在消费级硬件上对 FLUX.1-dev 进行(LoRA)微调
在消费级硬件上对 FLUX.1-dev 进行(LoRA)微调
提示
在我们之前的文章《在 Diffusers 中探索量化后端》中,我们深入研究了各种量化技术如何缩小像 FLUX.1-dev 这样的扩散模型,使它们在_推理_方面显著更易于访问,而不会大幅降低性能。我们看到了 bitsandbytes、torchao 和其他技术如何减少生成图像时的内存占用。
执行推理很酷,但要让这些模型真正成为我们自己的,我们还需要能够对它们进行微调。因此,在这篇文章中,我们将探讨在单个 GPU 上以不到 10GB 显存的峰值内存使用量进行这些模型的高效微调。本文将指导您使用 diffusers 库通过 QLoRA 对 FLUX.1-dev 进行微调。我们将展示在 NVIDIA RTX 4090 上的结果。我们还将重点介绍如何在兼容硬件上使用 torchao 的 FP8 训练进一步优化速度。
目录
- 数据集
- FLUX 架构
- 使用
diffusers对 FLUX.1-dev 进行 QLoRA 微调 - 使用
torchao进行 FP8 微调 - 使用训练好的 LoRA 适配器进行推理
- 在 Google Colab 上运行
- 结论
数据集
我们的目标是对 black-forest-labs/FLUX.1-dev 进行微调,使其采用 Alphonse Mucha 的艺术风格,使用一个小型数据集。
FLUX 架构
该模型由三个主要组件组成:
- 文本编码器(CLIP 和 T5)
- Transformer(主模型 - Flux Transformer)
- 变分自编码器(VAE)
在我们的 QLoRA 方法中,我们专门专注于微调 transformer 组件。文本编码器和 VAE 在整个训练过程中保持冻结状态。
使用 diffusers 对 FLUX.1-dev 进行 QLoRA 微调
我们使用了一个 diffusers 训练脚本(稍作修改,来自 https://github.com/huggingface/diffusers/blob/main/examples/research_projects/flux_lora_quantization/train_dreambooth_lora_flux_miniature.py),专为 FLUX 模型的 DreamBooth 风格 LoRA 微调而设计。此外,还有一个简化版本来重现本博文中的结果(并在 Google Colab 中使用),可在这里获得。让我们检查 QLoRA 和内存效率的关键部分:
关键优化技术
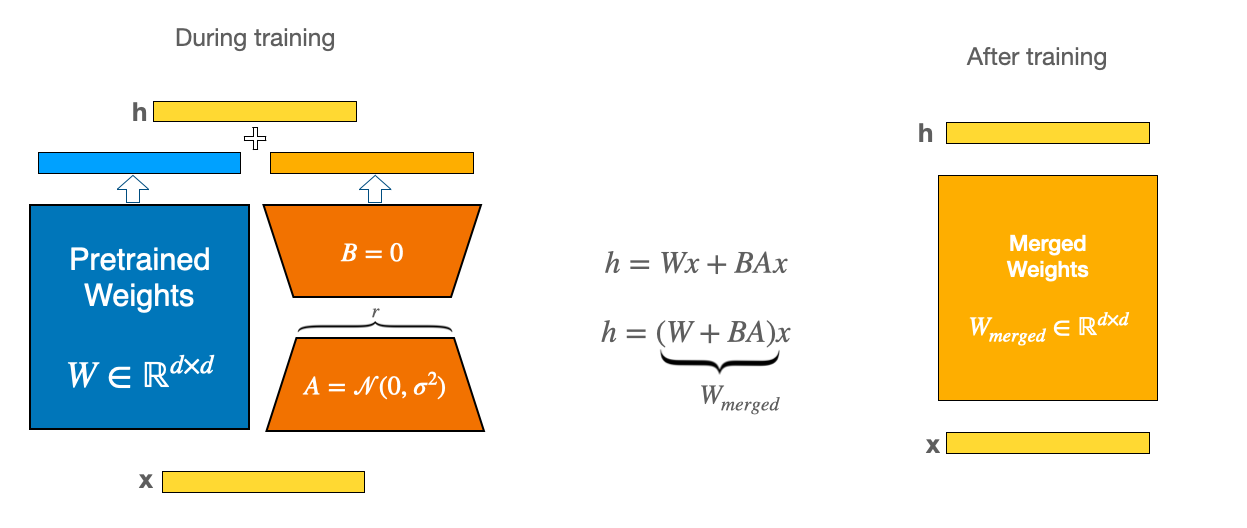
LoRA(低秩适应)深入解析:LoRA 通过使用低秩矩阵跟踪权重更新,使模型训练更加高效。LoRA 不是更新完整的权重矩阵 W,而是学习两个较小的矩阵 A 和 B。模型权重的更新是 ΔW = BA,其中 A ∈ R^(r×k) 且 B ∈ R^(d×r)。数字 r(称为_秩_)比原始维度小得多,这意味着要更新的参数更少。最后,α 是 LoRA 激活的缩放因子。这影响 LoRA 对更新的影响程度,通常设置为与 r 相同的值或其倍数。它有助于平衡预训练模型和 LoRA 适配器的影响。有关概念的一般介绍,请查看我们之前的博客文章:使用 LoRA 进行高效的稳定扩散微调。
QLoRA:效率的动力源:QLoRA 通过首先以量化格式(通常通过 bitsandbytes 进行 4 位)加载预训练基础模型来增强 LoRA,大幅减少基础模型的内存占用。然后在这个量化基础上训练 LoRA 适配器(通常在 FP16/BF16 中)。这大大降低了保存基础模型所需的显存。
例如,在 HiDream 的 DreamBooth 训练脚本中,使用 bitsandbytes 的 4 位量化将 LoRA 微调的峰值内存使用量从约 60GB 降至约 37GB,质量降低可忽略不计。我们在这里应用的正是同样的原理,在消费级硬件上微调 FLUX.1。
8 位优化器(AdamW): 标准 AdamW 优化器为每个参数维护 32 位(FP32)的一阶和二阶矩估计,这消耗大量内存。8 位 AdamW 使用块级量化将优化器状态存储在 8 位精度中,同时保持训练稳定性。与标准 FP32 AdamW 相比,此技术可将优化器内存使用量减少约 75%。在脚本中启用它很简单:
# 检查 --use_8bit_adam 标志
if args.use_8bit_adam:
optimizer_class = bnb.optim.AdamW8bit
else:
optimizer_class = torch.optim.AdamW
optimizer = optimizer_class(
params_to_optimize,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)梯度检查点: 在前向传播期间,中间激活通常为反向传播梯度计算而存储。梯度检查点通过仅存储某些_检查点激活_并在反向传播期间重新计算其他激活,来用计算换取内存。
if args.gradient_checkpointing:
transformer.enable_gradient_checkpointing()缓存潜在变量: 这种优化技术在训练开始前通过 VAE 编码器预处理所有训练图像。它将生成的潜在表示存储在内存中。在训练期间,不是即时编码图像,而是直接使用缓存的潜在变量。这种方法提供两个主要好处:
- 消除训练期间冗余的 VAE 编码计算,加速每个训练步骤
- 允许在缓存后完全从 GPU 内存中移除 VAE。权衡是增加 RAM 使用量来存储所有缓存的潜在变量,但对于小数据集来说,这通常是可管理的。
# 如果设置了标志,则在训练前缓存潜在变量
if args.cache_latents:
latents_cache = []
for batch in tqdm(train_dataloader, desc="Caching latents"):
with torch.no_grad():
batch["pixel_values"] = batch["pixel_values"].to(
accelerator.device, non_blocking=True, dtype=weight_dtype
)
latents_cache.append(vae.encode(batch["pixel_values"]).latent_dist)
# 不再需要 VAE,释放其内存
del vae
free_memory()设置 4 位量化(BitsAndBytesConfig):
本节演示基础模型的 QLoRA 配置:
# 根据混合精度确定计算数据类型
bnb_4bit_compute_dtype = torch.float32
if args.mixed_precision == "fp16":
bnb_4bit_compute_dtype = torch.float16
elif args.mixed_precision == "bf16":
bnb_4bit_compute_dtype = torch.bfloat16
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=bnb_4bit_compute_dtype,
)
transformer = FluxTransformer2DModel.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="transformer",
quantization_config=nf4_config,
torch_dtype=bnb_4bit_compute_dtype,
)
# 为 k 位训练准备模型
transformer = prepare_model_for_kbit_training(transformer, use_gradient_checkpointing=False)
# 如果设置了参数,梯度检查点稍后通过 transformer.enable_gradient_checkpointing() 启用定义 LoRA 配置(LoraConfig): 适配器被添加到量化的 transformer:
transformer_lora_config = LoraConfig(
r=args.rank,
lora_alpha=args.rank,
init_lora_weights="gaussian",
target_modules=["to_k", "to_q", "to_v", "to_out.0"], # FLUX 注意力块
)
transformer.add_adapter(transformer_lora_config)
print(f"trainable params: {transformer.num_parameters(only_trainable=True)} || all params: {transformer.num_parameters()}")
# trainable params: 4,669,440 || all params: 11,906,077,760只有这些 LoRA 参数变为可训练的。
预计算文本嵌入(CLIP/T5)
在启动 QLoRA 微调之前,我们可以通过一次性缓存文本编码器的输出来节省大量显存和计算时间。
在训练时,数据加载器只需读取缓存的嵌入,而不是重新编码标题,因此 CLIP/T5 编码器永远不必驻留在 GPU 内存中。
代码
# https://github.com/huggingface/diffusers/blob/main/examples/research_projects/flux_lora_quantization/compute_embeddings.py
import argparse
import pandas as pd
import torch
from datasets import load_dataset
from huggingface_hub.utils import insecure_hashlib
from tqdm.auto import tqdm
from transformers import T5EncoderModel
from diffusers import FluxPipeline
MAX_SEQ_LENGTH = 77
OUTPUT_PATH = "embeddings.parquet"
def generate_image_hash(image):
return insecure_hashlib.sha256(image.tobytes()).hexdigest()
def load_flux_dev_pipeline():
id = "black-forest-labs/FLUX.1-dev"
text_encoder = T5EncoderModel.from_pretrained(id, subfolder="text_encoder_2", load_in_8bit=True, device_map="auto")
pipeline = FluxPipeline.from_pretrained(
id, text_encoder_2=text_encoder, transformer=None, vae=None, device_map="balanced"
)
return pipeline
@torch.no_grad()
def compute_embeddings(pipeline, prompts, max_sequence_length):
all_prompt_embeds = []
all_pooled_prompt_embeds = []
all_text_ids = []
for prompt in tqdm(prompts, desc="Encoding prompts."):
(
prompt_embeds,
pooled_prompt_embeds,
text_ids,
) = pipeline.encode_prompt(prompt=prompt, prompt_2=None, max_sequence_length=max_sequence_length)
all_prompt_embeds.append(prompt_embeds)
all_pooled_prompt_embeds.append(pooled_prompt_embeds)
all_text_ids.append(text_ids)
max_memory = torch.cuda.max_memory_allocated() / 1024 / 1024 / 1024
print(f"Max memory allocated: {max_memory:.3f} GB")
return all_prompt_embeds, all_pooled_prompt_embeds, all_text_ids
def run(args):
dataset = load_dataset("Norod78/Yarn-art-style", split="train")
image_prompts = {generate_image_hash(sample["image"]): sample["text"] for sample in dataset}
all_prompts = list(image_prompts.values())
print(f"{len(all_prompts)=}")
pipeline = load_flux_dev_pipeline()
all_prompt_embeds, all_pooled_prompt_embeds, all_text_ids = compute_embeddings(
pipeline, all_prompts, args.max_sequence_length
)
data = []
for i, (image_hash, _) in enumerate(image_prompts.items()):
data.append((image_hash, all_prompt_embeds[i], all_pooled_prompt_embeds[i], all_text_ids[i]))
print(f"{len(data)=}")
# 创建 DataFrame
embedding_cols = ["prompt_embeds", "pooled_prompt_embeds", "text_ids"]
df = pd.DataFrame(data, columns=["image_hash"] + embedding_cols)
print(f"{len(df)=}")
# 将嵌入列表转换为数组(用于正确存储在 parquet 中)
for col in embedding_cols:
df[col] = df[col].apply(lambda x: x.cpu().numpy().flatten().tolist())
# 将 dataframe 保存到 parquet 文件
df.to_parquet(args.output_path)
print(f"Data successfully serialized to {args.output_path}")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--max_sequence_length",
type=int,
default=MAX_SEQ_LENGTH,
help="用于计算嵌入的最大序列长度。越多计算成本越高。",
)
parser.add_argument("--output_path", type=str, default=OUTPUT_PATH, help="序列化 parquet 文件的路径。")
args = parser.parse_args()
run(args)如何使用
python compute_embeddings.py \
--max_sequence_length 77 \
--output_path embeddings_alphonse_mucha.parquet通过将此与缓存的 VAE 潜在变量(--cache_latents)结合,您可以将活动模型精简为仅量化的 transformer + LoRA 适配器,使整个微调舒适地保持在 10GB GPU 内存以下。
设置和结果
在此演示中,我们利用 NVIDIA RTX 4090(24GB 显存)来探索其性能。使用 accelerate 的完整训练命令如下所示。
# 您需要首先预计算文本嵌入。请参阅 diffusers 仓库。
# https://github.com/huggingface/diffusers/tree/main/examples/research_projects/flux_lora_quantization
accelerate launch --config_file=accelerate.yaml \
train_dreambooth_lora_flux_miniature.py \
--pretrained_model_name_or_path="black-forest-labs/FLUX.1-dev" \
--data_df_path="embeddings_alphonse_mucha.parquet" \
--output_dir="alphonse_mucha_lora_flux_nf4" \
--mixed_precision="bf16" \
--use_8bit_adam \
--weighting_scheme="none" \
--width=512 \
--height=768 \
--train_batch_size=1 \
--repeats=1 \
--learning_rate=1e-4 \
--guidance_scale=1 \
--report_to="wandb" \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \ # 当硬件有超过 16GB 时可以去掉检查点
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--cache_latents \
--rank=4 \
--max_train_steps=700 \
--seed="0"RTX 4090 配置: 在我们的 RTX 4090 上,我们使用 train_batch_size 为 1,gradient_accumulation_steps 为 4,mixed_precision="bf16",gradient_checkpointing=True,use_8bit_adam=True,LoRA rank 为 4,分辨率为 512x768。使用 cache_latents=True 缓存潜在变量。
内存占用(RTX 4090):
- QLoRA: QLoRA 微调的峰值显存使用量约为 9GB。
- BF16 LoRA: 在相同设置上运行标准 LoRA(基础 FLUX.1-dev 在 FP16 中)消耗 26GB 显存。
- BF16 完全微调: 在没有内存优化的情况下,估计约为 120GB 显存。
训练时间(RTX 4090): 在 Alphonse Mucha 数据集上进行 700 步微调,在 RTX 4090 上使用 train_batch_size 为 1 和分辨率为 512x768 大约需要 41 分钟。
输出质量: 最终衡量标准是生成的艺术品。以下是我们在 derekl35/alphonse-mucha-style 数据集上训练的 QLoRA 微调模型的样本:
此表比较了主要的 bf16 精度结果。微调的目标是教会模型 Alphonse Mucha 的独特风格。
| 提示 | 基础模型输出 | QLoRA 微调输出(Mucha 风格) |
|---|---|---|
| "宁静的黑发女子,月光百合,漩涡植物,alphonse mucha style" |  |  |
| "池塘中的小狗,alphonse mucha style" |  |  |
| "华丽的狐狸,佩戴秋叶和浆果的项圈,置身于森林植物的挂毯中,alphonse mucha style" |  |  |
微调后的模型很好地捕捉到了 Mucha 标志性的新艺术风格,这在装饰图案和独特的调色板中表现得很明显。QLoRA 过程在学习新风格的同时保持了出色的保真度。
fp16 比较
结果几乎相同,表明 QLoRA 在 fp16 和 bf16 混合精度下都表现有效。
模型比较:基础模型 vs. QLoRA 微调(fp16)
| 提示 | 基础模型输出 | QLoRA 微调输出(Mucha 风格) |
|---|---|---|
| "宁静的黑发女子,月光百合,漩涡植物,alphonse mucha style" |  |  |
| "池塘中的小狗,alphonse mucha style" |  |  |
| "华丽的狐狸,佩戴秋叶和浆果的项圈,置身于森林植物的挂毯中,alphonse mucha style" |  |  |
使用 torchao 进行 FP8 微调
对于拥有计算能力 8.9 或更高的 NVIDIA GPU(如 H100、RTX 4090)的用户,可以通过 torchao 库利用 FP8 训练实现更高的速度效率。
我们在 H100 SXM GPU 上使用稍作修改的 diffusers-torchao 训练脚本对 FLUX.1-dev LoRA 进行了微调。使用了以下命令:
accelerate launch train_dreambooth_lora_flux.py \
--pretrained_model_name_or_path=black-forest-labs/FLUX.1-dev \
--dataset_name=derekl35/alphonse-mucha-style --instance_prompt="a woman, alphonse mucha style" --caption_column="text" \
--output_dir=alphonse_mucha_fp8_lora_flux \
--mixed_precision=bf16 --use_8bit_adam \
--weighting_scheme=none \
--height=768 --width=512 --train_batch_size=1 --repeats=1 \
--learning_rate=1e-4 --guidance_scale=1 --report_to=wandb \
--gradient_accumulation_steps=1 --gradient_checkpointing \
--lr_scheduler=constant --lr_warmup_steps=0 --rank=4 \
--max_train_steps=700 --checkpointing_steps=600 --seed=0 \
--do_fp8_training --push_to_hub训练运行的峰值内存使用量为 36.57GB,大约在 20 分钟内完成。
此 FP8 微调模型的定性结果也可获得:

使用 torchao 启用 FP8 训练的关键步骤包括:
- 注入 FP8 层到模型中,使用
torchao.float8的convert_to_float8_training。 - **定义
module_filter_fn**来指定哪些模块应该和不应该转换为 FP8。
有关更详细的指南和代码片段,请参考此 gist 和 diffusers-torchao 仓库。
使用训练好的 LoRA 适配器进行推理
训练好LoRA 适配器后,您有两种主要的推理方法。
选项 1:加载 LoRA 适配器
一种方法是在基础模型之上加载您训练好的 LoRA 适配器。
加载 LoRA 的好处:
- 灵活性: 轻松在不同的 LoRA 适配器之间切换,无需重新加载基础模型
- 实验性: 通过交换适配器测试多种艺术风格或概念
- 模块化: 使用
set_adapters()组合多个 LoRA 适配器进行创意混合 - 存储效率: 保持一个基础模型和多个小适配器文件
代码
from diffusers import FluxPipeline, FluxTransformer2DModel, BitsAndBytesConfig
import torch
ckpt_id = "black-forest-labs/FLUX.1-dev"
pipeline = FluxPipeline.from_pretrained(
ckpt_id, torch_dtype=torch.float16
)
pipeline.load_lora_weights("derekl35/alphonse_mucha_qlora_flux", weight_name="pytorch_lora_weights.safetensors")
pipeline.enable_model_cpu_offload()
image = pipeline(
"a puppy in a pond, alphonse mucha style", num_inference_steps=28, guidance_scale=3.5, height=768, width=512, generator=torch.manual_seed(0)
).images[0]
image.save("alphonse_mucha.png")选项 2:将 LoRA 合并到基础模型
当您希望以单一风格获得最大效率时,可以将 LoRA 权重合并到基础模型中。
合并 LoRA 的好处:
- 显存效率: 推理期间没有适配器权重的额外内存开销
- 速度: 推理稍快,因为无需应用适配器计算
- 量化兼容性: 可以重新量化合并后的模型以获得最大内存效率
代码
from diffusers import FluxPipeline, AutoPipelineForText2Image, FluxTransformer2DModel, BitsAndBytesConfig
import torch
ckpt_id = "black-forest-labs/FLUX.1-dev"
pipeline = FluxPipeline.from_pretrained(
ckpt_id, text_encoder=None, text_encoder_2=None, torch_dtype=torch.float16
)
pipeline.load_lora_weights("derekl35/alphonse_mucha_qlora_flux", weight_name="pytorch_lora_weights.safetensors")
pipeline.fuse_lora()
pipeline.unload_lora_weights()
pipeline.transformer.save_pretrained("fused_transformer")
bnb_4bit_compute_dtype = torch.bfloat16
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=bnb_4bit_compute_dtype,
)
transformer = FluxTransformer2DModel.from_pretrained(
"fused_transformer",
quantization_config=nf4_config,
torch_dtype=bnb_4bit_compute_dtype,
)
pipeline = AutoPipelineForText2Image.from_pretrained(
ckpt_id, transformer=transformer, torch_dtype=bnb_4bit_compute_dtype
)
pipeline.enable_model_cpu_offload()
image = pipeline(
"a puppy in a pond, alphonse mucha style", num_inference_steps=28, guidance_scale=3.5, height=768, width=512, generator=torch.manual_seed(0)
).images[0]
image.save("alphonse_mucha_merged.png")在 Google Colab 上运行
虽然我们在 RTX 4090 上展示了结果,但相同的代码可以在更易于访问的硬件上运行,如Google Colab免费提供的 T4 GPU。
在 T4 上,您可以预期微调过程需要更长时间,相同步数大约需要 4 小时。这是为了可访问性的权衡,但它使得定制微调在没有高端硬件的情况下成为可能。如果在 Colab 上运行,请注意使用限制,因为 4 小时的训练运行可能会推到极限。
结论
QLoRA 结合 diffusers 库,显著民主化了定制 FLUX.1-dev 等最先进模型的能力。正如在 RTX 4090 上演示的那样,高效微调完全在可及范围内,产生高质量的风格适应。此外,对于拥有最新 NVIDIA 硬件的用户,torchao 通过 FP8 精度实现了更快的训练。
在 Hub 上分享您的创作!
分享您微调的 LoRA 适配器是为开源社区做贡献的绝佳方式。它允许其他人轻松尝试您的风格,基于您的工作构建,并有助于创建一个充满活力的创意 AI 工具生态系统。
如果您已经为 FLUX.1-dev 训练了 LoRA,我们鼓励您分享它。最简单的方法是在训练脚本中添加 --push_to_hub 标志。或者,如果您已经训练了模型并想要上传,可以使用以下代码片段。
# 前提条件:
# - pip install huggingface_hub diffusers
# - 运行一次 `huggingface-cli login`(或设置 HF_TOKEN 环境变量)
# - 保存模型
from huggingface_hub import create_repo, upload_folder
repo_id = "your-username/alphonse_mucha_qlora_flux"
create_repo(repo_id, exist_ok=True)
upload_folder(
repo_id=repo_id,
folder_path="alphonse_mucha_qlora_flux",
commit_message="Add Alphonse Mucha LoRA adapter"
)查看我们的 Mucha QLoRA https://huggingface.co/derekl35/alphonse_mucha_qlora_flux FP8 LoRA https://huggingface.co/derekl35/alphonse_mucha_fp8_lora_flux。您可以在此集合中找到这两个以及其他适配器作为示例。
我们迫不及待地想看到您创造的作品!