MaterialAnything生成PBR材质|ConsisID优化ID视频生成|FlipSketch实现草图动画【AI周报】
MaterialAnything生成PBR材质|ConsisID优化ID视频生成|FlipSketch实现草图动画【AI周报】

摘要
本周聚焦生成式AI创新:MaterialAnything自动生成PBR材质;OminiControl为Diffusion模型提供通用轻量控制框架;FlipSketch生成草图动画。这些进步展示了生成式AI的迭代效率之高,其余内容详见正文。
目录
- ShowUI: A Large Multimodal Dataset for AI-Powered UI Generation
- ROICtrl: Region-Based Image Editing Control with Diffusion Models
- ConsisID: Consistency in Instance Discrimination
- SketchAgent: Zero-Shot and Few-Shot Sketch Understanding
- AnchorCrafter: Novel Methods for Generating Dense Image Anchors
- TEXGen: Generative Textures for 3D Applications
- MaterialAnything: Material Diffusion Models for 3D Design
- DiptychPrompting: A Novel Prompting Paradigm for Image Editing
- OminiControl: Unified Framework for Interactive Control of AI Models
- FlipSketch: AI-Powered Sketch Morphing and Editing
ShowUI:多模态用户界面生成数据集
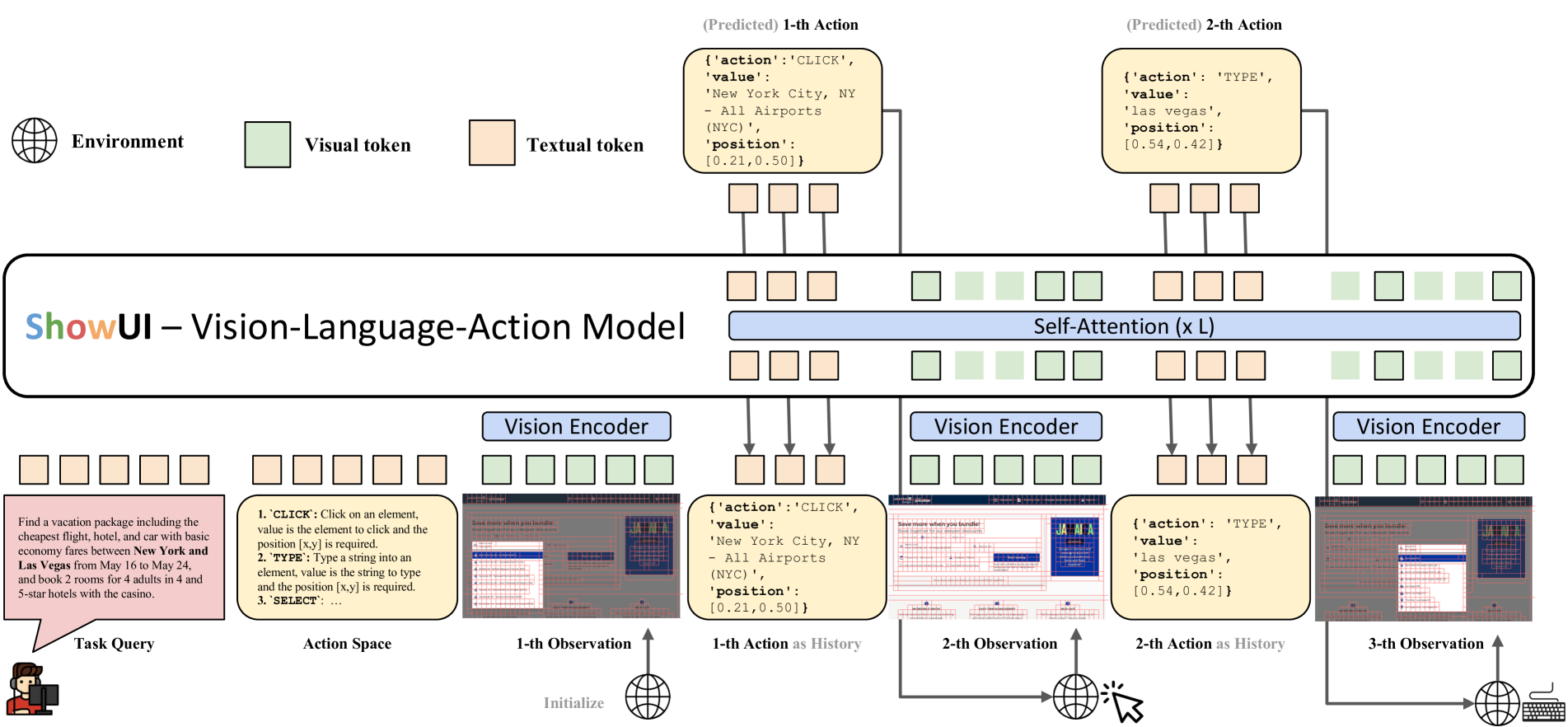
概要:来自 新国立 的 ShowLab 介绍了一种名为 ShowUI 的视觉-语言-动作模型,旨在提高GUI代理在视觉感知和交互方面的性能。ShowUI通过UI引导的视觉标记选择、交错式视觉-语言-动作流以及数据管理策略,实现了高效且准确的GUI任务处理。具体来说,该模型通过将屏幕截图转换为UI连接图来降低计算成本,并自适应地识别冗余关系;同时,通过灵活的任务流管理和重采样策略,解决了数据不平衡问题。
标签:#GUI代理 #视觉-语言-动作 #标记选择 #数据管理 #零样本学习
ROICtrl:多实例可控视觉生成框架
概要:ROICtrl 是由新加坡国立大学 (NUS) 与 Meta 等联合开发的视觉生成工具,扩展了现有Diffusion模型(如 ControlNet、T2I-Adapter)的功能,支持对图像多个区域的精确控制。ROICtrl 利用区域对齐与反对齐 (ROI-Align 和 ROI-Unpool) 技术,实现高分辨率图像中每个实例的独立生成和操控,同时显著降低计算开销。
标签:#视觉生成 #区域控制 #Diffusion模型 #多实例生成
ConsisID:一致性身份保留的文本到视频生成框架
概要:ConsisID 是由北京大学 Yuan Group 开发的创新文本到视频生成框架,专注于在视频生成中保持人物身份一致性。该项目通过频率分解技术对 Diffusion Transformers (DiT) 模型进行了优化,能够在复杂场景下生成具有身份特征一致的多帧视频。这一框架无需额外的微调步骤,显著提升了生成质量和效率。
标签:#文本到视频 #一致性生成 #北京大学 #Diffusion模型
SketchAgent:语言驱动的交互式素描生成

概要:SketchAgent 是由 MIT, Stanford 推出的一种新型素描生成智能体,结合多模态大语言模型 (LLM),支持基于自然语言的连续素描生成和交互式绘画。用户可以通过文本描述生成复杂的素描,并使用交互界面进行协作式绘画或编辑。其设计支持多样化概念的生成,适合零样本或小样本的绘画任务。
标签:#素描生成 #多模态AI #人机交互 #LLM
AnchorCrafter:密集图像锚点生成的新方法
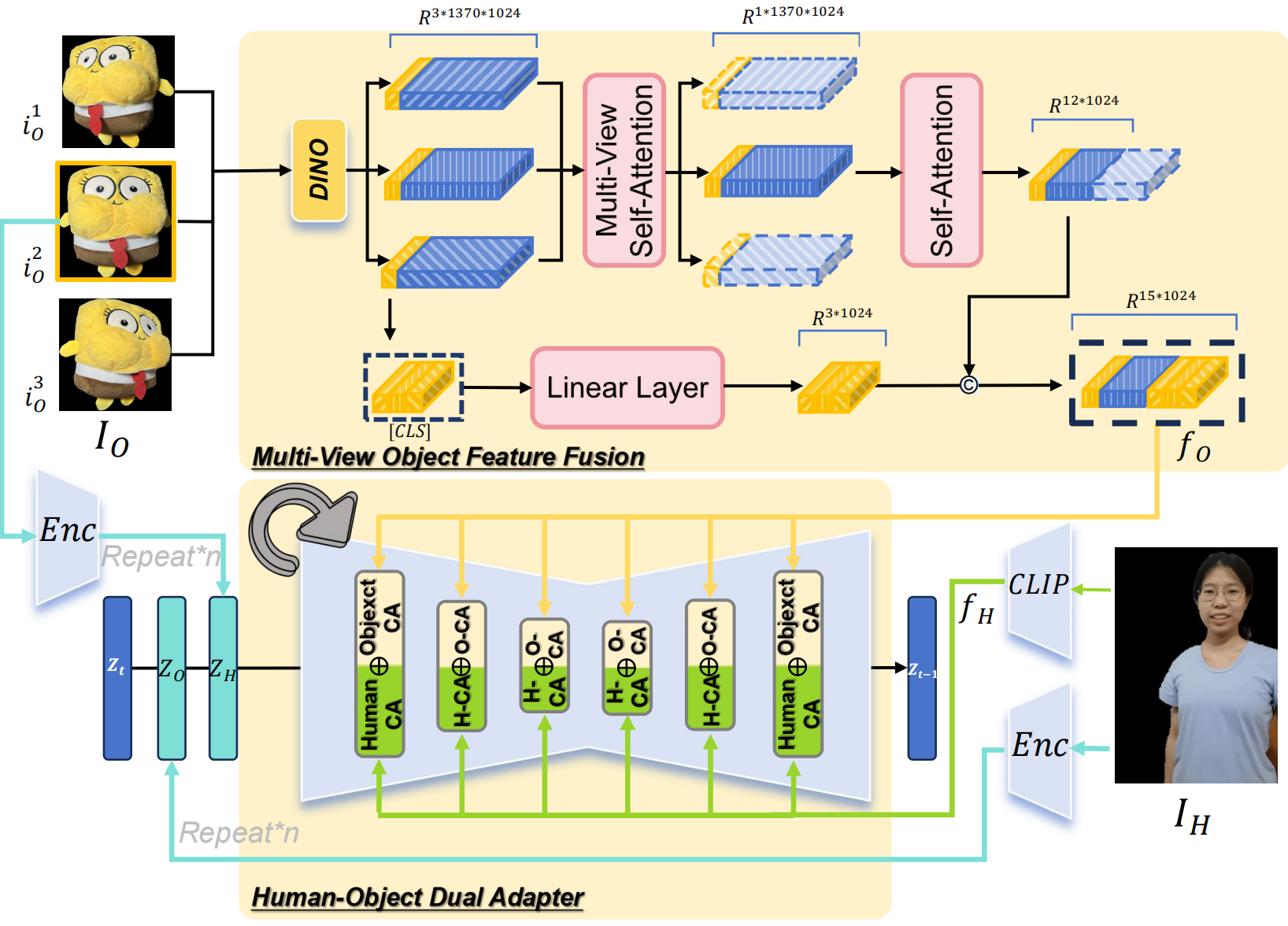
概要:AnchorCrafter 是一种基于Diffusion的系统,用于自动生成具有高视觉保真度和可控互动的2D产品推广视频。该系统通过整合人-物交互(HOI)来解决姿态引导的人类视频生成中的核心问题。具体来说,AnchorCrafter提出了两个关键创新:HOI外观感知,增强从任意多视角识别物体外观并解耦物体和人类外观;HOI运动注入,通过克服物体轨迹条件和互遮挡管理的挑战,实现复杂的人-物互动。此外,还引入了HOI区域重加权损失,以增强物体细节的学习。
标签:#Diffusion #图像表示 #HOI #数字人
TEXGen:基于Diffusion模型的网格纹理生成

概要:TEXGen 是一个生成式Diffusion模型,专注于通过Diffusion技术直接在UV域生成物体的纹理贴图,特别是Albedo纹理。该方法由 CVMI实验室(计算机视觉与机器智能实验室)开发,训练了一个大型的Diffusion模型,旨在提升纹理生成的效率与质量。TEXGen能够处理高分辨率和复杂纹理,同时支持不同类别的三维模型。项目的核心技术基于PyTorch Lightning构建,计划未来发布代码。
标签:#纹理生成 #Diffusion模型 #3D建模 #PyTorch Lightning #CVMI实验室
MaterialAnything:基于AI的自动PBR材质生成
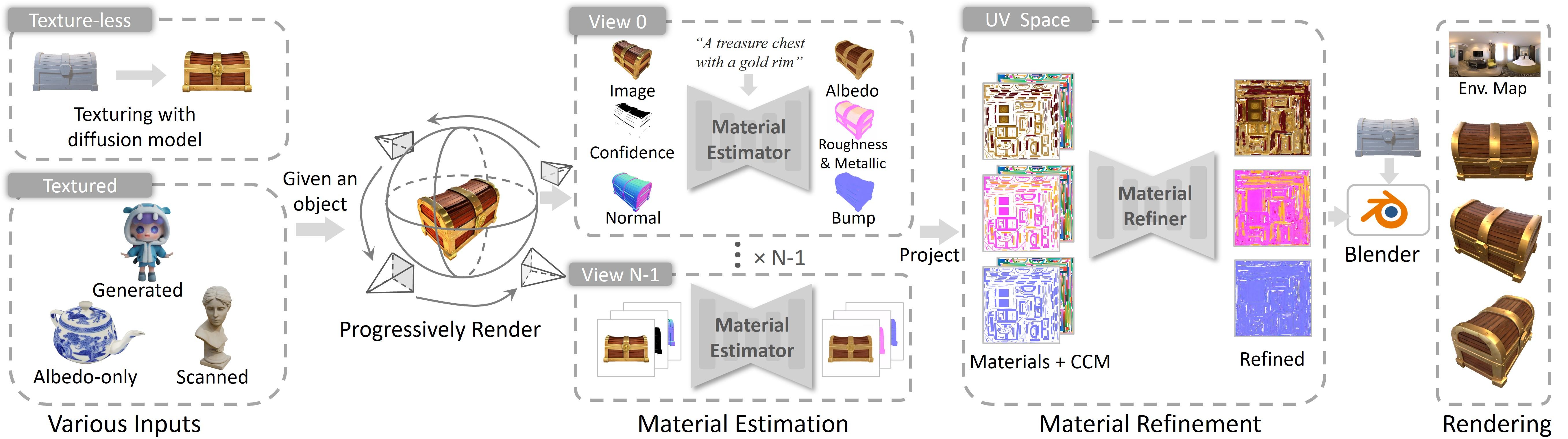
概要:MaterialAnything 是由 3DTopia 团队开发的一个开源全自动、统一的扩散框架,用于生成3D对象的基于物理的材质。与依赖复杂流程或特定优化的现有方法不同,Material Anything提供了一种稳健的端到端解决方案,适用于各种光照条件下的对象。该方法利用预训练的图像扩散模型,并通过三头架构和渲染损失来提高稳定性和材质质量。此外,引入了置信度掩码作为扩散模型中的动态切换器,使其能够有效处理不同光照条件下的纹理和无纹理对象。通过使用由这些置信度掩码引导的渐进式材质生成策略以及UV空间材质细化器,确保了一致且UV就绪的材质输出。
标签:#PBR材质 #3D建模 #3DMesh #开源
DiptychPrompting:零样本主题驱动的图像生成与编辑
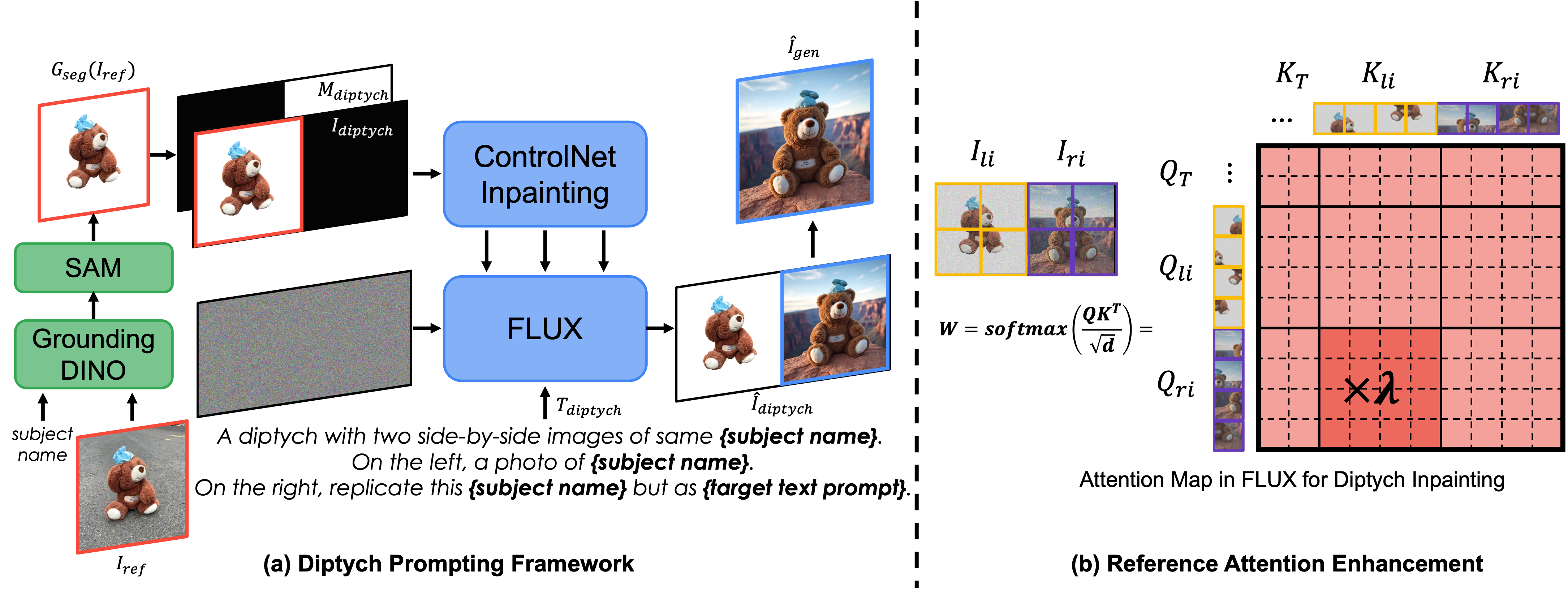
概要:DiptychPrompting 是 首尔国立大学 提出的一种创新的文本到图像生成方法,将主题驱动的生成任务重新定义为补全式绘画(inpainting)问题。该方法利用 Diptych(双联画)形式,将参考图像放在左侧,右侧为空白区域,通过文本条件生成新的图像内容。DiptychPrompting 强化了左侧图像与右侧生成的上下文对齐,能够实现高精度主题还原,同时支持风格化生成与主题编辑任务,在多样化场景下具备显著优势。
标签:#图像生成 #零样本学习 #主题编辑 #补全式绘画 #风格化生成
OminiControl:用于Diffusion模型的通用控制框架

概要:OminiControl 是一个由 新加坡国立大学 研发的轻量级通用控制框架,支持对Diffusion Transformer 模型(如 FLUX)的灵活控制。框架以最小化设计为特点,通过插入少量参数(仅 0.1% 额外参数)实现高效的主题驱动和空间控制能力。应用包括边缘引导生成、补全绘画、图像去模糊和颜色调整等任务,同时也支持主题驱动的生成场景。框架集成了易用的 Gradio 界面,适合快速实验和实际应用。
标签:#Diffusion模型 #通用控制 #主题驱动生成 #边缘引导生成 #新加坡国立大学
FlipSketch:将静态草图转换为文本引导的动画

概要:FlipSketch 是一个 萨利大学 开发的创新生成系统,旨在将静态手绘草图转化为文本引导的动画片段。该工具基于改进的文本到视频生成模型(T2V),结合了草图的输入特性,通过关注点组成(attention composition)方法优化生成过程。在实际应用中,FlipSketch 支持用户使用草图作为输入,配合自然语言描述生成具有动态效果的动画,例如草图内容的移动或逐帧动画展示。其目标是为艺术家和设计者提供便捷的草图动画创作平台。
标签:#草图动画 #文本到视频 #生成式AI #草图创作
参考链接:
- ShowUI
- ShowUI 论文
- ROICtrl
- ROICtrl GitHub
- ROICtrl 论文
- ConsisID
- ConsisID GitHub
- ConsisID 论文
- SketchAgent
- SketchAgent GitHub
- SketchAgent 论文
- AnchorCrafter
- AnchorCrafter GitHub
- AnchorCrafter 论文
- TEXGen
- TEXGen GitHub
- TEXGen 论文
- MaterialAnything GitHub
- MaterialAnything 论文
- DiptychPrompting
- DiptychPrompting 论文
- OminiControl GitHub
- OminiControl 论文
- FlipSketch GitHub
- FlipSketch 论文