FaceChain更新人脸转换引领个性生成|GenArtist多模态艺术生成系统|AutoKaggle竞赛助手革新【AI周报】
FaceChain更新人脸转换引领个性生成|GenArtist多模态艺术生成系统|AutoKaggle竞赛助手革新【AI周报】
, Hack Forums scrapped-flux1-dev-fp8-compact-99638172.jpeg)
摘要
本周AI周报聚焦前沿生成技术:FaceChain人脸替换赋能个性化创作,GenArtist多模态图像生成探索艺术新境界,FastDrag实现精准高效的图像拖拽。AutoKaggle多代理系统革新竞赛流程,其余最新进展详见正文。
目录
- FaceChain: 高效身份保持的人脸生成工具
- GenArtist: 多模态生成与编辑的统一系统
- FastDrag: 实现高效图像拖拽编辑
- AutoKaggle: 自动化的多代理数据科学竞赛助手
- Moonshine: 低功耗高效语音识别模型
- ROCKET-1: 多智能体强化学习驱动的协作系统
FaceChain: 高效身份保持的人像生成工具
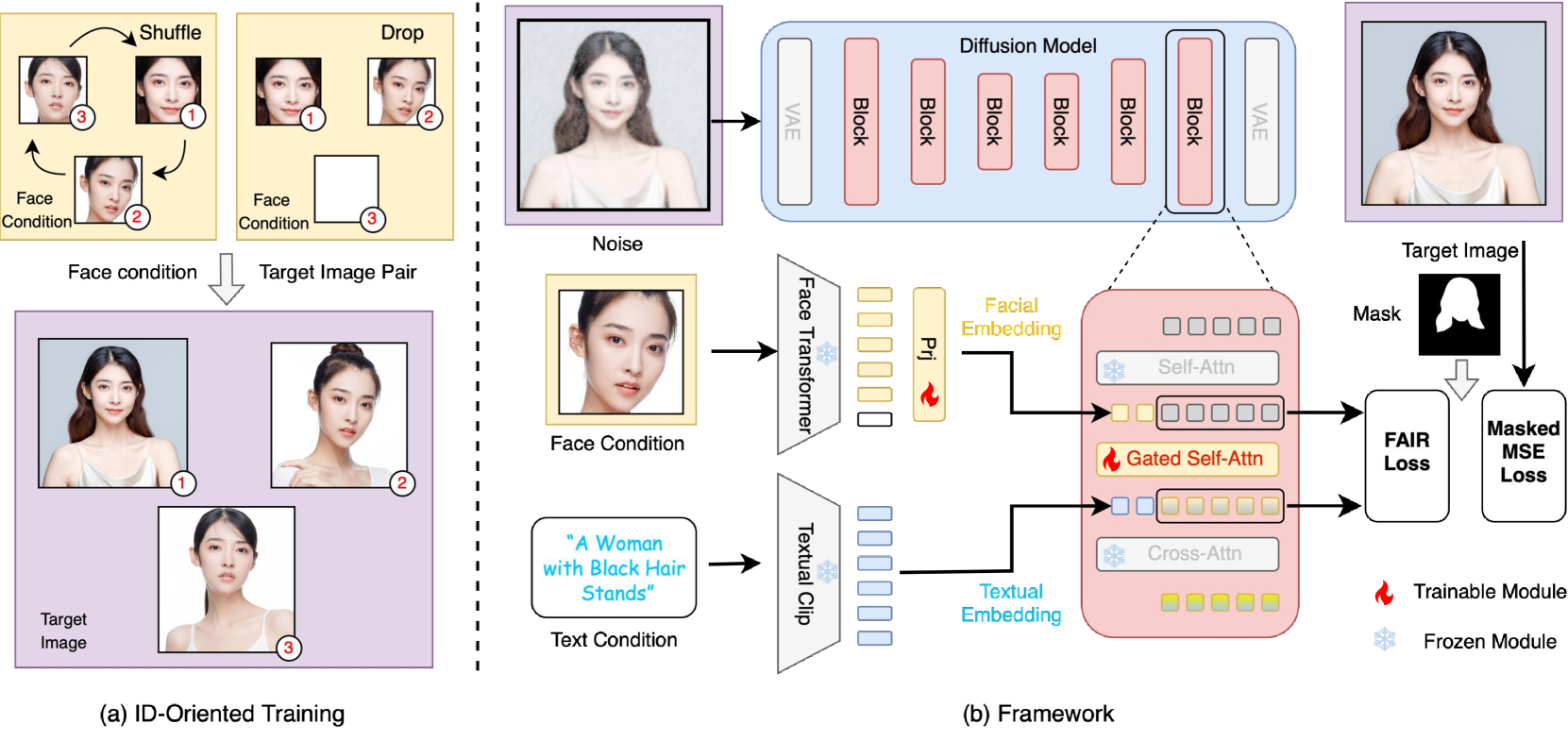
FaceChain Overview 图
概要: FaceChain 是由 ModelScope 推出的开源项目,专为生成保持身份特征的个性化人像设计。通过深度学习模型,FaceChain 允许用户在提供单张照片的基础上生成不同风格和背景的数字化身。其支持虚拟试衣和姿势控制等多项功能,能够在高效的 LoRA(Low-Rank Adaptation)模型训练下实现复杂的图像编辑任务,满足影视特效、虚拟角色创建和社交媒体内容个性化等应用需求。用户可在 ModelScope Notebook、Docker 或 Stable Diffusion WebUI 环境中部署 FaceChain,从而快速上手并自定义生成过程。
标签: #ModelScope #FaceChain #虚拟试衣 #图像生成 #LoRA
GenArtist: 多模态生成与编辑的统一系统
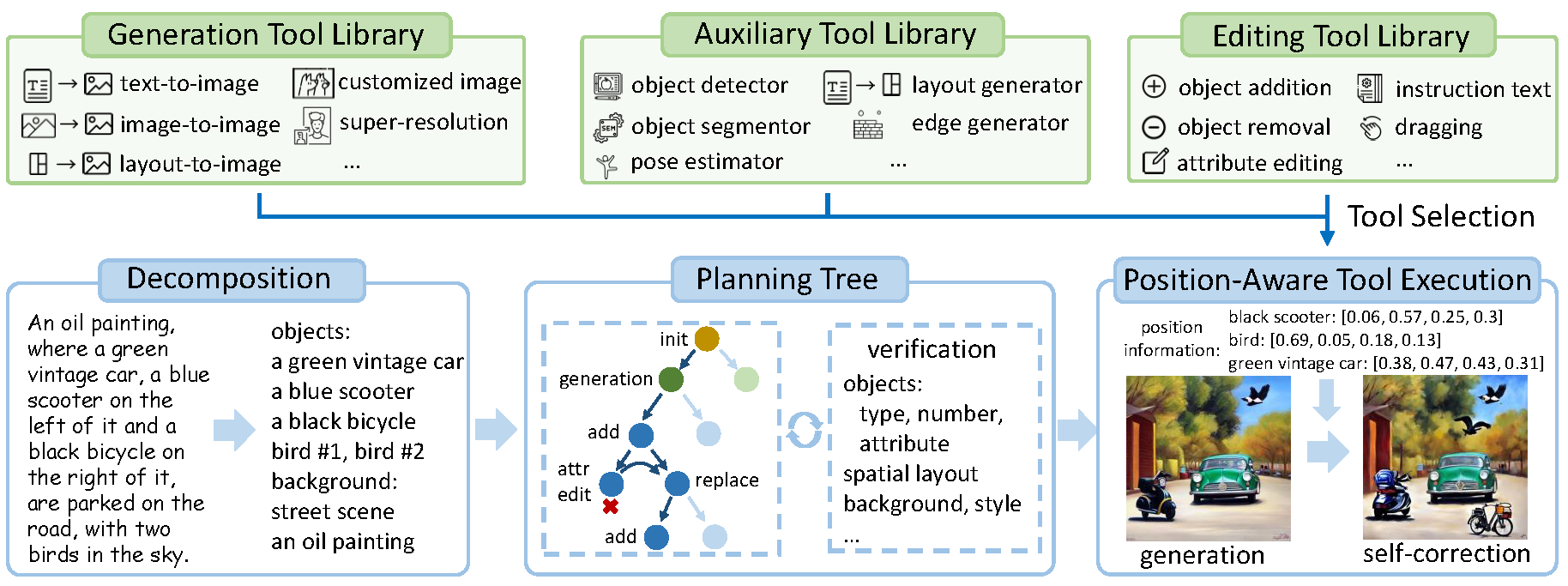
GenArtist Framework 图
概要 : GenArtist 是由 华为诺亚方舟实验室 和 清华大学 及 香港大学 提出的一个利用多模态大语言模型(Multimodal LLM,MLLM)协调的图像生成和编辑系统,允许用户在同一平台下实现文本生成图像、图像编辑、验证和自我修正功能。通过集成 Stable Diffusion、Inpaint-Anything 等多个生成工具,GenArtist 能够自动选择和执行适当的工具进行生成任务。其特有的 MLLM 代理帮助用户根据不同输入场景匹配最佳的生成和编辑流程,实现灵活的图像生成和自定义编辑效果。该项目展示了 LLM 在多模态任务中的高效协调能力,非常适用于图像创作、广告和数字艺术设计等领域。
标签: #生成艺术 #多模态LLM #LLM #图像生成 #自适应编辑
FastDrag: 一步实现图像内容操控
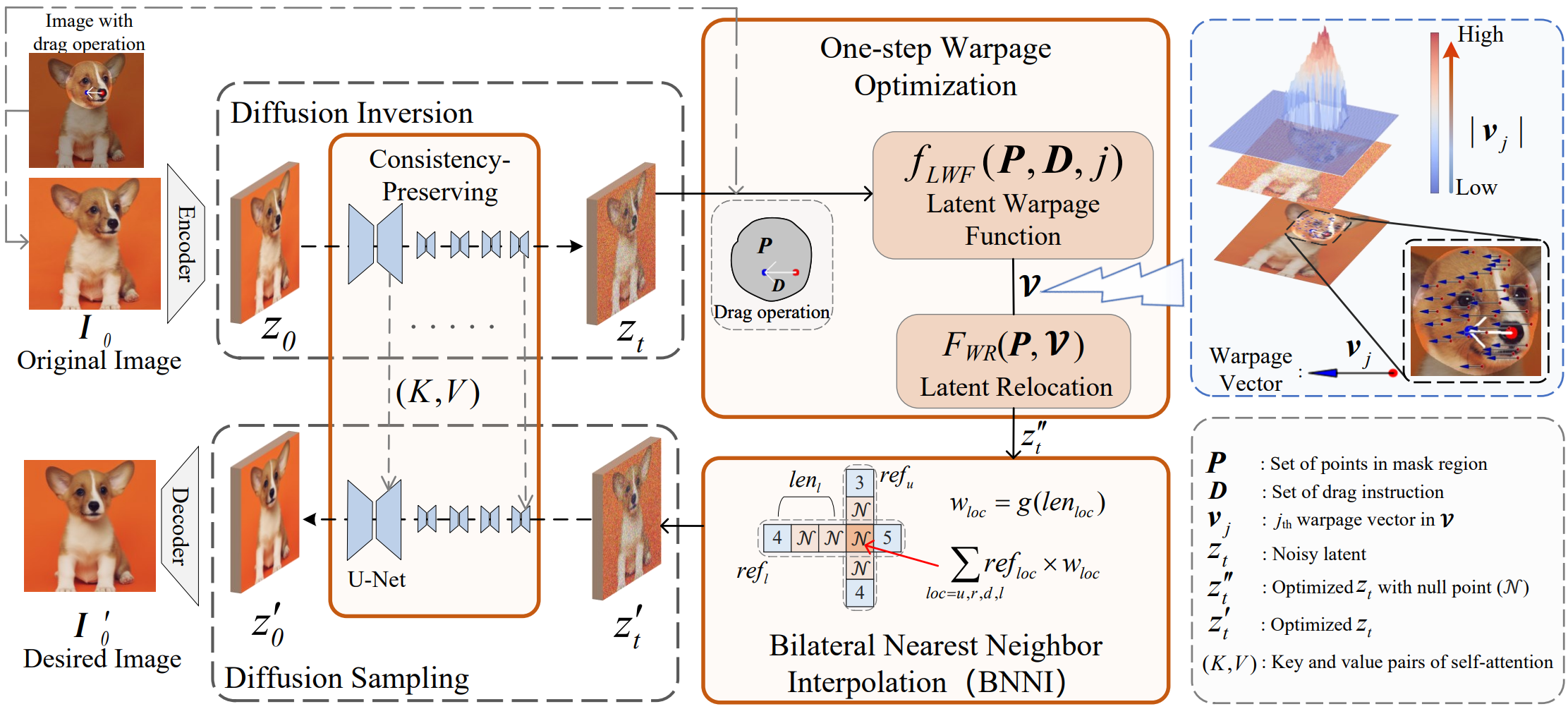
FastDrag Overview 图
概要: FastDrag 是 哈工大 和 南京大学 推出的一种革新性的图像编辑工具,旨在简化拖动编辑的效率和精度。传统方法通过多步迭代进行语义优化,而 FastDrag 则采用独特的“单步形变优化”策略(Latent Warpage Function, LWF),模拟拖拽指令对图像特定区域的变形效果。该方法通过双边最近邻插值(BNNI)方法对编辑区域进行智能填充,以确保在拖动操作后图像的语义完整性。此外,FastDrag 通过一致性保持策略来确保编辑结果与原始图像的一致性,其速度较现有方法快约 700%,在复杂的图像背景上也能保持较高的编辑效果。实验结果表明,FastDrag 在处理如多点拖拽或复杂纹理移动等场景时表现出色。
标签: #图像编辑 #单步优化 #语义填充 #一致性保持
AutoKaggle: 自动化多代理数据科学竞赛助手
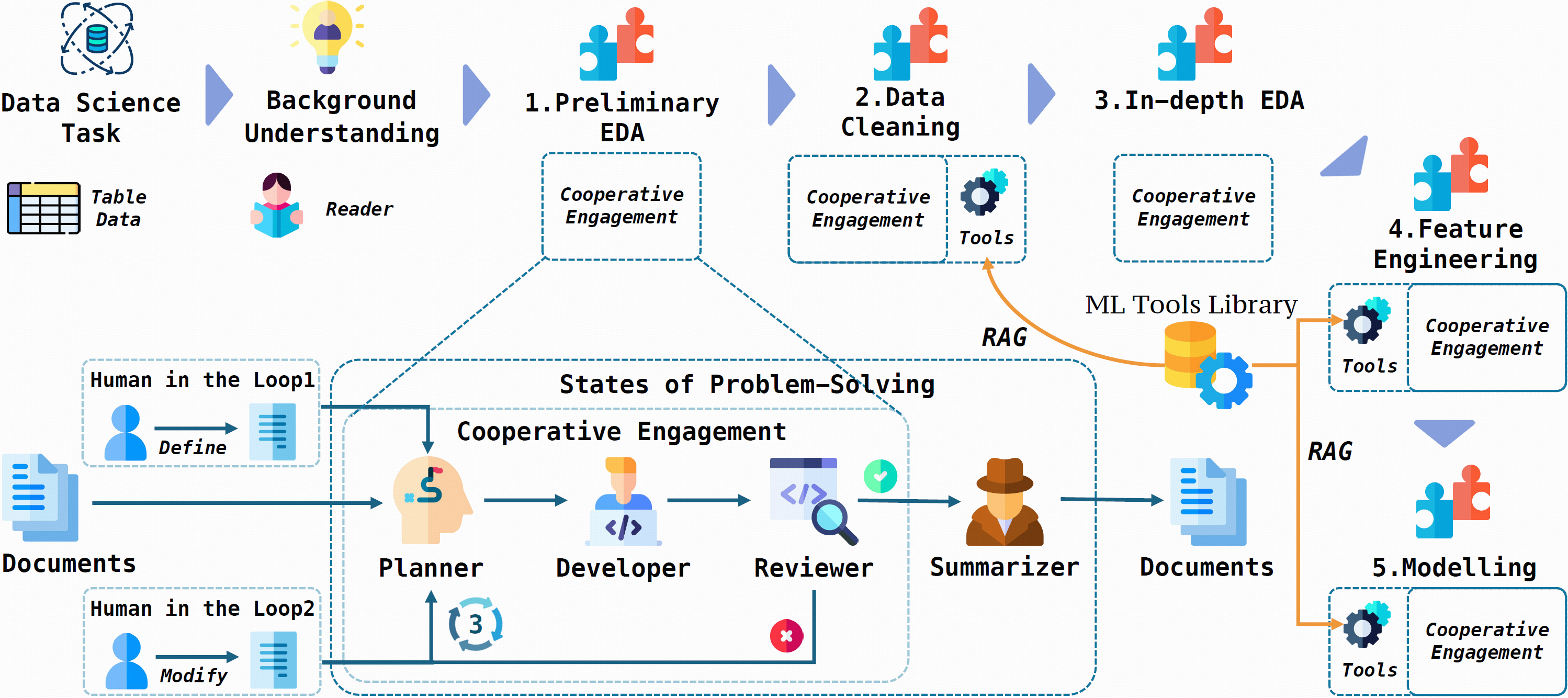
AutoKaggle Overview 图
概要: AutoKaggle 是 字节跳动 团队 提出的一个基于多代理系统的自动化数据科学竞赛助手,专为参与 Kaggle 竞赛的用户设计。此系统通过五种特定功能的智能体(包括 Reader、Planner、Developer、Reviewer 和 Summarizer)协同工作,完成数据处理、模型开发和优化的完整流程。AutoKaggle 的多代理架构使其能够独立处理从数据清洗、特征工程到模型选择和结果评估的各个步骤,提供了全流程的自动化支持。AutoKaggle 在多个 Kaggle 竞赛数据集上进行测试,展示了其高效的任务处理能力和自动化数据科学管道的潜力。
标签: #多智能体系统 #AutoML #数据科学 #Kaggle竞赛
Moonshine: 轻量级高效语音识别模型
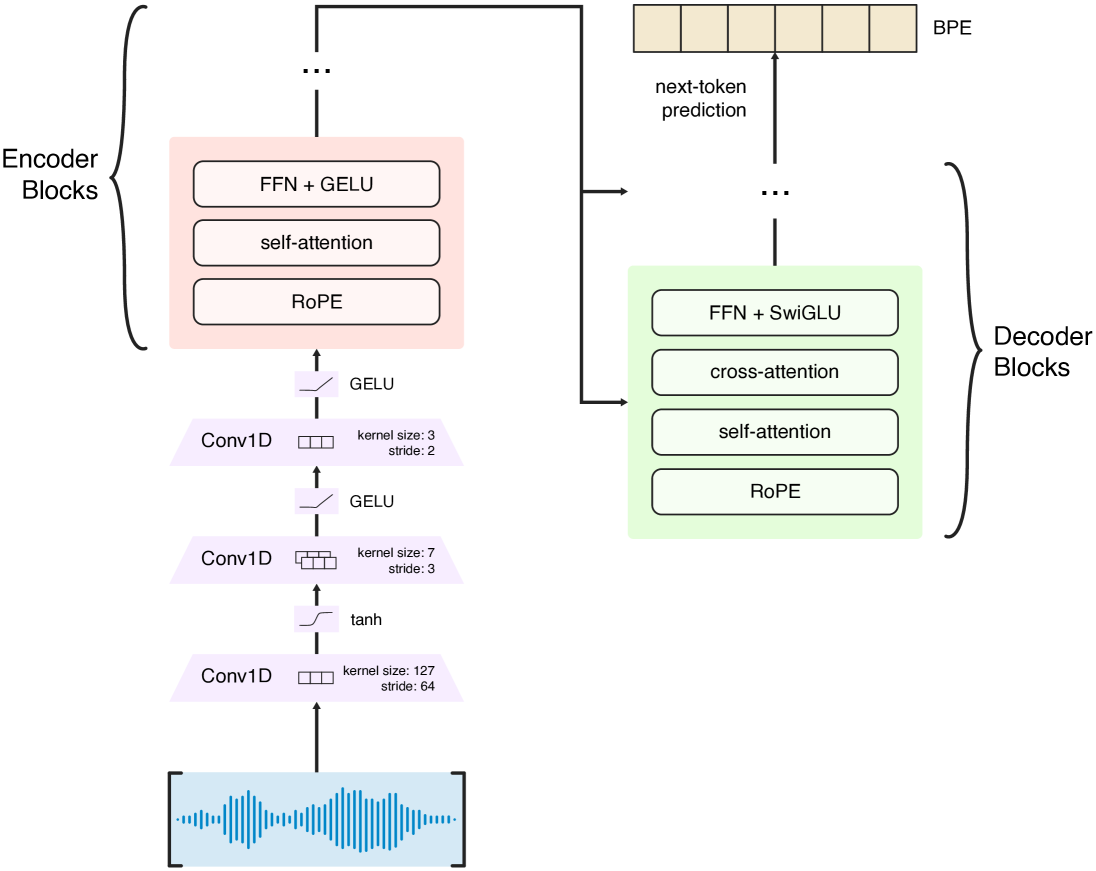
Moonshine Architecture 图
概要: Moonshine 是由 **Useful Sensors **开发的语音识别模型,专为在低功耗、内存受限的硬件设备上实现实时语音转录而设计。该模型具有两种不同规模的版本(Tiny 和 Base),可在保持高精度的同时,提供出色的推理速度。Moonshine 支持将英语语音自动转换为文本输出,非常适合用于边缘计算和物联网(IoT)场景。其创新的架构使得在计算资源有限的设备上也能高效运行,降低了实时语音转录的成本,并具备集成性和易部署性。Moonshine 在提升信息无障碍和隐私保护方面有广泛的应用潜力。
标签: #语音识别 #边缘计算 #低功耗 #IoT
ROCKET-1: 基于视觉-时间上下文的多智能体交互系统

ROCKET-1 Teaser 图
概要: ROCKET-1 是由 来自 北大、UCLA 和 BIGAI 的研究人员组成的 CraftJarvis 团队开发的强化学习多智能体系统,专为在 Minecraft 开放世界中的复杂任务设计。该模型采用视觉-时间上下文提示 (Visual-Temporal Context Prompting),使智能体能够实时处理游戏环境中的动态变化并执行复杂操作。ROCKET-1 系统包含多个预训练模块,支持不同的交互任务(如采矿、狩猎、物体互动),并能与视觉模型协同完成任务。该项目展示了在高自由度环境下多智能体如何通过智能提示高效学习和决策,适用于游戏 AI、自动驾驶模拟等领域。
标签: #多智能体 #强化学习 #视觉语言模型 #游戏AI #Minecraft