Qwen图像编辑模型|DeepSeek-V3.1混合思维|字节豆包Seed-OSS开源【HF周报】
Qwen图像编辑模型|DeepSeek-V3.1混合思维|字节豆包Seed-OSS开源【HF周报】

摘要
本周亮点:Qwen推出专业图像编辑模型,支持语义与外观双重编辑;DeepSeek升级V3.1版本,首次实现思维与非思维模式混合;字节跳动开源Seed-OSS-36B,具备灵活思维预算控制。详细内容见下文,相关参考链接请见文末。
目录
- Qwen-Image-Edit:专业图像编辑生成模型
- DeepSeek-V3.1:混合思维模式语言模型
- Seed-OSS-36B-Instruct:灵活思维预算控制模型
- OmniNeural-4B:首款NPU感知多模态模型
- Matrix-Game-2.0:实时交互世界模型
- HDM-xut-340M-anime:轻量级动漫风格生成
- DINOv3-ViT-7B:大规模视觉基础模型
- NextStep-1-Large:连续标记自回归生成
Qwen-Image-Edit:专业图像编辑生成模型

概要:阿里云Qwen团队发布Qwen-Image-Edit图像编辑模型,基于20B参数的Qwen-Image模型构建,成功将其独特的文本渲染能力扩展到图像编辑任务。该模型同时支持语义编辑(如IP创作、对象旋转、风格转换)和外观编辑(如添加、删除或修改特定元素),并具备精确的中英文双语文本编辑能力,能够直接对图像中的文字进行添加、删除和修改,同时保持原有字体、大小和样式。
标签:#Qwen #图像编辑 #文本渲染 #多语言支持 #语义编辑
DeepSeek-V3.1:混合思维模式语言模型
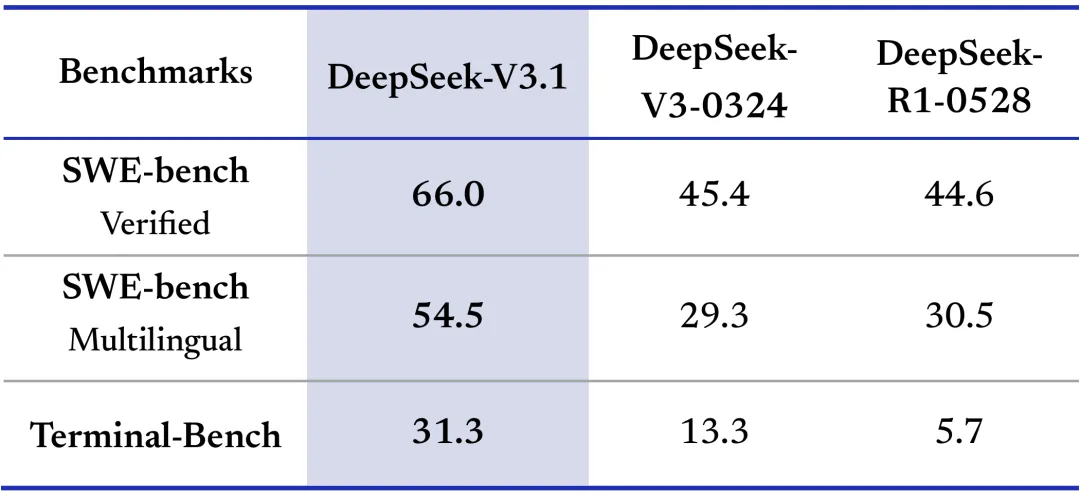
概要:DeepSeek发布V3.1版本,这是一个支持思维和非思维两种模式的混合模型,具备671B参数和128K上下文长度。该版本基于V3.1-Base构建,通过两阶段长上下文扩展方法,32K扩展阶段增加10倍至630B标记,128K扩展阶段扩展3.3倍至209B标记。与前版本相比带来多项改进:通过改变聊天模板实现一个模型同时支持两种模式,通过后训练优化显著提升工具调用和智能体任务性能,并在保持与DeepSeek-R1-0528相当答案质量的同时实现更快的思维效率。模型采用UE8M0 FP8规模数据格式训练,确保与微缩放数据格式的兼容性。
标签:#DeepSeek #混合思维模式 #工具调用优化 #671B参数 #长上下文扩展
Seed-OSS-36B-Instruct:灵活思维预算控制模型
概要:字节跳动Seed团队发布Seed-OSS开源模型系列,具备36B参数和512K原生长上下文支持。该模型的突出特性是灵活的思维预算控制,允许用户根据需要动态调整推理长度,从而在实际应用场景中提高推理效率。模型在推理、智能体和通用能力方面表现优异,支持工具使用和问题解决等智能体任务,同时提供对研究友好的多样化版本选择。
标签:#字节跳动 #Seed-OSS #思维预算控制 #36B参数 #智能体任务
OmniNeural-4B:首款NPU感知多模态模型

概要:Nexa AI发布全球首款专为神经处理单元(NPU)设计的多模态模型OmniNeural,原生理解文本、图像和音频,可在PC、移动设备、汽车、物联网和机器人等平台运行。该模型采用NPU友好的架构设计,使用ReLU操作、稀疏张量、卷积层和静态图执行,相比非NPU感知模型提速20%,音频处理速度提升9倍,图像处理速度提升3.5倍。
标签:#Nexa AI #NPU优化 #多模态智能 #硬件感知架构 #边缘计算
Matrix-Game-2.0:实时交互世界模型

概要:Skywork发布Matrix-Game-2.0交互式世界模型,具备1.8B参数,通过少步自回归扩散技术实现实时长视频生成。该模型支持25 FPS流式视频合成,可生成分钟级高保真视频,并具备精确的动作注入功能,通过鼠标/键盘到帧的模块实现帧级控制和动态响应。系统还包含针对虚幻引擎和GTA5的大规模交互数据管道,生成约1200小时的高质量交互视频数据。
标签:#Skywork #交互世界模型 #实时视频生成 #动作控制 #游戏AI
HDM-xut-340M-anime:轻量级动漫风格生成

概要:琥珀青叶(KBlueLeaf)发布HDM-xut-340M-anime,这是世界上最小、最便宜的动漫风格文本到图像基础模型。该项目探索了"在家预训练T2I模型"的专门训练配方,引入了为多模态生成模型设计的新型变换器骨干"XUT"(Cross-U-Transformer)。通过最小化架构设计和TREAD技术,该模型在最多花费650美元的计算资源下实现可用性能,支持1024x1024或更高分辨率生成。
标签:#KBlueLeaf #HDM #XUT架构 #动漫生成 #低成本训练
DINOv3-ViT-7B:大规模视觉基础模型

概要:Meta AI发布DINOv3视觉基础模型家族,其中ViT-7B模型具备67亿参数,在广泛的视觉任务中无需微调即可超越专门的最先进技术。该模型在LVD-1689M数据集(16.89亿图像)上训练,采用DINO自蒸馏损失、iBOT掩码图像建模损失、KoLeo正则化等先进训练技术,能够产生高质量的密集特征,在各种视觉任务上实现优异性能。
标签:#Meta AI #DINOv3 #视觉基础模型 #自监督学习 #67亿参数
NextStep-1-Large:连续标记自回归生成

概要:阶跃星辰(StepFun)发布NextStep-1-Large,这是一个14B参数的自回归模型,配备157M流匹配头,在离散文本标记和连续图像标记上进行下一个标记预测目标训练。该模型在文本到图像生成任务中为自回归模型实现了最先进的性能,在高保真图像合成方面展现出强大能力,代表了大规模连续标记自回归图像生成的重要进展。
标签:#StepFun #NextStep #自回归生成 #连续标记 #流匹配技术