Marvis-TTS 实时语音克隆 | Nano-Bananas 正式发布 | OmniHuman-1.5 认知仿真驱动长序列TalkingHead【AI日报】
Marvis-TTS 实时语音克隆 | Nano-Bananas 正式发布 | OmniHuman-1.5 认知仿真驱动长序列TalkingHead【AI日报】

摘要
本日亮点:Marvis-TTS 实现边缘端实时语音克隆;Gemini 图像编辑提升多轮一致性;InstantX 开源 Qwen-Image ControlNet,ComfyUI 首日集成;OmniHuman-1.5 基于认知仿真驱动长时序角色动画。
目录
- Marvis-TTS:面向边缘与实时流式的语音克隆
- Nano-Bananas:Gemini 2.5 Flash 图像编辑模型
- Qwen-Image-ControlNet:InstantX 开源的Union ControlNet
- ComfyUI-VibeVoice:在 ComfyUI 中的多说话人 TTS 节点
- WhisperLiveKit:实时转写与 diarization 工具包
- OmniHuman-1.5:认知仿真驱动的长时序角色动画
Marvis-TTS:面向边缘与实时流式的语音克隆
概要:Marvis-TTS(marvis-tts-250m)主打低延迟实时流式合成与 10 秒语音克隆,支持 MLX 与 Transformers 两套推理接口。模型量化后约 500MB,便于在移动与边缘设备本地部署并实现边说边合成;基于多模态 CSM(250M backbone + 60M audio decoder),可连贯处理整段文本以减少伪影。许可证 Apache‑2.0;使用时注意隐私与合规风险,Hugging Face 与 GitHub 提供快速上手示例。
标签:#MarvisTTS #语音合成 #语音克隆 #实时流式 #边缘部署
Nano-Banan:Gemini 2.5 Flash 图像编辑模型

概要:DeepMind 在 Gemini App 推出的 gemini-2.5-flash-image-preview(代号 Nano‑Banan)显著提升多轮图像编辑中的外观一致性与图像混合能力,适合换装、发型与场景替换等多步编辑。输出含显式水印并嵌入 SynthID(隐式指纹)以标注 AI 生成内容;已在 Gemini App 开放试用,使用时请注意肖像与版权合规。
标签:#Gemini #图像编辑 #多轮编辑 #SynthID #DeepMind
Qwen-Image-ControlNet:InstantX 开源的Union ControlNet

概要:InstantX 的 Qwen-Image-ControlNet-Union 是统一 ControlNet,支持 Canny、SoftEdge、Depth 与 Pose 四类结构化控制,面向 Qwen-Image 基座模型的高分辨率条件生成与编辑。作者提供基于 diffusers 的推理脚本(QwenImageControlNetPipeline)与训练细节,ComfyUI Day‑1 即集成并提供 subgraph 模板。建议在含文字的场景于 prompt 加入 'TEXT' 以保留小字,并通过 controlnet_conditioning_scale 调整控制强度。
标签:#QwenImage #ControlNet #InstantX #结构化生成 #ComfyUI
ComfyUI-VibeVoice:在 ComfyUI 中的多说话人 TTS 节点
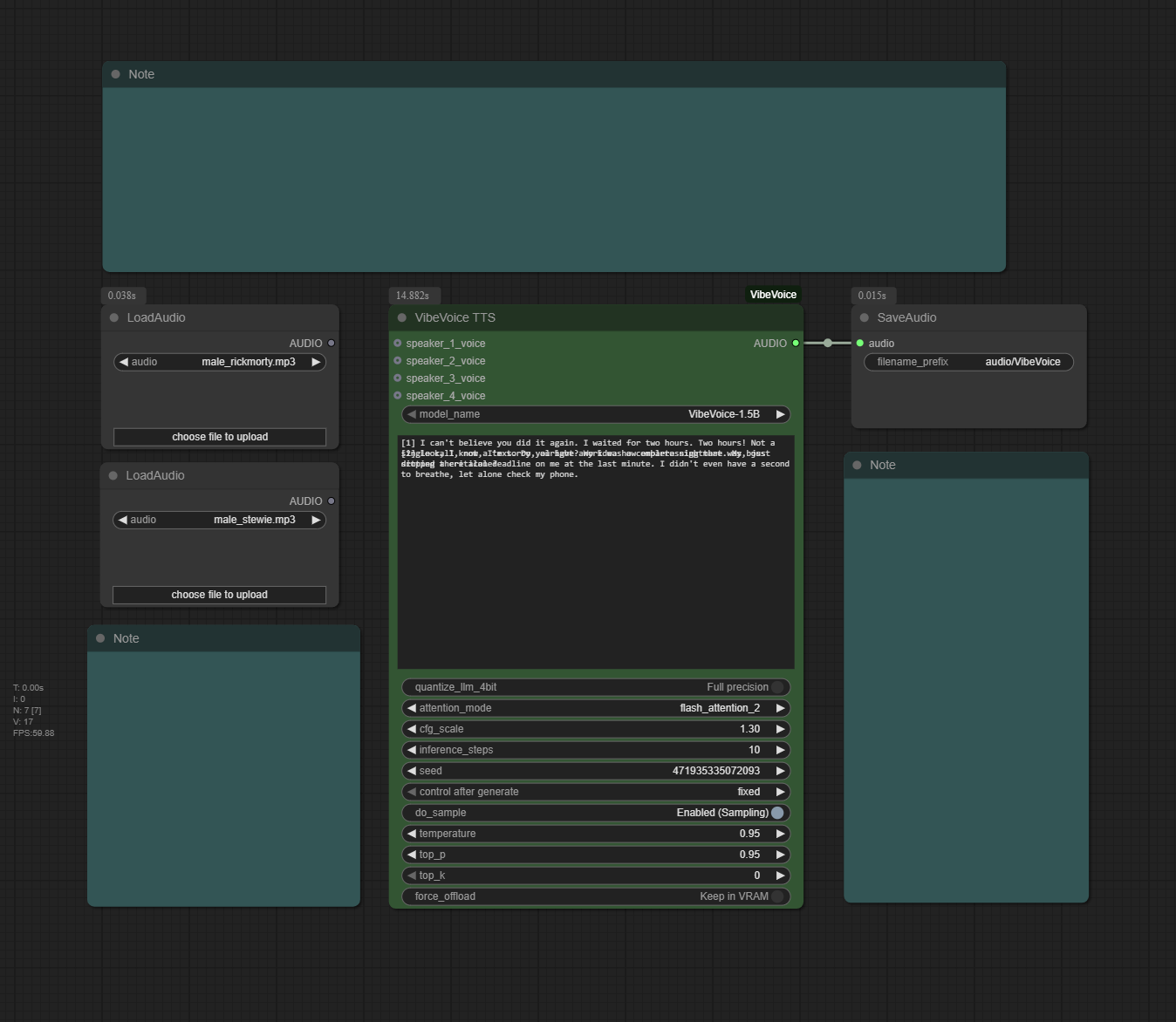
概要:ComfyUI‑VibeVoice 将微软 VibeVoice 集成到 ComfyUI,提供最多 4 人的多说话人输出、零样本克隆與自动模型管理,便于在可视化管道中生成对话音轨。通过 Speaker N: 指定说话人,节点会自动下载并缓存模型以节省 VRAM。安装可用 ComfyUI Manager,或将仓库克隆至 custom_nodes 并安装依赖后重启。
标签:#ComfyUI #VibeVoice #多说话人 #TTS #零样本克隆
WhisperLiveKit:实时转写与 diarization 工具包
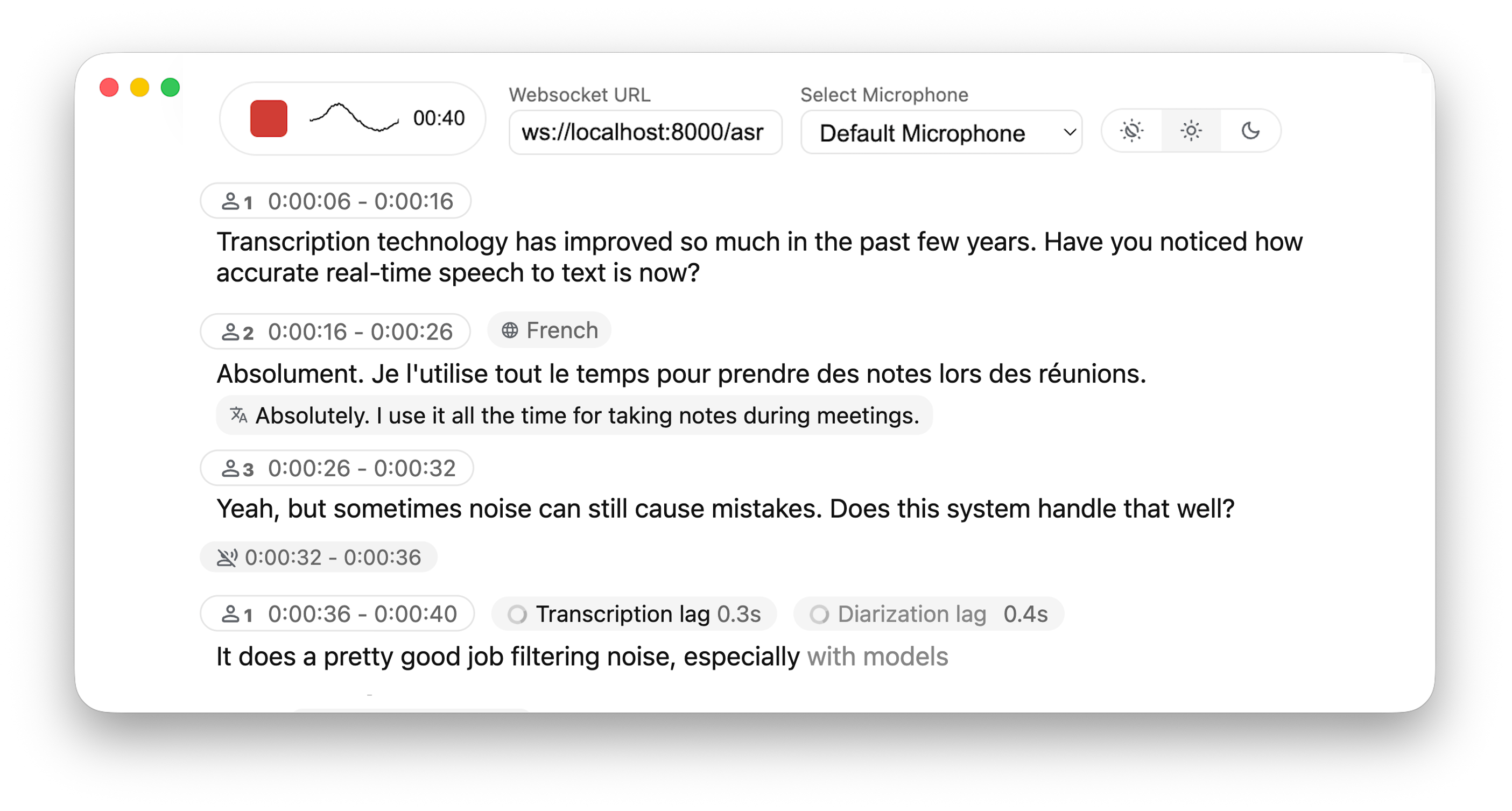
概要:WhisperLiveKit 提供本地实时转写服务器與 Web 前端,支持 SimulStreaming、Whisper 與 Sortformer 等后端,适合会议、直播與低延迟场景。支持说话人分离(Sortformer/Diart)、Docker 与 CLI 部署(示例:whisperlivekit-server --model base --language en),并内置 HTML/JS 前端用于 WebSocket 测试与集成。
标签:#WhisperLiveKit #实时转写 #diarization #SimulStreaming #直播转写
OmniHuman-1.5:认知仿真驱动的长时序角色动画

概要:OmniHuman‑1.5 以“系统1/系统2”认知仿真为核心,提出双系统架构结合多模态 LLM 與 Diffusion Transformer,从单张图像與音轨生成连贯的长时序人物动画,可表现情绪与复杂动作并支持多角色场景。演示含超过 1 分钟的连续表演與摄像机运动。项目页與论文含示例、BibTeX 與伦理说明;该系统可与 VibeVoice 與 WhisperLiveKit 组合为端到端创作流水线。
标签:#OmniHuman1_5 #虚拟人 #角色动画 #认知仿真 #多模态