Magic 1-For-1高效生成1分钟视频|Zonos最强开源文本转语音|Light-A-Video零样本重光照视频生成【AI周报】
Magic 1-For-1高效生成1分钟视频|Zonos最强开源文本转语音|Light-A-Video零样本重光照视频生成【AI周报】

摘要
本周亮点:Whisk将概念嵌入场景并风格迁移;Zonos领先的开源文本转语音模型;Light-A-Video无需训练即可重光照视频;Goku 提供高效的视频生成方案;Data Formulator让数据可视化更智能。详情见正文。
目录
- Whisk:Google推出的图像生成工具
- Data Formulator:Microsoft的数据可视化工具
- Goku:高效的多模态学习框架
- Light-A-Video:无需训练的渐进式视频重光照框架
- Zonos:领先的开源文本转语音模型
- Magic 1-For-1:高效生成一分钟视频片段
Whisk:Google推出的图像生成工具

概要:Google推出了名为Whisk的AI工具,允许用户通过输入其他图像作为提示来生成新图像。用户可以选择多张图像来定义主题、场景和风格,或结合图像和文本提示来创建所需的输出。Whisk还提供了一个功能,通过骰子图标为提示生成AI图像。生成图像后,用户可以下载、收藏或通过编辑提示进行优化。Whisk旨在实现快速的视觉探索,而非详细的图像编辑。
标签:#Whisk #Google #图像生成 #风格迁移
Data Formulator:Microsoft的数据可视化工具

概要:Data-Formulator 是由 微软研究院 开发的一款新型工具,旨在利用大型语言模型(LLM)来简化数据转换和可视化的过程。该工具通过自然语言指令,自动生成数据处理脚本和可视化方案,降低了数据分析的门槛。用户无需具备深厚的编程技能,即可轻松实现复杂的数据操作和图表生成。Data-Formulator 的推出标志着数据科学领域向自动化和智能化迈出了重要一步,为数据从业者提供了更高效的工作方式。
标签:#Data-Formulator #微软研究院 #LLM #数据转换 #数据可视化
Goku:高效的多模态学习框架

概要:Goku 是由 港大 和 字节跳动 开发的一款多模态学习框架,旨在提高 AI 模型对不同模态数据(文本、图像、视频等)的理解和生成能力。该框架结合了 Transformer 架构和流式训练方法,实现了高效的文本到图像(T2I)、文本到视频(T2V)以及图像到视频(I2V)任务。Goku 采用了 Patch n’ Pack 技术优化计算效率,并在 VBench、GenEval 等基准测试中取得了领先的表现。该框架的推出为多模态 AI 研究提供了新思路,并支持开源社区的进一步优化和扩展。
标签:#Goku #多模态学习 #文本到图像 #文本到视频 #Transformer #AI框架
Light-A-Video:无需训练的渐进式视频重光照框架
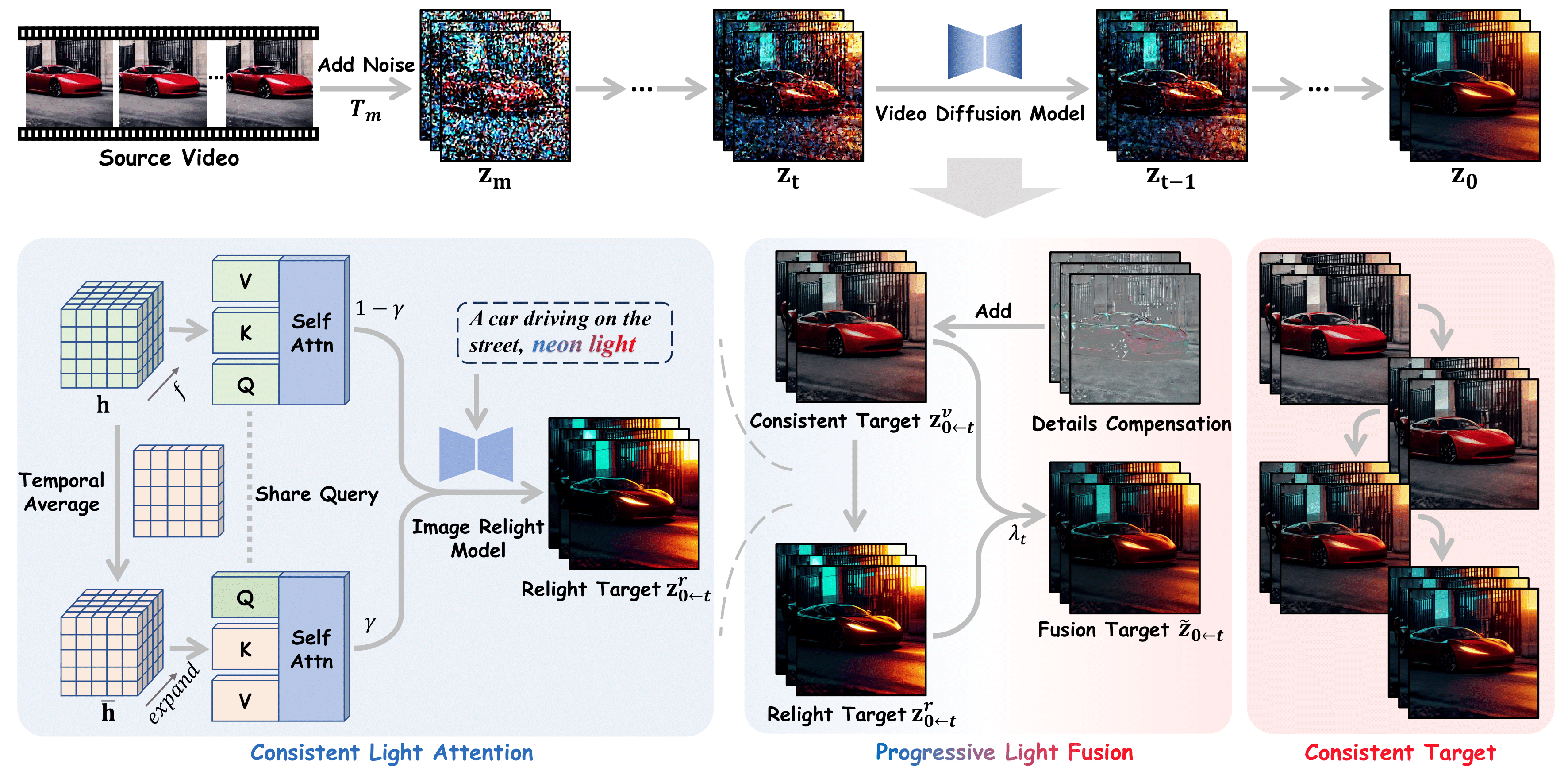
概要:Light-A-Video 是由上海交通大学和上海人工智能实验室等机构的研究人员提出的一个无需训练的视频重光照框架。该方法基于预训练的图像重光照模型(如 IC-Light)和视频扩散模型(如 CogVideoX、AnimateDiff),通过引入一致光注意力(Consistent Light Attention,CLA)模块和渐进式光融合(Progressive Light Fusion,PLF)策略,实现了视频的零样本光照控制。CLA 模块增强了自注意力层中的跨帧交互,稳定了背景光源的生成;PLF 策略利用光传输独立性的物理原理,在源视频和重光照视频之间进行线性融合,确保光照在时间维度上的平滑过渡。实验结果表明,Light-A-Video 在提高重光照视频的时间一致性和图像质量方面表现出色,确保了帧间光照过渡的连贯性。
标签:#Light-A-Video #视频重光照 #零样本学习 #一致光注意力 #渐进式光融合
Zonos:领先的开源文本转语音模型

概要:Zonos 是由 Zyphra 开发的开源文本转语音(TTS)模型。该模型在超过 20 万小时的多语言语音数据上训练,能够生成高质量、富有表现力的语音输出。Zonos 支持从文本提示生成自然语音,并可通过提供 5 至 30 秒的语音样本实现高保真语音克隆。其条件设置还允许对语速、音高变化、音频质量以及情感(如快乐、恐惧、悲伤和愤怒)进行精细控制。模型原生输出 44kHz 的语音,支持包括中文在内的多种语言。用户可以通过参考链接里在线demo在线体验该模型的功能。
标签:#Zonos #文本转语音 #语音克隆 #多语言支持 #开源模型
Magic 1-For-1:高效生成一分钟视频片段

概要:Magic 1-For-1 是由 北京大学 和 Hedra Inc. 合作开发的一种高效视频生成模型。该模型将文本到视频的生成任务分解为两个子任务:文本到图像生成和图像到视频生成,从而优化内存使用并减少推理延迟。在训练过程中,Magic 1-For-1 采用多模态先验条件注入、扩散步骤蒸馏和模型量化等技术,加速模型收敛并降低计算成本。实验结果表明,该模型能够在不到一分钟的时间内生成高质量的一分钟视频片段,显著提升了视频生成的效率和质量。
标签:#Magic1For1 #视频生成 #高效模型 #北京大学 #HedraInc