Gemini 2.5实现多模态大升级|Lumos‑1架构高效生成视频|FantasyPortrait支持多角色动画【AI周报】
Gemini 2.5实现多模态大升级|Lumos‑1架构高效生成视频|FantasyPortrait支持多角色动画【AI周报】

摘要
本周亮点:谷歌发布 Gemini 2.5,全面提升多模态理解、超长上下文与视频推理能力;阿里推出 Lumos‑1,高效自回归视频生成;FantasyPortrait 表达增强驱动多角色动画,重构人像生成上限。详见正文,相关参考链接请见文末。
目录
- Gemini 2.5:多模态、超长上下文与推理能力全面升级的旗舰系列模型
- Lumos‑1:保留标准 LLM 架构的自回归视频生成模型
- CoPart:部件感知的可控 3D 扩散框架
- FantasyPortrait:多角色表情驱动的肖像动画扩散模型
- DreamPoster:图像驱动的一体化海报生成框架
- CharaConsist:DiT模型下的细粒度角色一致性生成
Gemini 2.5:多模态、超长上下文与推理能力全面升级的旗舰系列模型
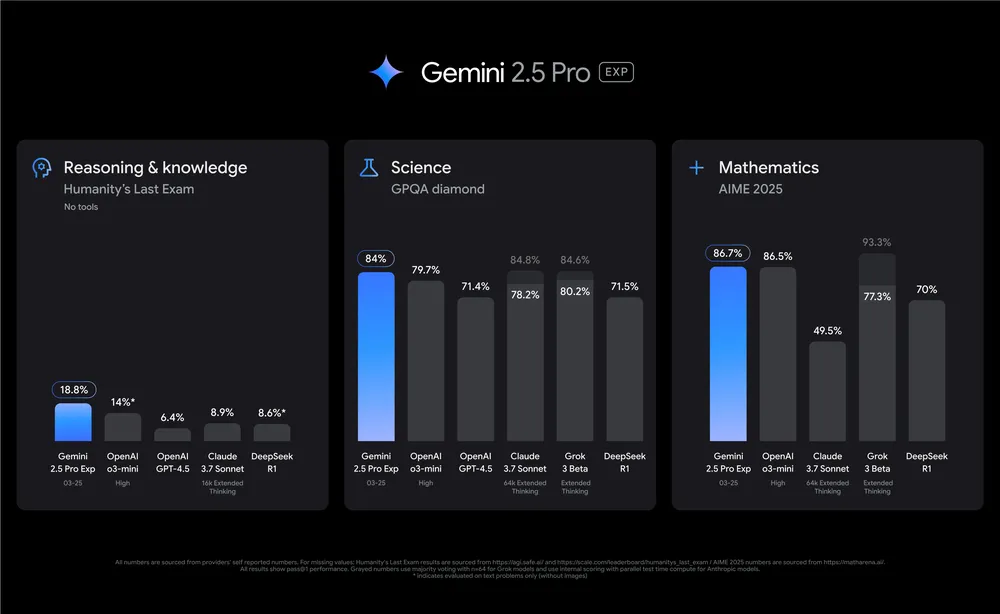
概要:Gemini 2.5 是 谷歌 DeepMind 推出的旗舰级多模态 LLM 系列,包括高性能版本(Pro)和轻量高效版本(Flash/Lite)。该系列具有如下突破:支持混合文本、图像、音频与长达 3 小时的视频输入;引入稀疏 Mixture-of-Experts 架构与“thinking”链式思维机制,实现更强编程与推理能力;其 Pro 版本在 LiveCodeBench、GPQA 等基准上的性能显著超越前代,多模态能力也进一步增强。Gemini 2.5 扩展了上限—兼顾能力与效率选择,成为当前多模态智能体发展的标杆。
标签:#多模态LLM #长上下文 #SparseMoE #推理能力 #视频理解
Lumos‑1:保留标准 LLM 架构的自回归视频生成模型

概要:Lumos‑1 是 阿里巴巴 DAMO Academy 发布的自回归视频生成模型,基于标准 LLM 改造,新增 MM‑RoPE(3D 旋转位置编码)和 AR‑DF(自回归离散扩散强制)机制,实现视觉与时序信息统一建模与高效采样。该模型在仅 48 张 GPU 下训练完成,性能已接近 EMU3、COSMOS-Video2World 等顶级开源视频模型。
标签:#视频生成 #LLM架构 #3DRoPE #自回归扩散 #高效训练
CoPart:部件感知的可控 3D 扩散框架
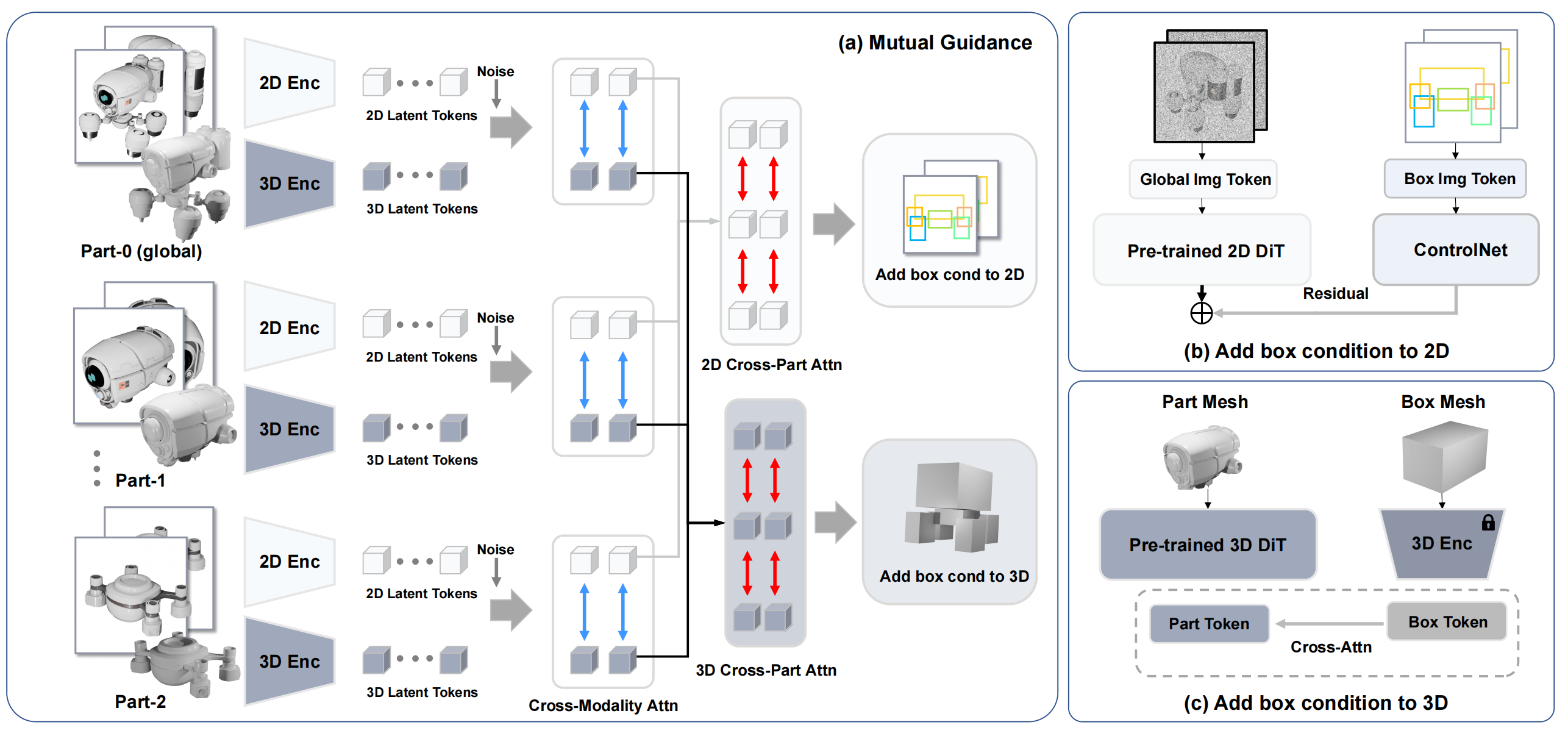
概要:CoPart 是由 港科大, 港中文及商汤研究 联合提出的首个部件级 3D 扩散生成系统。其核心理念借鉴人类设计流程,将一个完整 3D 对象分解为多个“上下文部件 latent”,通过联合 denoising 实现结构一致、语义解耦的多部件生成。相较于传统单 latent 表示,CoPart 支持更丰富细节表达与部件级控制,同时不依赖预分割 mask。研究团队还发布了大规模 PartVerse 部件注释数据集,并通过在 Objaverse 上的实验证明,该方法在部件编辑、可控生成等任务上性能领先。
标签:#3D生成 #部件控制 #扩散模型 #PartVerse数据 #可控编辑
FantasyPortrait:多角色表情驱动的肖像动画扩散模型
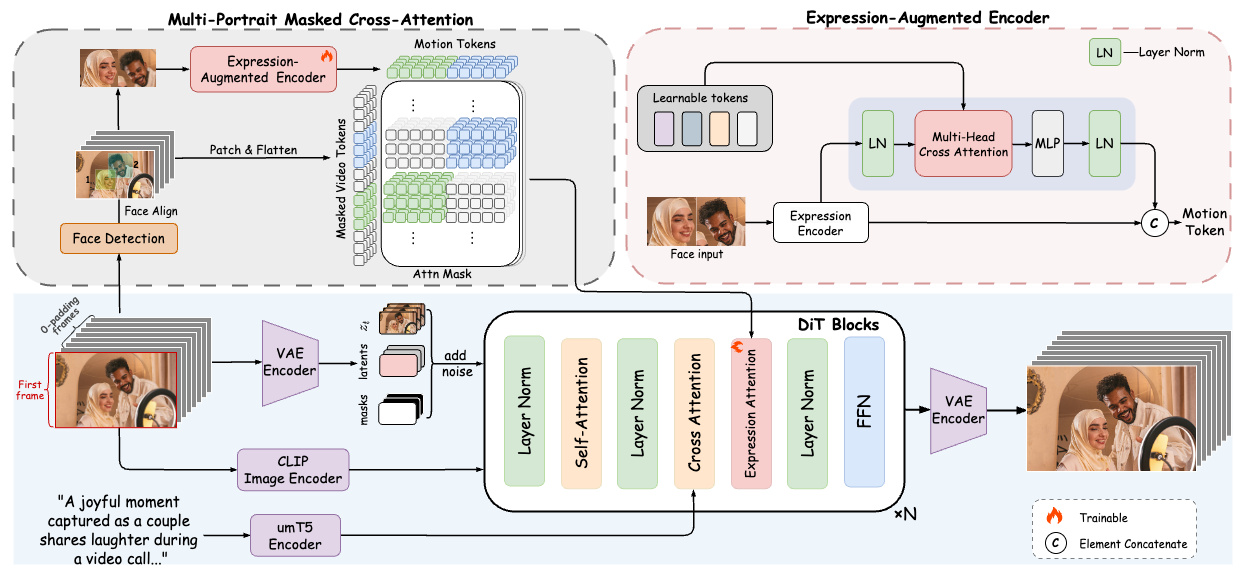
概要:FantasyPortrait 是 高德 和 北邮 提出的扩散 Transformer 框架,擅长从静态肖像生成高保真、多角色、富有表情的动画形式。它引入表达增强机制,通过隐式表示捕捉面部动态;采用遮罩交叉注意力实现多角色控制,避免角色间干扰;构建了 Multi‑Expr 数据集和 ExprBench 基准用于训练与评估。实验表明,该方法在跨角色重定向与多角色场景下显著领先现有技术,并在定量和定性指标上实现先进水平。
标签:#人像动画 #扩散Transformer #多角色控制 #表情增强 #评测基准
DreamPoster:图像驱动的一体化海报生成框架
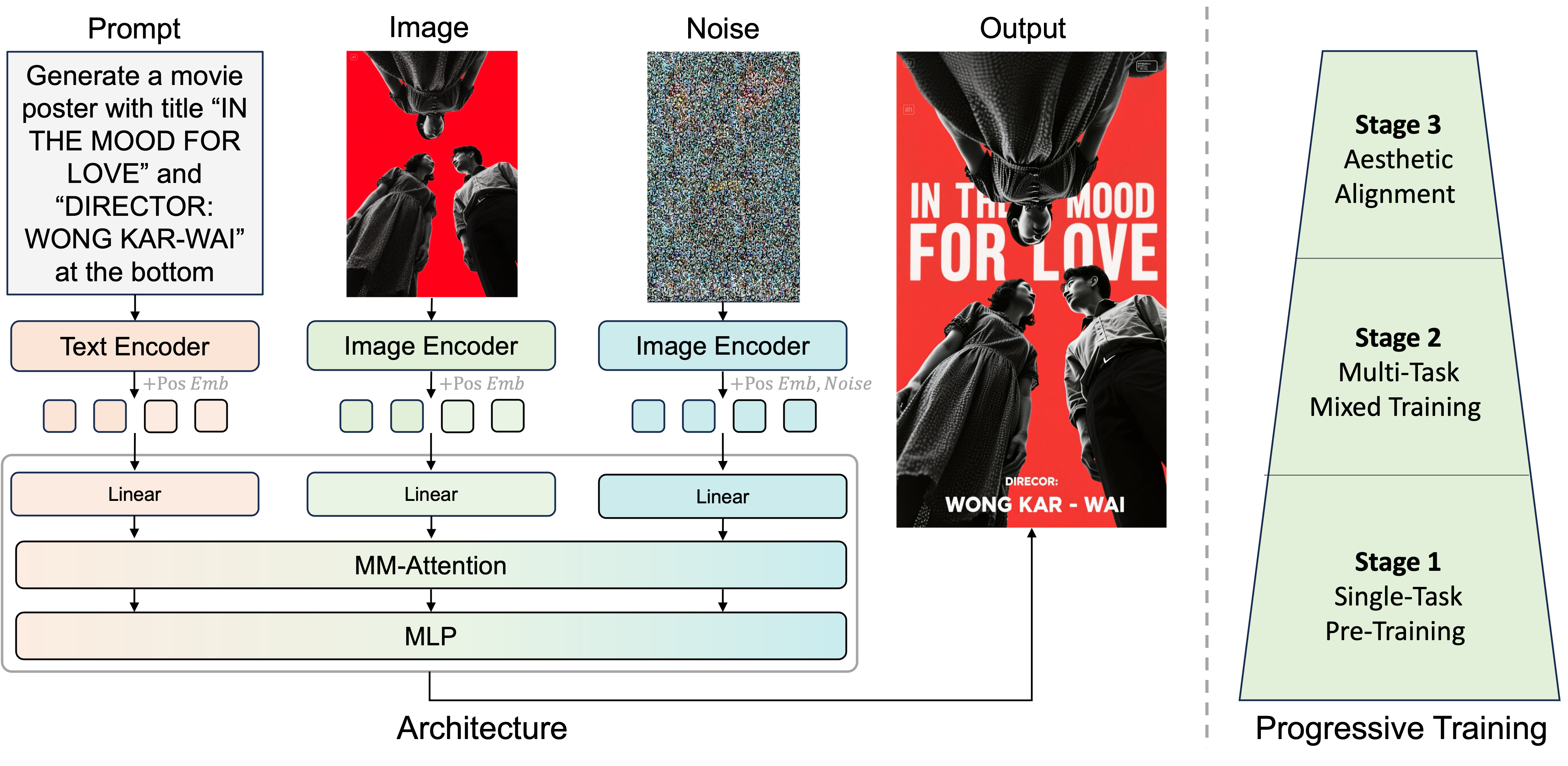
概要:DreamPoster 是由 字节跳动智能创作实验室 推出的文本到图像海报生成系统,能够从用户提供的图像与文本提示出发,自动设计高质量、布局合理的海报。其方法基于联合布局与风格控制的多阶段流程,融合视觉分析、版式规划、文字与图像元素排布以及风格统一处理,全部由 Seedream3.0 基础模型驱动。实验表明,DreamPoster 能生成分辨率灵活、视觉一致的专业性海报,是内容创作者与设计师的高效工具。
标签:#文本到图像 #海报设计 #布局规划 #风格统一 #Seedream3.0
CharaConsist:DiT模型下的细粒度角色一致性生成

概要:CharaConsist 是由 北交大 和 复旦大学等机构提出的首个针对 DiT 模型的细粒度角色一致性生成方法。该方法通过“点跟踪注意力”和“自适应 token 合并”机制,实现对角色在连贯镜头、不同背景及不同分辨率下的面部和背景两个维度的一致性控制。不同于仅调整整体风格的一致性算法,CharaConsist 能精细保持角色细节和语境一致,无需额外训练或模块,直接利用预训练 DiT 模型就能生成高度稳定的角色序列,适合角色叙事、广告拍摄等场景。
标签:#角色一致性 #DiT #自监督生成 #点跟踪注意力 #预训练