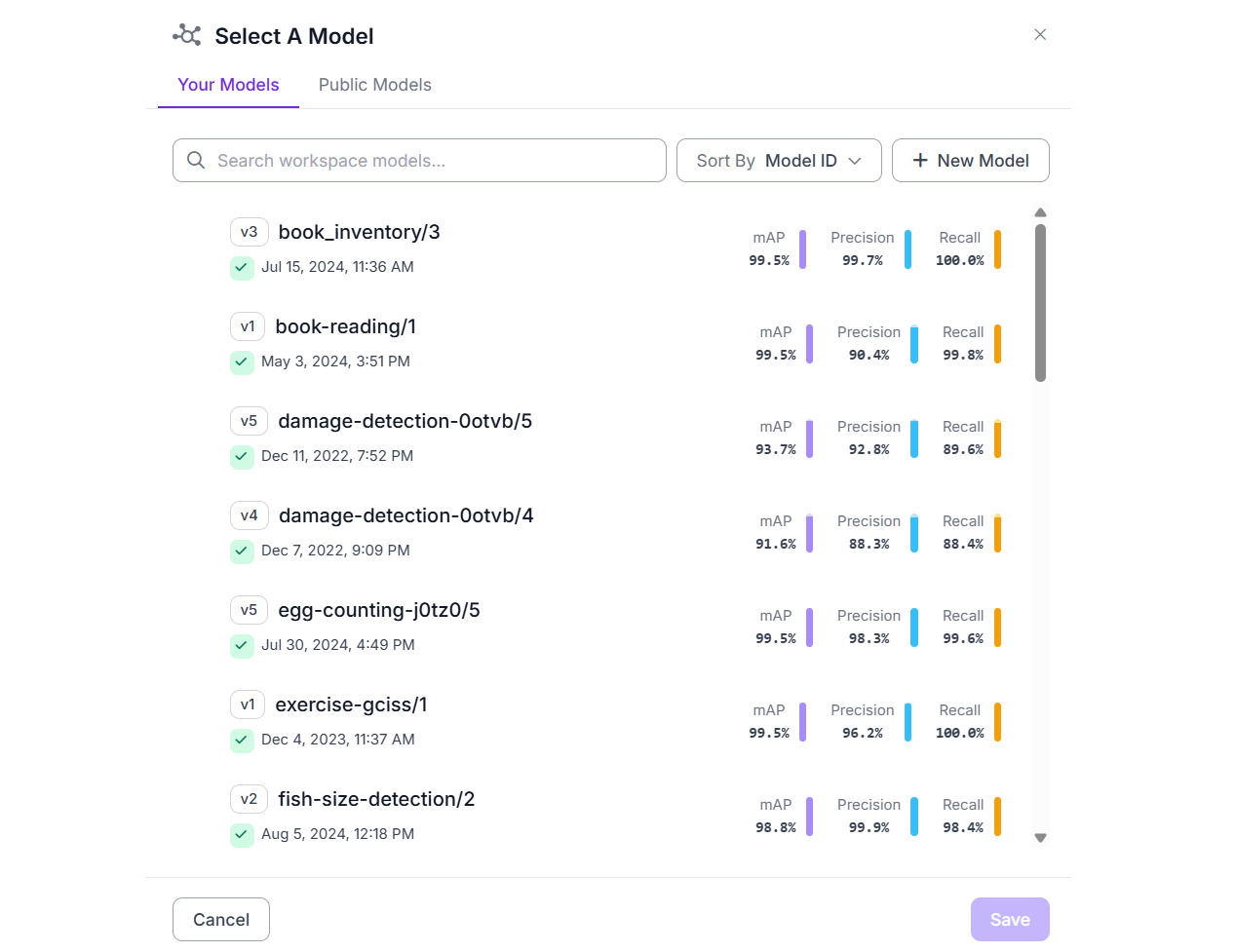
Roboflow 工作区中的自定义训练模型
使用 Roboflow 构建图像识别 AI
现在让我们看一些如何使用 Roboflow 构建图像识别 AI 应用程序的示例。在本节中,我们将使用自定义训练模型(木材/原木检测、手势识别)以及预训练模型 (Florence-2) 和 Roboflow Workflows 来构建我们的应用程序。
示例 #1:检测和计数木材/原木
在此示例中,我们将构建一个 Roboflow Workflow 应用程序,该应用程序将识别和检测木材/原木并对其进行计数。创建对象检测项目、上传和标记数据集并使用 Roboflow 自动训练选项训练模型。训练好的模型可在 Roboflow 托管的推理服务器上使用,我们可以使用它。
在此示例中,我们构建了一个 Roboflow Workflow 应用程序,旨在检测和计数图像中的原木(木块)。该项目采用对象检测方法,使用 Roboflow 2.0 对象检测(快速)模型。为了创建此应用程序,将包含 183 张标记有木材原木的图像的自定义数据集上传到 Roboflow。图像中的每个原木都用类别标签“log”进行注释。该模型使用 Roboflow 的 AutoML 训练管道进行训练。该模型经过训练,mAP@50 达到 94.6%,精确率为 95.0%,召回率为 91.4%。训练好的模型,标识为 wood-zay26/1,托管在 Roboflow 的推理服务器上,可以集成到工作流中或通过 API 调用。
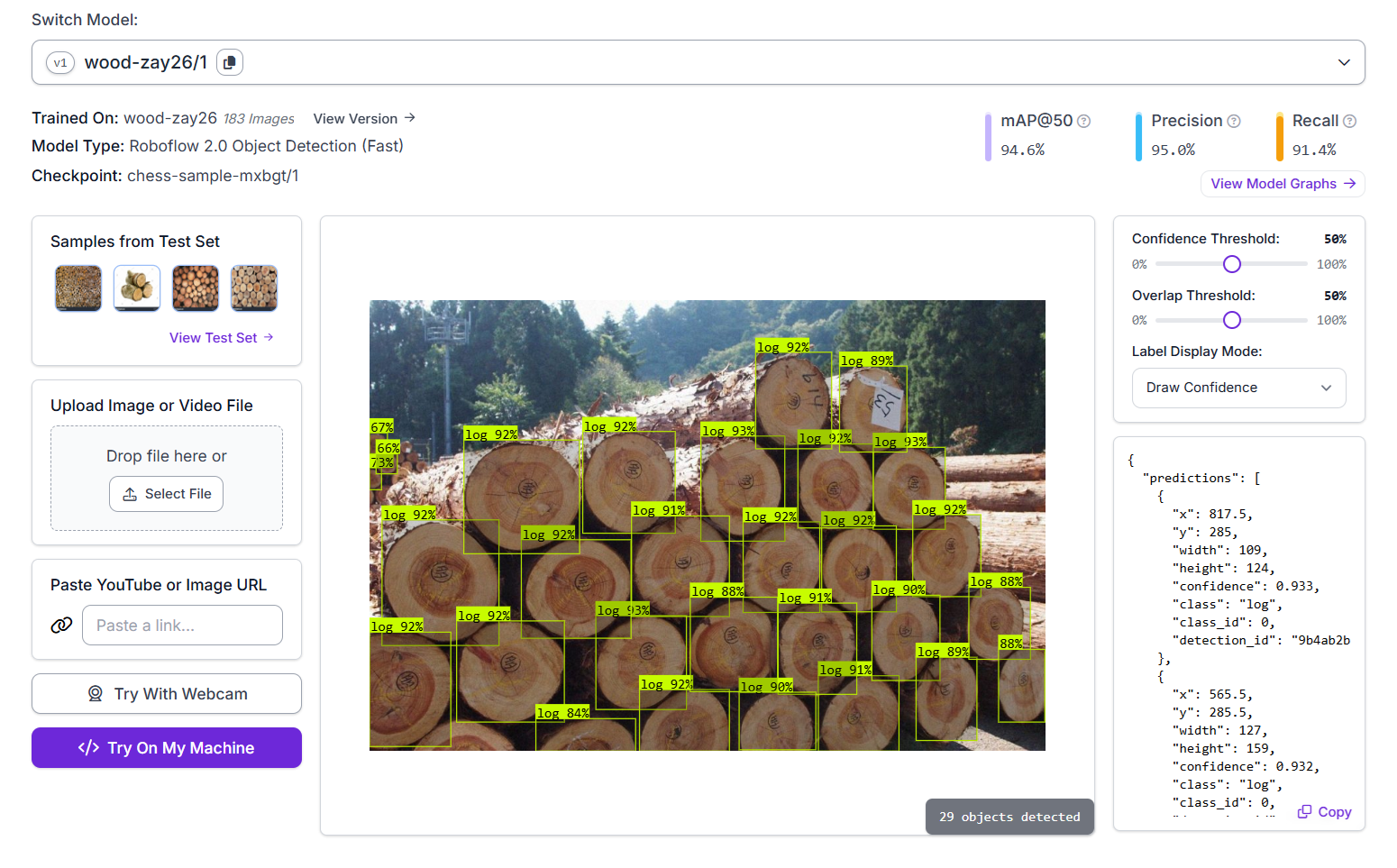
Roboflow 上的 木材/原木检测 模型
我们将通过创建一个新的工作流并添加一个对象检测模型块来将此模型集成到我们的 Roboflow Workflow 中。此块负责使用训练好的模型运行推理。在该块的配置中,将 Model 属性设置为 wood-zay26/1,它指向部署在 Roboflow 上的自定义对象检测模型。这使工作流能够使用训练好的模型自动检测和标记输入图像中的原木。
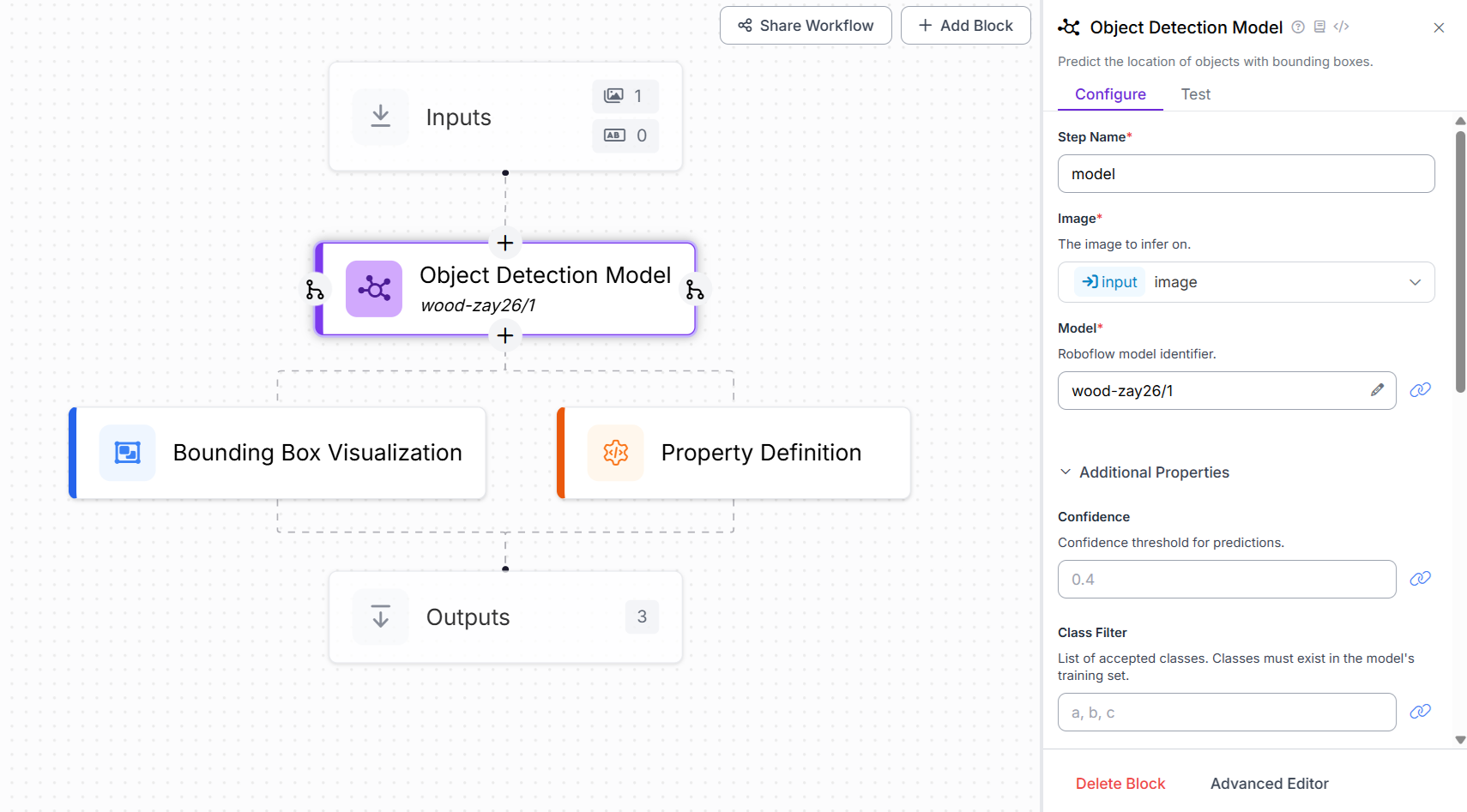
木材/原木检测和计数工作流
现在添加属性定义块。此块用于计算检测次数,有助于计算图像中木材/原木的数量。将此块的 Operations 属性设置为“Count Items”,如下所示。
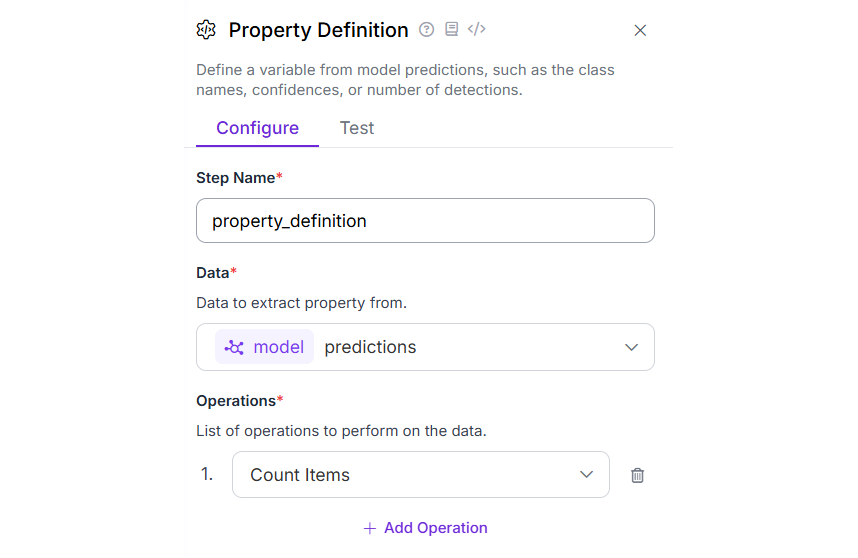
属性块配置
最后,添加一个边界框可视化块,以在已识别对象上显示带有边界框的检测结果。工作流执行后,它将生成一个输出图像,突出显示每个检测到的木材原木,让您能够直观地确认模型对图像中原木的识别。
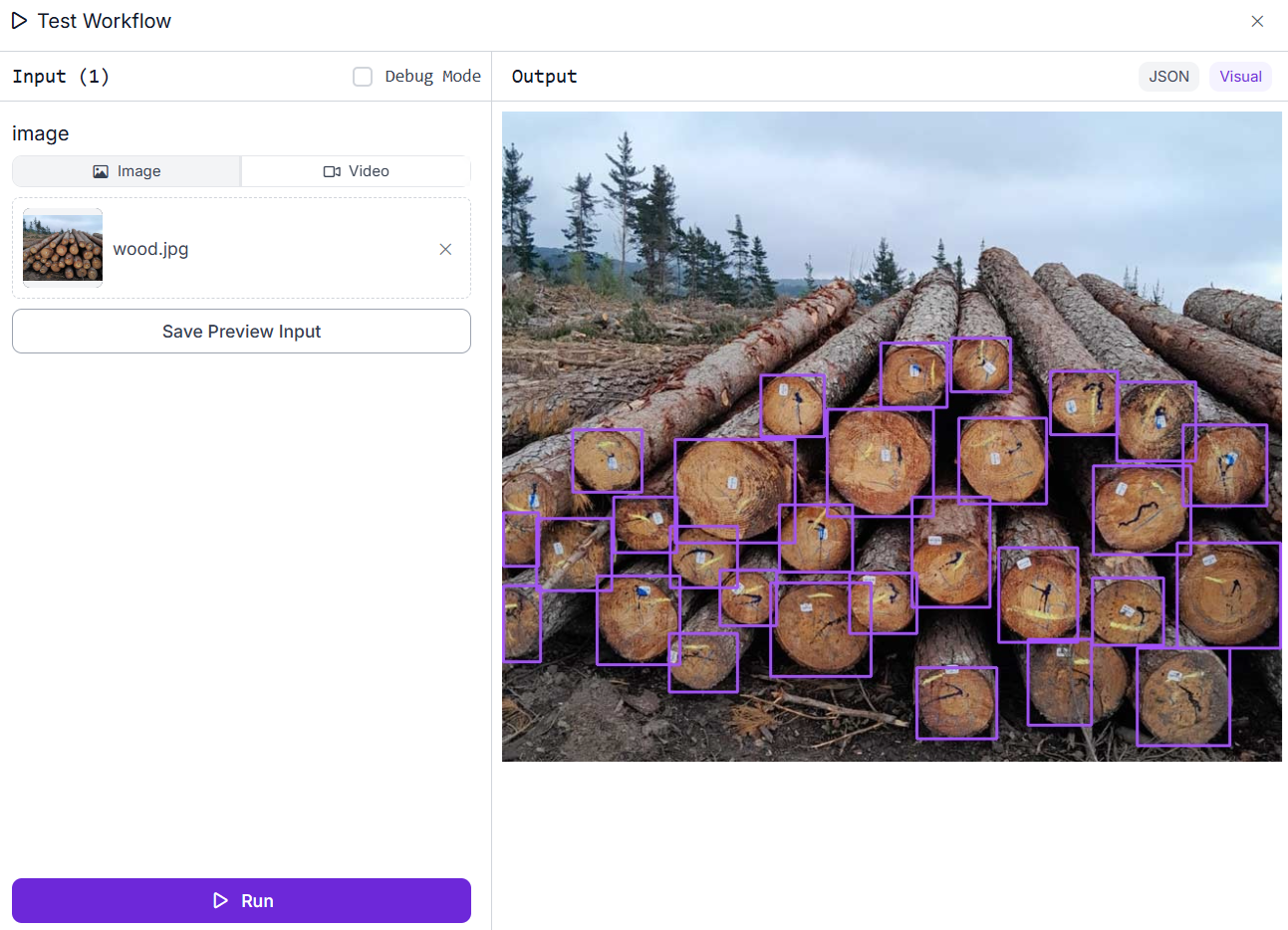
木材/原木计数工作流的输出
JSON 输出显示了属性块的结果,该结果提供了图像中检测到的木材原木的总数。
"property_definition": 29这种类型的工作流在林业管理、库存跟踪和自动化材料处理中特别有用,在这些领域中需要对堆叠图像中的原木进行计数和识别。
您还可以使用网络摄像头输入或边缘设备在本地或实时运行此工作流,甚至可以通过调整置信度阈值和重叠设置来进一步自定义它。
示例 #2:识别手势
在此示例中,我们使用来自 Roboflow 的自定义训练的对象检测模型构建了一个 手势识别 应用程序。该模型旨在根据图像中手的形状检测和识别不同的手势,如下图所示。这些手势用于控制交流灯泡。
提示
阅读完整博客 使用计算机视觉构建基于手势的灯光控制器。
该模型使用 Roboflow 的 AutoML 管道进行训练,基于 Roboflow 3.0 对象检测(精确)架构,并以 COCOs 检查点为基础。训练数据集由代表各种手势的带注释图像组成,每个手势都用相应的手势名称作为类别进行标记。
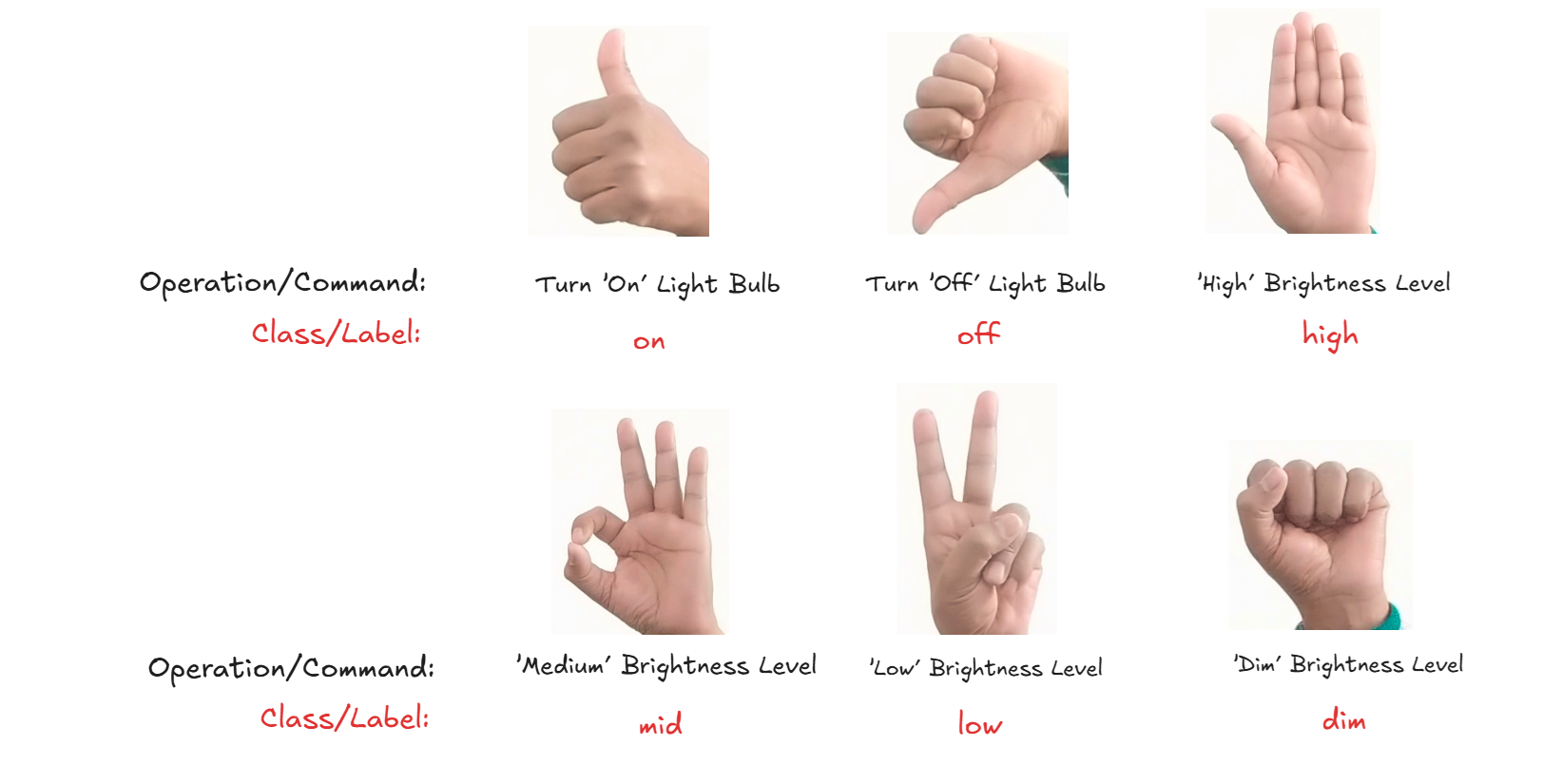
手势数据集
在下面显示的推断中,该模型已成功检测到手势并以 96% 的置信度将其标记为“on”。该模型经过训练,mAP@50 达到 99.5%,精确率为 99.7%,召回率为 100.0%。
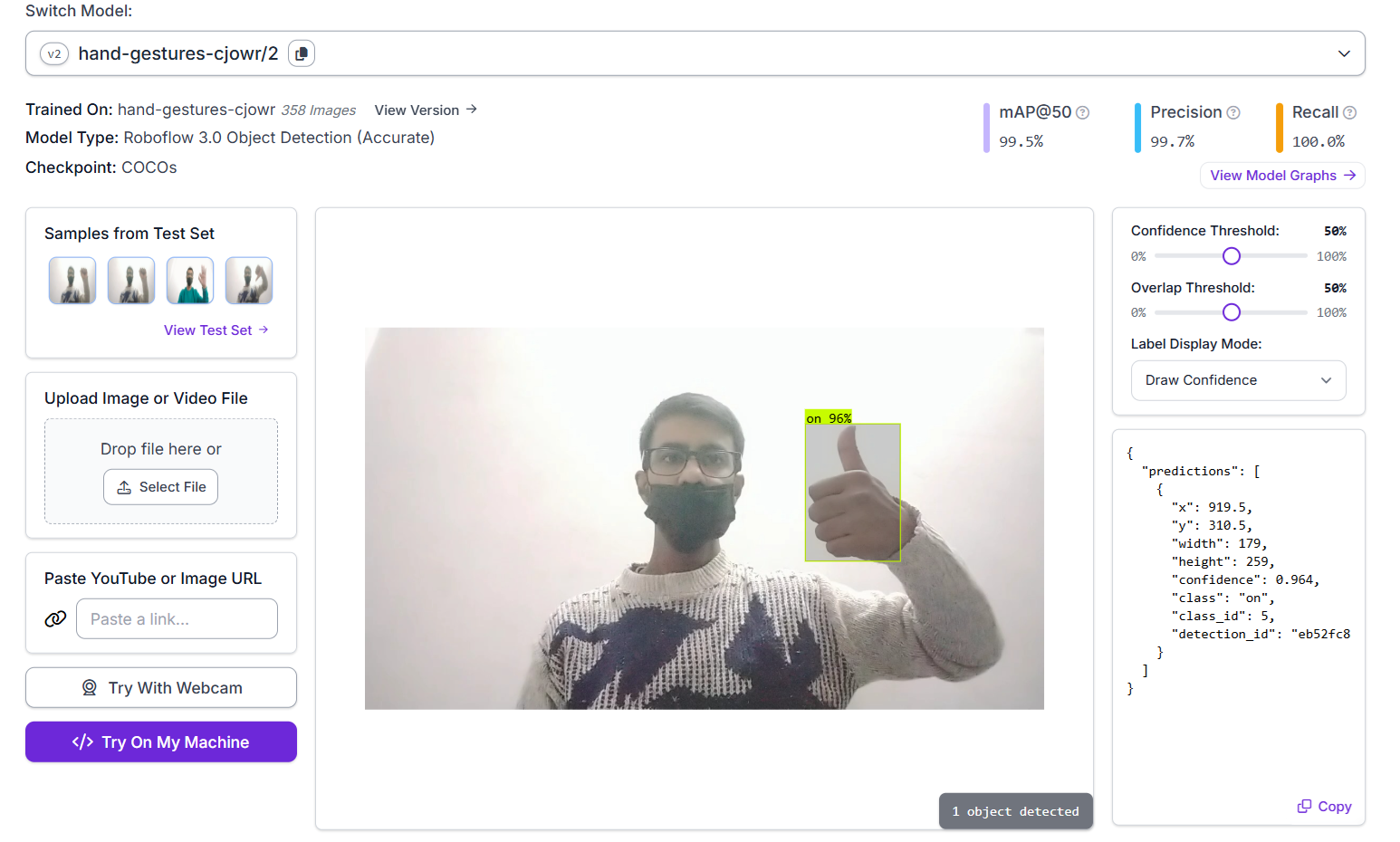
手势识别模型
我们将使用此模型在 Roboflow Workflow 中构建一个手势识别应用程序。要进行设置,请创建一个新的工作流并添加一个对象检测模型块,将模型属性配置为 hand-gestures-cjowr/2。然后,同时包含一个边界框可视化块和一个标签可视化块,以显示检测到的手势及其对应的类名。
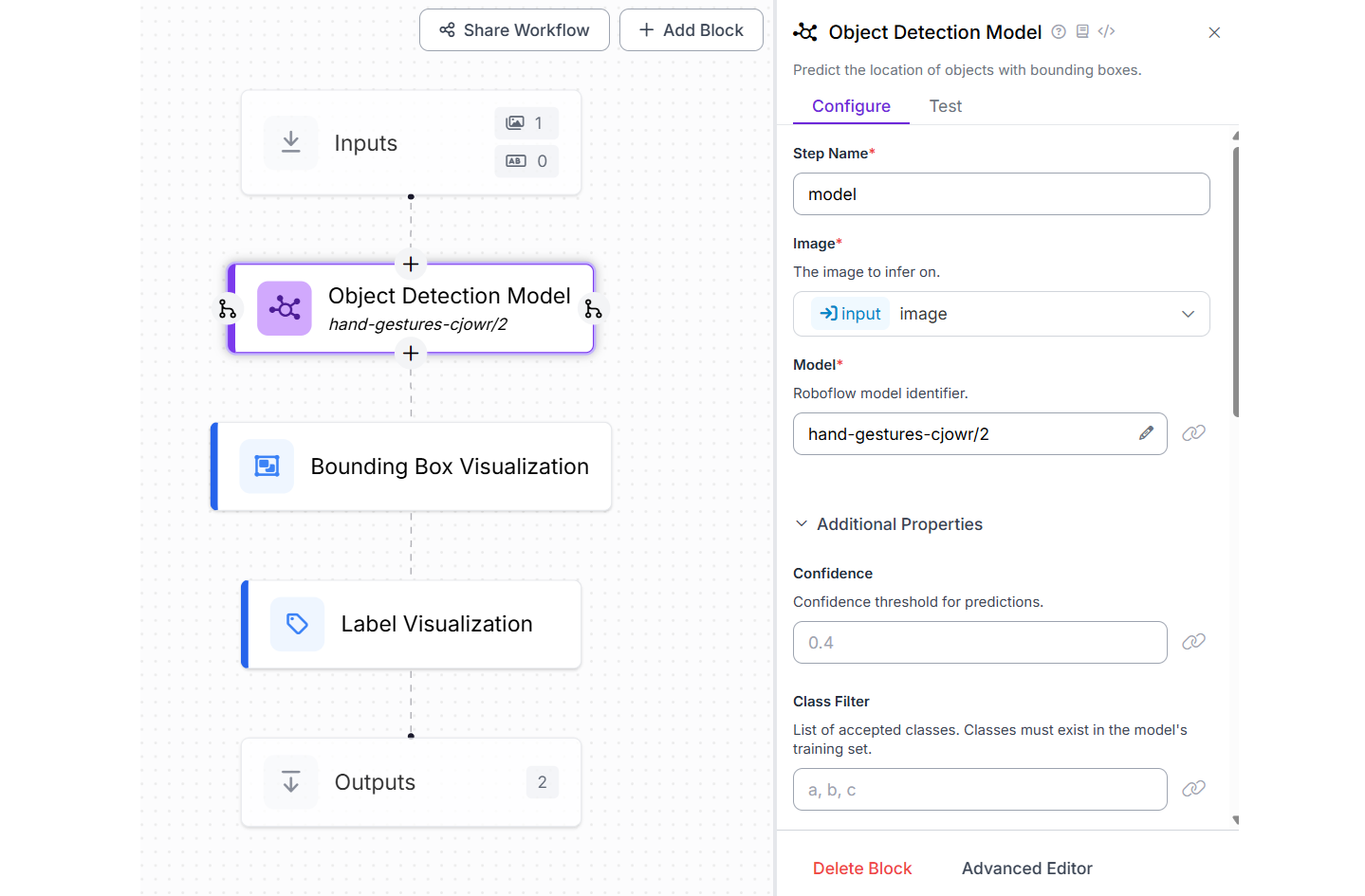
手势识别工作流
一旦在输入图像上执行工作流,它将用带标签的边界框突出显示每个识别出的手势。
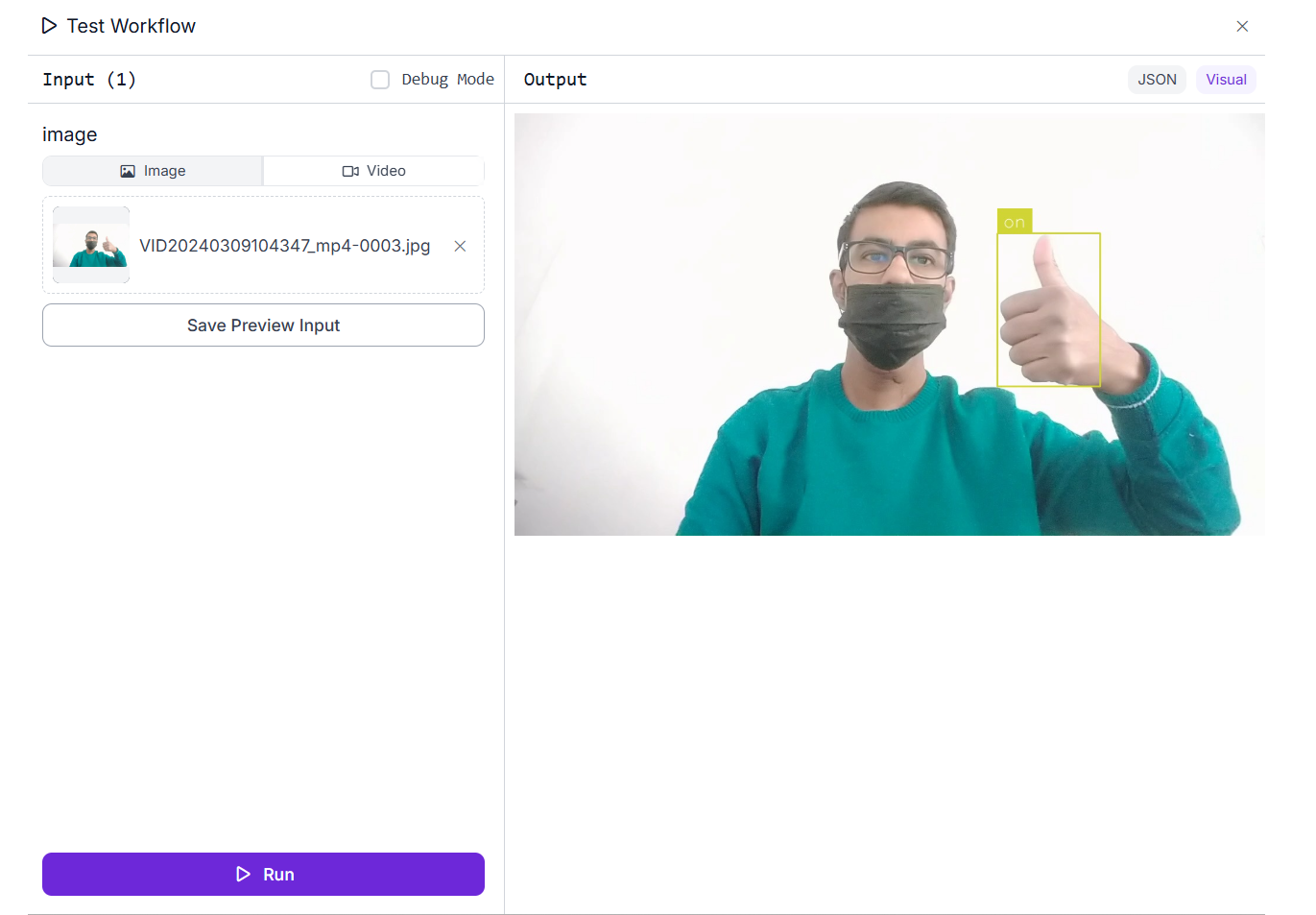
手势识别工作流的输出
除了处理静态图像外,该工作流还可以处理视频文件和实时视频流。使用 Inference Pipeline SDK,您可以在边缘设备上本地部署和运行工作流,以实时处理视频输入。这使其适用于交互式应用,例如基于手势的控制系统、智能家居界面、辅助技术和手语检测系统。
示例 #3:用于图像识别的 VLM
在此示例中,我们使用 Microsoft Florence-2 视觉语言模型 (VLM) 来构建一个智能图像识别应用程序。该应用程序由一个 Roboflow 工作流提供支持,该工作流集成了一个预训练的 Florence-2 模型,能够识别和定位图像中的特定对象。通过提供文本提示,例如对象的名称或描述,模型被引导以检测和突出显示图像中的目标对象。这种方法利用了多模态 AI 的强大功能,将视觉和语言理解相结合,以执行灵活的、基于提示的对象识别。
创建如下的 Roboflow Workflows。添加 Florence-2 块、VLM as Detector 块、边界框可视化块和标签可视化块。
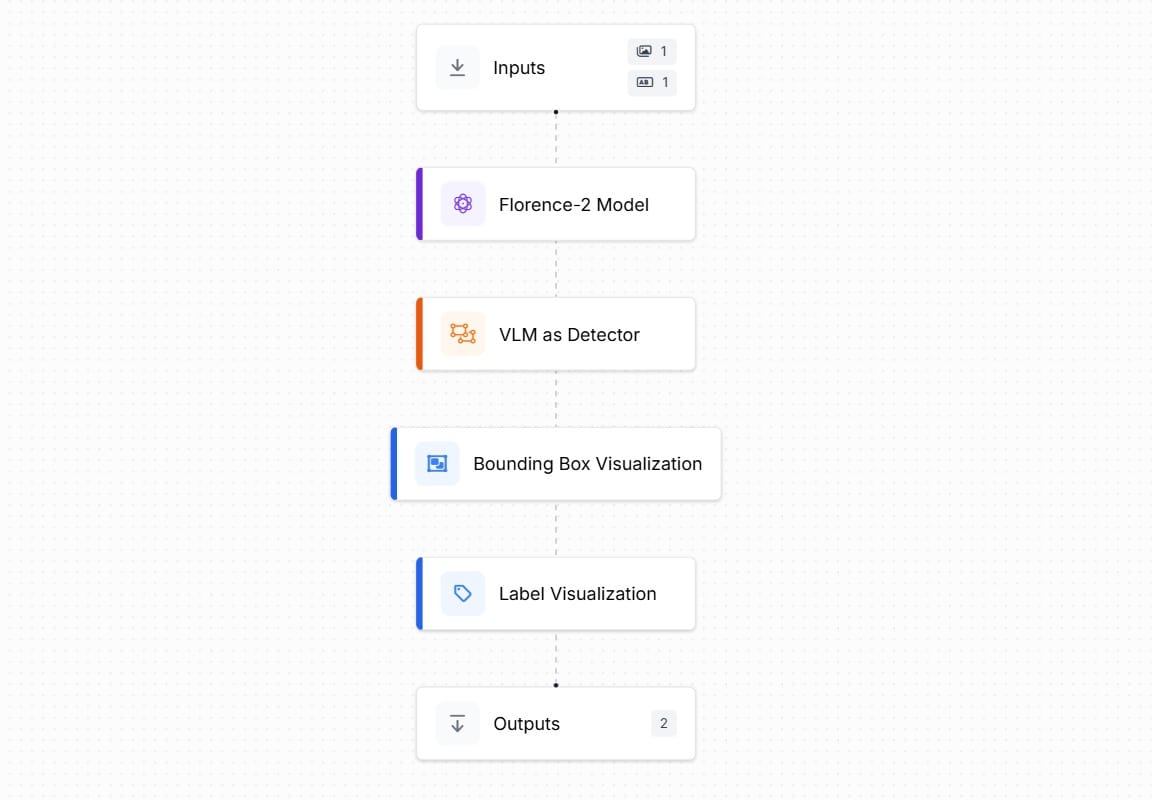
使用 VLM 工作流进行对象检测
在输入块中添加一个文本参数,以指定基于文本的提示以及输入图像。
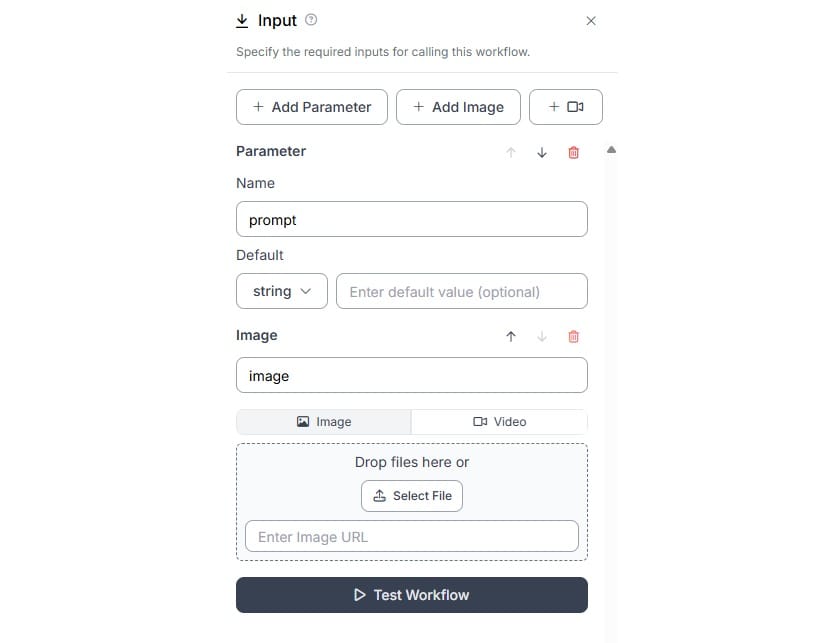
输入块配置
如下配置 Florence-2 块。选择任务类型为“提示对象检测”。将 Prompt 属性与输入块中添加的“prompt”参数绑定。
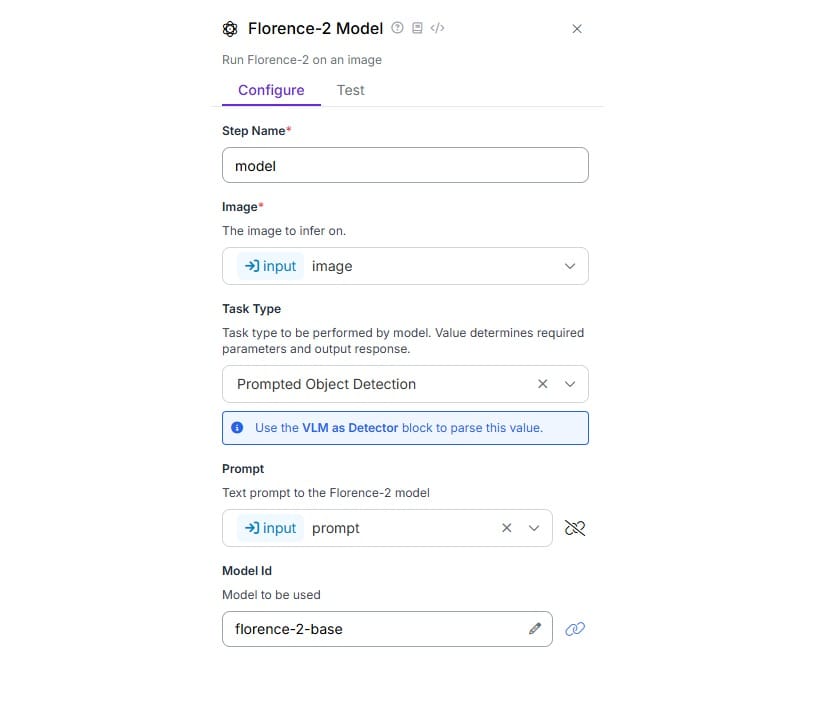
Florence-2 块配置
现在,如下配置 VLM as Detector 块。VLM 输出和类属性设置为来自 Florence-2 块的输出,模型类型属性设置为 Florence-2,任务类型设置为提示对象检测。
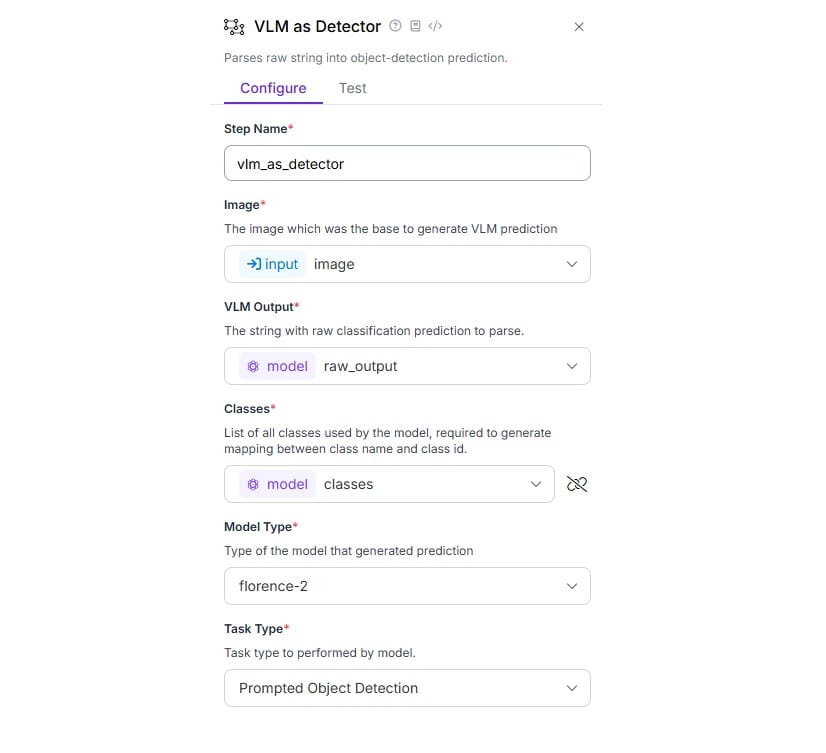
VLM as Detector 锁定配置
通过指定提示并上传输入图像来运行工作流。在这种情况下,提示是“球在哪里?”,输入图像是棒球运动员(击球手)击球的图像。我们想要识别球及其在图像中的位置。
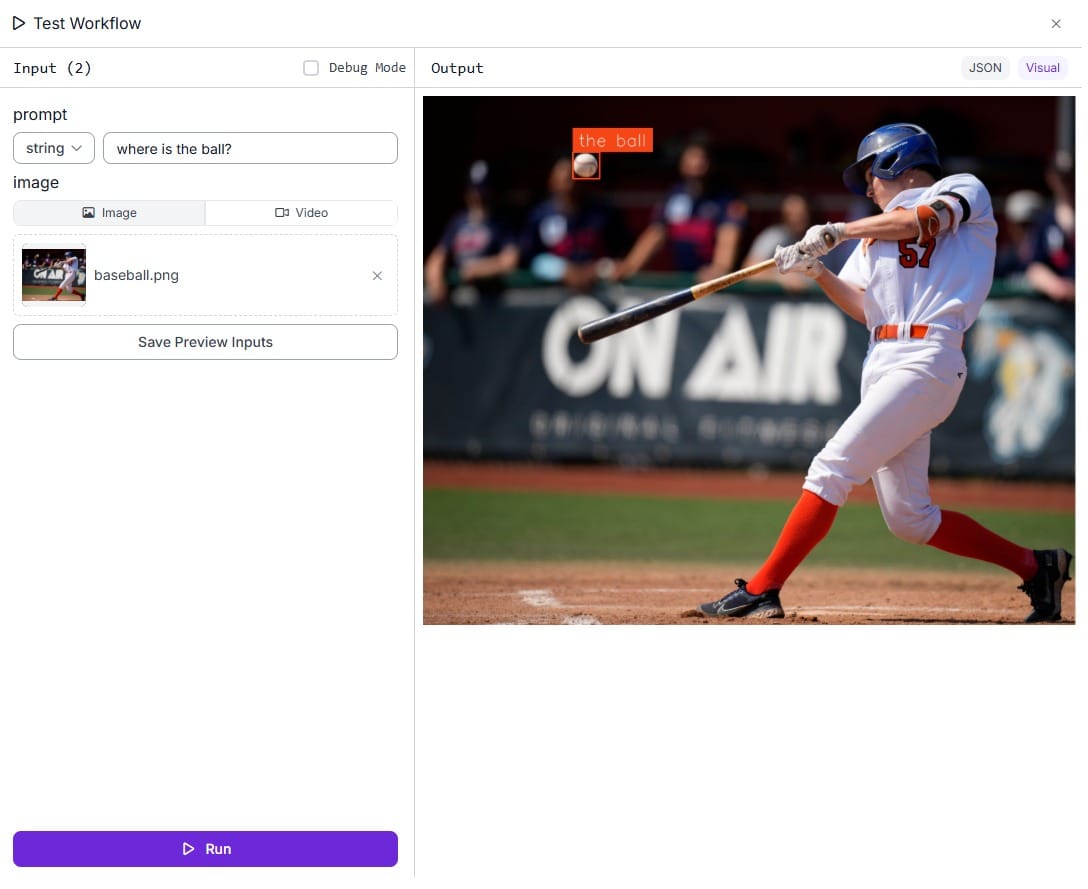
工作流输出
视觉语言模型 (VLM) 通过将视觉理解与自然语言提示相结合,为图像识别提供了一种强大而灵活的方法。VLM 不仅仅依赖于预定义的类,而是允许用户使用简单的文本输入来描述他们想要检测的内容。这使得基于提示的对象检测成为可能,其中模型可以根据给定的描述识别和定位图像中的对象。无论是用于定位特定项目、生成图像标题还是回答视觉问题,VLM 都使图像识别更加直观,更能适应各种现实世界的场景。
图像识别软件
图像识别是计算机视觉的一项强大应用,它使机器能够像人类一样理解和解释视觉数据。借助 Roboflow 等平台,即使没有深厚的编码专业知识,构建和部署智能图像识别系统也变得触手可及。无论是检测原木、识别手势,还是使用视觉语言模型进行基于提示的检测,Roboflow Workflows 都使开发人员能够轻松创建自定义或多模态 AI 管道。这些功能为林业、安防、零售、医疗保健 等行业的实际应用打开了大门。
以下是本博客的主要内容,可帮助您了解和应用使用 Roboflow 的图像识别:
- 图像识别:计算机将图像解释为数值数据,并通过训练,它们学会使用神经网络识别模式和对象。
- 模型类型:有适用于各种任务的不同模型,包括分类、对象检测、分割、关键点检测、手势识别和视觉语言理解。
- Roboflow Workflows:一个无代码/低代码的可视化管道构建器,可让用户链接多种模型类型和功能来创建完整的图像识别系统。
- 预训练模型与自定义模型:Roboflow 两者都支持,可以使用现成的模型,也可以使用 AutoML 在自定义数据集上训练自己的模型。
- 实际应用:从原木计数到实时手势识别和使用 VLM 进行基于提示的对象检测,图像识别具有广泛的用例。
- 灵活部署:Roboflow 支持基于云的、边缘设备 和移动部署,以及用于实时或批量推理的托管 API 和 SDK。
引用此帖子
在您的研究中引用此帖子时,请使用以下条目:
Timothy M.。(2025 年 6 月 10 日)。什么是图像识别?算法和应用。Roboflow 博客:https://blog.roboflow.com/image-recognition/