
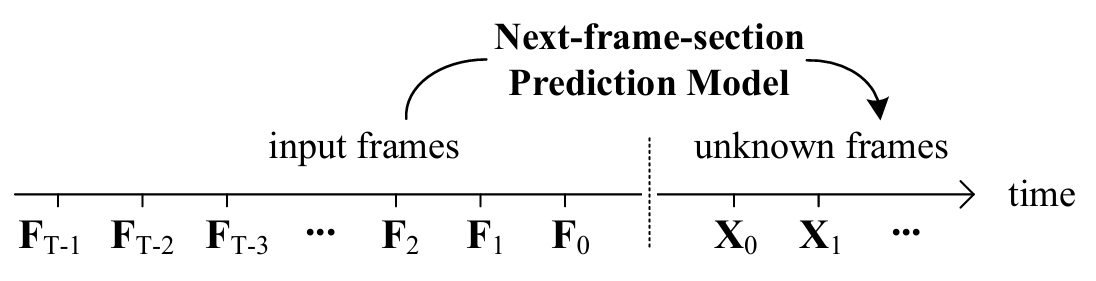
【论文精读】FramePack:在下一帧预测视频生成模型中打包输入帧上下文
![]()
摘要
FramePack由斯坦福大学张吕敏等提出,是一种输入预处理模块,可无缝集成到主流视频扩散模型(如混元视频模型),通过自适应帧压缩和反漂移采样,有效提升长时序一致性和生成质量,支持13B模型在6GB显存上流畅生成长视频,显著降低算力门槛。
目录
背景与研究目标
视频生成领域,基于"下一帧预测"的扩散模型因其逐帧生成能力受到关注。但此类模型普遍面临两大核心挑战:
- 遗忘(Forgetting):模型难以长期保持时序一致性,导致角色、场景等随时间漂移。
- 漂移(Drifting):误差逐帧累积,后续帧画质下降,出现模糊、失真等问题。
传统方法往往顾此失彼:增加历史帧输入可缓解遗忘,却加剧漂移;减少依赖则反之。加之 Transformer 架构的计算复杂度,直接扩展上下文帧数并不可行。
方法与创新点
FramePack 作为输入端的预处理模块,作用于历史帧输入阶段。在不改变主干网络结构的前提下,通过以下两大创新提升视频生成效果:
FramePack首先对所有历史帧进行压缩和重排,将处理后的帧拼接为统一长度的上下文序列,作为主干模型的输入。
1. 自适应帧压缩(Adaptive Frame Compression)
FramePack 利用视频帧间冗余,对不同时间距离的帧采用不同压缩率,远帧高压缩,近帧低压缩。通过调整 Transformer 输入层 patchify kernel size,实现帧级别分辨率动态分配,保证总上下文长度受控。
多帧输入的patchify压缩示意,近帧高分辨率,远帧低分辨率。
FramePack 通过对历史帧进行分级压缩,严格控制输入上下文长度。具体地,对第 $i$ 个历史帧,压缩后长度为: $\phi(F_i) = \frac{L_f}{\lambda^i}$ 其中 $L_f$ 为单帧 patch 数,$\lambda>1$ 为压缩率。总上下文长度为:
$L = S \cdot L_f + L_f \cdot \sum_{i=0}^{T-1} \frac{1}{\lambda^i} = S \cdot L_f + L_f \cdot \frac{1-1/\lambda^T}{1-1/\lambda}$
当 $T\to\infty$ 时,上下文长度收敛到 $L = (S + \frac{\lambda}{\lambda-1}) L_f$ 这保证了无论历史帧数多大,计算量都不会爆炸。
不同帧可采用不同的压缩调度策略(FramePack Scheduling),如几何级压缩、均匀压缩等,灵活适配不同场景和任务需求。

多种帧压缩调度方式,支持灵活分配算力资源。
不同压缩率的 patchify kernel(如(2,4,4)、(4,8,8)等)对应独立的输入投影层参数,训练时通过插值初始化,保证不同压缩率下特征分布稳定。
对于极长视频,尾部帧可采用三种处理方式:直接删除、每帧增加一个像素、全局池化。不同压缩率下的 RoPE(Rotary Position Embedding)需通过平均池化对齐,确保时序信息一致。
2. 反漂移采样(Anti-Drifting Sampling)
FramePack 提出创新采样策略:
- Vanilla:传统顺序采样,误差易累积。
- Anti-Drifting:先生成端点帧,再补中间帧,利用双向上下文提升一致性。
- Inverted Anti-Drifting:逆序采样,适合 image-to-video,能更好保持高质量起始帧特征。
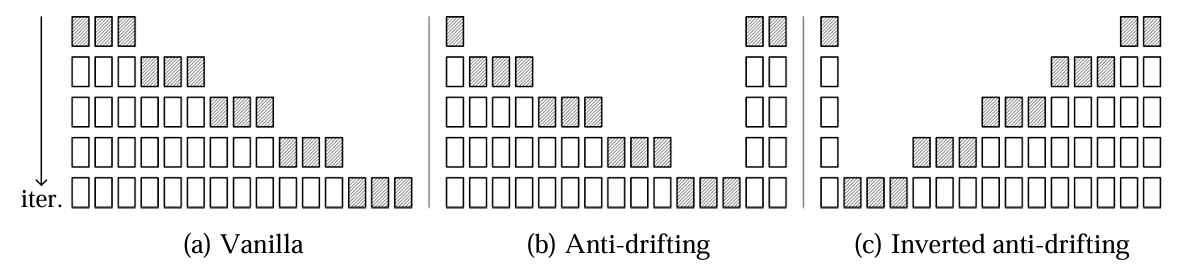
不同采样方式对比,反漂移采样显著降低误差累积。
FramePack 支持 vanilla、anti-drifting、inverted anti-drifting 三种采样顺序。后两者通过双向上下文有效抑制漂移。为支持非连续帧采样,RoPE 位置编码需做随机访问调整。
实验与结果分析
- 兼容性:FramePack 可直接微调 HunyuanVideo、Wan 等主流视频扩散模型。
- 性能提升:
- 漂移抑制:Inverted Anti-Drifting 采样在多项指标和主观评价中表现最佳。
- 画质提升:支持更大 batch size,训练更高效,生成视频更长且一致性更好。
- 效率提升:6GB 显存即可驱动 13B 模型生成 1 分钟视频,极大降低硬件门槛。
多维度评测指标
评测指标包括清晰度(MUSIQ)、美学(LAION)、运动(VFI)、动态(RAFT)、语义一致性(ViCLIP)、解剖结构(ViT)、身份一致性(ArcFace+RetinaFace)等。
漂移度量
论文提出"start-end contrast"指标,度量视频首尾在各项指标上的差异,直接反映漂移严重程度。 $\Delta_{\text{drift}}^{M}(V) = |M(V_{\text{start}}) - M(V_{\text{end}})|$
与主流方法对比
FramePack 在与 anchor frame、causal attention、noisy history、history guidance 等主流方案对比中,在多项指标和人类评价中均表现最佳。
消融实验
消融实验采用统一命名规范(如 td_f16k4f4k2f1k1_g9),明确每种压缩调度与采样方式,便于复现和对比。不同压缩策略和采样方法对性能影响显著,最佳配置为几何级压缩+反漂移采样。
模型启发与方法延伸
- 通用性:FramePack 作为输入预处理模块,可迁移至各类时序生成任务。
- 与现有方法对比:相比单纯增加上下文或改进主干结构,FramePack以更低成本实现更优时序一致性。
- 未来方向:可与更高效注意力机制、长时序建模方法结合,进一步提升超长视频生成能力。
结论与未来展望
FramePack 有效打破了“遗忘-漂移”二难困境,为视频生成模型带来更长时序、更高一致性和更低算力门槛。其输入端插件式设计,支持多种压缩调度和采样变体,适配不同场景和需求,便于集成到各类主流视频扩散模型。未来,FramePack 可与更高效注意力机制、长时序建模方法结合,进一步提升超长视频生成能力,并有望在内容创作、虚拟现实等实际应用中发挥更大作用。