
Qwen3: 下一代具备混合思维和多语言精通能力的AI模型 | 2025年概览
Qwen3代表了人工智能领域的重大进步,提供了改进的推理能力、多语言支持以及各种基准测试的增强性能。作为Qwen大语言模型家族的最新成员,这一版本引入了创新功能和架构改进,使其成为主要AI实验室领先模型的有力竞争者。以下全面分析探讨了Qwen3的能力、技术规格和实际应用。
Qwen3简介
Qwen3于2025年4月由阿里巴巴集团发布,标志着Qwen大语言模型家族的最新一代。旗舰模型Qwen3-235B-A22B在各种基准测试中,包括编码、数学和通用能力方面,与行业领导者如DeepSeek-R1、o1、o3-mini、Grok-3和Gemini-2.5-Pro相比表现出竞争力。较小的MoE(专家混合)模型Qwen3-30B-A3B尽管只使用了十分之一的激活参数,却优于QwQ-32B的性能,而即使是紧凑型的Qwen3-4B模型也能媲美明显更大的Qwen2.5-72B-Instruct模型的能力。
此次发布包括MoE和密集模型,所有模型均在开源许可下提供。两个MoE模型——Qwen3-235B-A22B和Qwen3-30B-A3B——与六个密集模型相辅相成:Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B和Qwen3-0.6B,所有模型均在Apache 2.0许可下发布。
Qwen3模型家族
MoE模型
- Qwen3-235B-A22B:旗舰模型,总计2350亿参数,激活参数220亿。它由94层、64个查询注意力头、4个键值注意力头组成,拥有128个专家,其中8个被激活。该模型支持32,768个令牌的原生上下文长度,通过YaRN技术可扩展至131,072个令牌。
- Qwen3-30B-A3B:较小的MoE模型,总计305亿参数,激活参数33亿。它有48层、32个查询注意力头、4个键值注意力头,同样拥有128个专家,其中8个被激活。与其更大的对应模型一样,它支持广泛的上下文长度。
密集模型
Qwen3还提供六种不同大小的密集模型:
| 模型 | 层数 | 注意力头 (Q / KV) | 上下文长度 |
|---|---|---|---|
| Qwen3-0.6B | 28 | 16 / 8 | 32K |
| Qwen3-1.7B | 28 | 16 / 8 | 32K |
| Qwen3-4B | 36 | 32 / 8 | 32K |
| Qwen3-8B | 36 | 32 / 8 | 128K |
| Qwen3-14B | 40 | 40 / 8 | 128K |
| Qwen3-32B | 64 | 64 / 8 | 128K |
这些模型设计用于适应不同的计算需求和使用场景,从资源受限环境到高性能应用。
关键创新与特性
混合思维模式
Qwen3最显著的特性之一是在单一模型架构内支持双重思维模式:
- 思考模式:专为需要逻辑推理、数学计算或编码挑战的复杂任务设计。在这种模式下,模型会在提供答案前进行逐步推理,类似于人类处理复杂问题的方式。
- 非思考模式:优化用于对更直接的查询提供快速响应,为一般对话保持效率。
这种创新方法允许用户根据任务复杂性控制模型的推理深度。对于具有挑战性的问题,思考模式能够实现扩展推理,而更简单的问题可以直接回答,避免不必要的计算开销。实现包括一种软切换机制,使用户能够通过在提示或系统消息中添加/think和/no_think标签来动态控制行为。
广泛的多语言能力
Qwen3支持令人印象深刻的119种语言和方言,是其前身Qwen2.5覆盖范围的三倍。这一广泛的语言范围跨越多个语系:
- 印欧语系(英语、法语、西班牙语、俄语、印地语等)
- 汉藏语系(各种汉语变体、缅甸语)
- 亚非语系(各种阿拉伯语变体、希伯来语)
- 南岛语系(印尼语、马来语、他加禄语)
- 达罗毗荼语系(泰米尔语、泰卢固语、卡纳达语)
- 突厥语系(土耳其语、乌兹别克语)
- 台-卡岱语系、乌拉尔语系、南亚语系等
这种全面的多语言支持使Qwen3能够在全球范围内被采用,特别是在语言多样性的地区。
高级代理能力
Qwen3已针对编码和代理操作进行了优化,增强了对模型条件提示(MCP)的支持。这些改进使更复杂的应用成为可能,如自主代理和精确的开发工具。这些模型在思考和非思考模式下都擅长工具集成,在复杂的基于代理的任务中达到开源模型中的领先性能。
技术架构与训练
预训练过程
Qwen3的预训练数据集比其前身的数据集大得多,包含约36万亿个涵盖119种语言和方言的令牌——几乎是Qwen2.5使用的18万亿个令牌的两倍。数据收集过程非常严格:
- 网络来源的内容由从PDF类文档中提取的文本补充
- 使用Qwen2.5-VL从文档中提取文本
- 使用Qwen2.5提高提取内容的质量
- Qwen2.5-Math和Qwen2.5-Coder生成合成数据来增强数学和代码内容
预训练遵循三阶段过程:
- 第一阶段(S1):在超过30万亿个令牌上训练,上下文长度为4K令牌,建立基础语言技能和一般知识
- 第二阶段(S2):在额外的5万亿个令牌上训练,增加知识密集型数据(STEM、编码、推理)的比例
- 第三阶段(S3):使用高质量的长上下文数据将上下文长度扩展到32K令牌
这种广泛的训练机制使Qwen3密集基础模型能够匹配或超越更大的Qwen2.5模型的性能。例如,Qwen3-1.7B/4B/8B/14B/32B-Base的性能分别与Qwen2.5-3B/7B/14B/32B/72B-Base相当,同时在STEM、编码和推理等专业领域表现出色。
后训练方法论
为了开发能够同时进行详细推理和快速响应的混合模型,实施了四阶段训练流程:
- 长思维链(CoT)冷启动:在涵盖数学、编码、逻辑推理和STEM问题的多样化CoT数据上进行微调
- 基于推理的强化学习(RL):为RL扩展计算资源,使用基于规则的奖励来增强探索和利用
- 思维模式融合:通过对组合数据进行微调,将非思考能力整合到思考模型中
- 通用RL:在20多个通用领域任务中应用强化学习,以加强能力并纠正不良行为
性能和基准测试结果
根据基准评估,Qwen3模型在各种指标上表现出色:

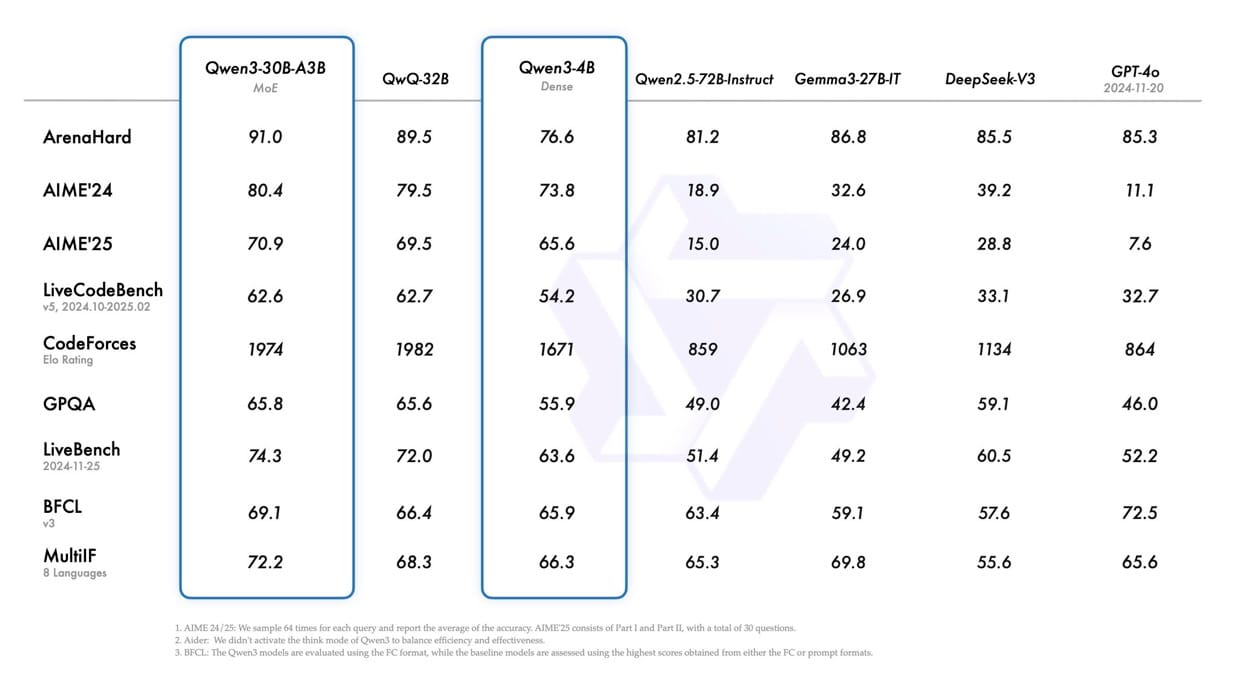
这些基准表明,Qwen3模型在几个关键领域与行业领先的替代方案相比具有竞争力或超越它们。旗舰Qwen3-235B-A22B模型在具有挑战性的推理任务中一直名列前茅。
将旧版Qwen模型与竞争对手相比,基准性能有明显改进。Qwen3-30B-A3B显著优于Qwen-30B-A3B(图像中显示为Qwen3-30B-A3B),甚至较小的Qwen3模型与其前身相比也表现出增强的能力。
开发与实际应用
使用Qwen3模型
Qwen3模型可通过多个平台访问,包括Hugging Face、ModelScope和Kaggle。对于部署,推荐使用SGLang和vLLM框架,而本地使用则通过Ollama、LMStudio、MLX、llama.cpp和KTransformers等工具支持。
使用Hugging Face transformers的Qwen3-30B-A3B基本示例:
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B"
# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# 准备模型输入
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # 在思考和非思考模式之间切换
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 生成文本
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# 解析思考内容
try:
# 查找</think>令牌 (151668)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("思考内容:", thinking_content)
print("回复内容:", content)使用SGLang(版本0.4.6.post1或更高版本)部署以创建兼容OpenAI的API端点:
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B --reasoning-parser qwen3使用vLLM(版本0.8.4或更高版本)部署:
vllm serve Qwen/Qwen3-30B-A3B --enable-reasoning --reasoning-parser deepseek_r1使用Ollama进行本地开发:
ollama run qwen3:30b-a3b代理能力
Qwen3在工具调用能力方面表现出色,并且兼容Qwen-Agent,后者封装了工具调用模板和解析器以简化实现。代理实现示例:
from qwen_agent.agents import Assistant
# 定义LLM
llm_cfg = {
'model': 'Qwen3-30B-A3B',
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
}
# 定义工具
tools = [
{'mcpServers': { # MCP配置
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}},
'code_interpreter', # 内置工具
]
# 创建代理
bot = Assistant(llm=llm_cfg, function_list=tools)
# 生成响应
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ 介绍Qwen的最新发展'}]
for responses in bot.run(messages=messages):
pass
print(responses)这种实现的灵活性使其能够在各个领域实现多样化的应用,从对话代理到特定专业领域的专用工具。
未来发展方向
Qwen3代表了迈向人工通用智能(AGI)和人工超智能(ASI)旅程中的重要里程碑。展望未来,开发团队旨在多个维度上增强模型:
- 优化模型架构和训练方法
- 扩展数据规模和增加模型大小
- 扩展上下文长度能力
- 扩展模态支持
- 通过环境反馈推进强化学习以实现长时间推理
团队设想从以训练模型为中心的时代过渡到以训练代理为中心的时代。未来的迭代预计将在专业和个人应用中带来有意义的进步。
结论
Qwen3代表了大语言模型技术的重大进步,在与行业领导者的竞争中表现出色,同时提供了混合思维模式和广泛的多语言支持等独特功能。开源权重的方式使从紧凑的0.6B参数版本到强大的235B-A22B旗舰模型的高级AI在各种计算环境和使用场景中都能得到应用。
模型的架构创新,特别是其专家混合设计和在思考和非思考模式之间动态切换的能力,为多样化的应用提供了效率和灵活性。随着AI继续向更复杂的推理和代理发展,Qwen3作为该领域的重要贡献,平衡了性能、可访问性和实际效用。
凭借在关键基准测试中的强劲表现和全面的开发生态系统,Qwen3为研究人员、开发人员和组织提供了强大的工具来构建创新的AI解决方案。持续致力于在多个维度上增强能力,表明未来的迭代将继续推动人工智能领域的可能性边界。