【论文精读】Transformer:Attention Is All You Need
【论文精读】Transformer:Attention Is All You Need
摘要
Transformer 由 Vaswani 等人于 2017 年提出,首次完全基于自注意力机制(Self-Attention)实现序列建模,摒弃了 RNN/CNN 结构。该模型极大提升了并行效率和长距离依赖建模能力,成为 NLP、CV 等多模态领域的基础架构。论文提出的多头注意力、位置编码等机制,推动了大模型和生成式 AI 的快速发展。
目录
背景与研究目标
- 领域背景:序列建模任务(如机器翻译、文本生成)传统依赖 RNN/CNN,存在并行效率低、长距离依赖难捕捉等问题。
- 核心问题:如何提升序列建模的效率与表达能力,突破 RNN 的时序瓶颈。
- 研究目标:提出一种完全基于注意力机制的模型,实现高效、可扩展的序列建模。
- 论文特点:作者排序随机,贡献明细透明,代码开源。标题"Attention is all you need"成为学术梗,对后续研究影响深远。
方法与创新点
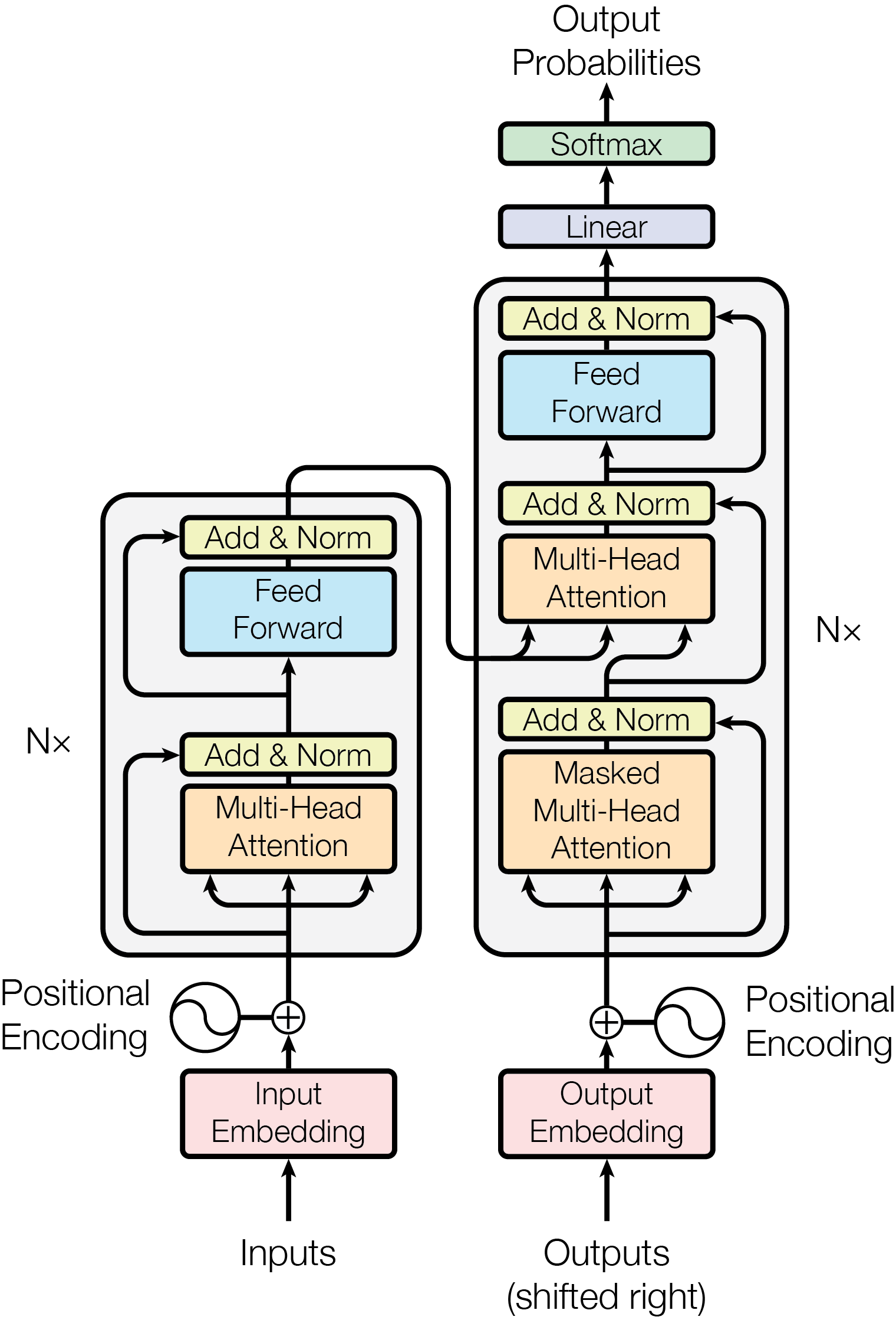
整体流程与核心思想
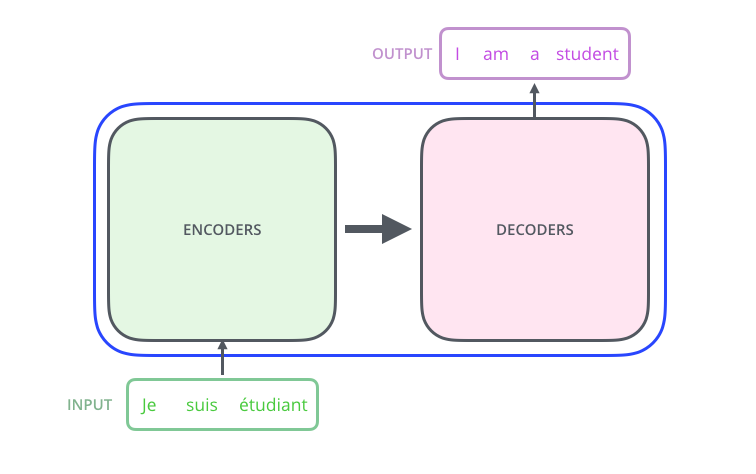
Transformer 采用编码器(Encoder)和解码器(Decoder)结构,每个模块由 6 个相同层堆叠而成。每层包含自注意力机制和前馈网络。核心优势:每个 token 能直接与序列中所有 token 建立联系,实现全局依赖建模。
1. 输入嵌入与位置编码
- 词嵌入:将输入 token 映射为 512 维向量,编码器和解码器共享权重。
- 位置编码:用正弦/余弦函数编码位置信息,与词嵌入相加: $$ \text{PE}{(pos,2i)} = \sin\left(\frac{pos}{10000^{2i/d{model}}}\right),\quad \text{PE}{(pos,2i+1)} = \cos\left(\frac{pos}{10000^{2i/d{model}}}\right) $$
2. 自注意力机制(Self-Attention)
- 核心原理:每个 token 通过 Query、Key、Value 三组向量与所有 token 计算相关性并加权聚合信息。
- 计算流程:
- 生成 Q、K、V:输入向量分别乘以权重矩阵 $WQ$、$WK$、$W^V$
- 计算注意力分数:Q 与 K 的点积,再除以 $\sqrt{d_k}$ 缩放
- 应用 Softmax 获得权重
- 加权求和:权重与 V 相乘得到输出

公式表示: $$ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$
三种应用场景:
- Encoder Self-Attention:编码器内部,Q、K、V 均来自上一层输出
- Decoder Masked Self-Attention:解码器内部,添加掩码防止看到未来信息
- Encoder-Decoder Attention:解码器中,Q 来自解码器,K、V 来自编码器输出
3. 多头注意力(Multi-Head Attention)
- 机制:将注意力机制并行计算 8 次,每次使用不同的线性投影。
- 优势:不同头可以关注不同的特征模式,类似 CNN 多通道。
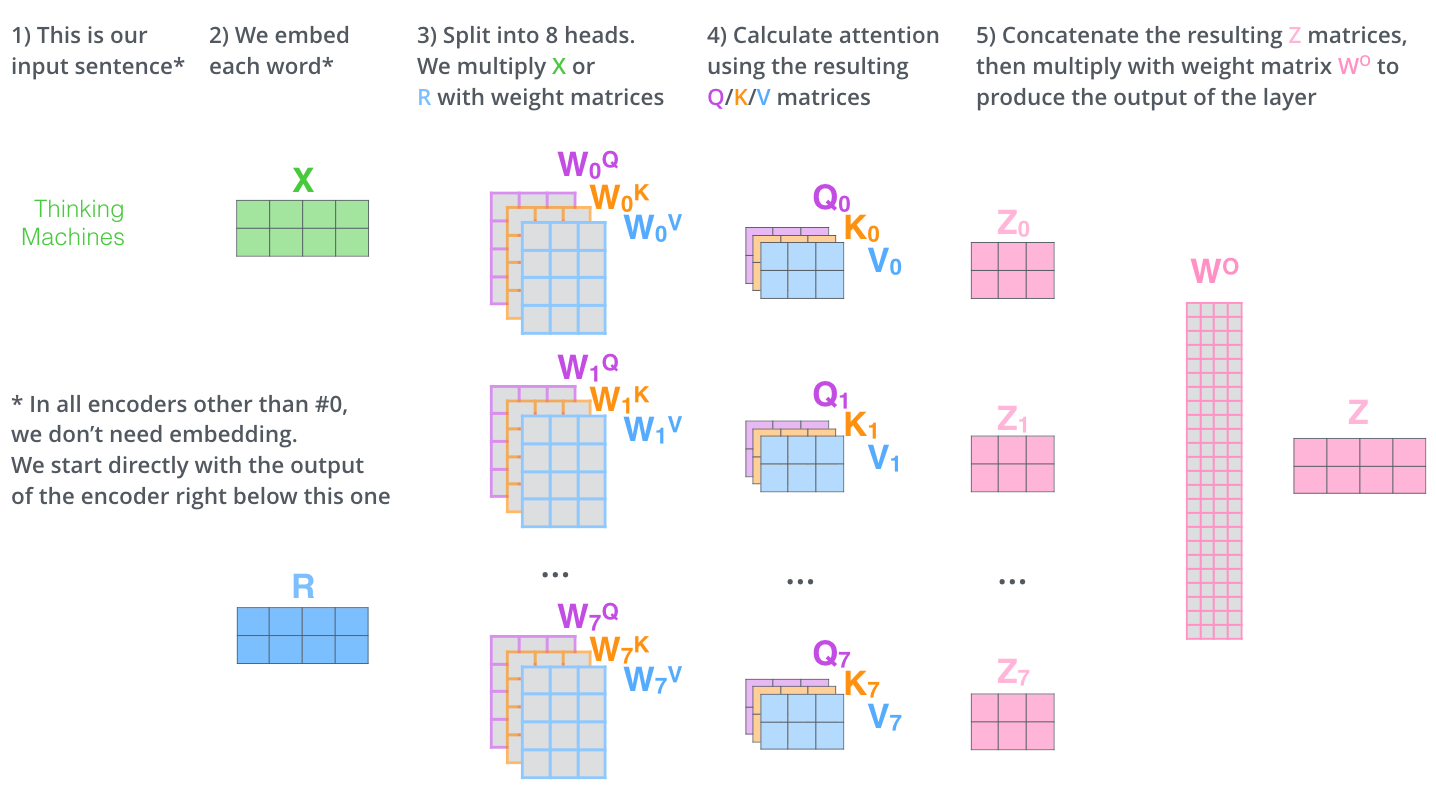
- 公式: $$ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, ..., \text{head}_h)W^O $$ 其中 $\text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)$
4. 前馈网络与残差连接
前馈网络:每个位置独立的两层全连接网络,中间使用 ReLU 激活函数: $$ \text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 $$
残差连接与层归一化:每个子层输出加上输入,再应用 LayerNorm,表示为
LayerNorm(x + Sublayer(x))。
5. 解码过程
- 自回归生成:解码器每次生成一个 token,将已生成序列作为输入。
- Mask 机制:在解码器的自注意力层使用掩码,防止看到未来信息。
关键创新点总结
| 创新点 | 原理/机制 | 优势与影响 |
|---|---|---|
| 自注意力机制 | 计算全局 token 间相关性 | 并行高效,捕捉长距离依赖 |
| 多头注意力 | 多组注意力并行计算 | 丰富特征表达,提升建模能力 |
| 位置编码 | 正弦/余弦函数编码位置信息 | 无需递归即可建模序列顺序 |
| 全注意力替代RNN | 摒弃递归与卷积,纯注意力架构 | 极大提升并行效率,易于扩展 |
| 残差+层归一化 | 每层后加残差连接与 LayerNorm | 稳定训练,缓解梯度消失 |
实验与结果分析
1. 训练设置与超参数
- 数据集:WMT 2014 英德(450万句对)、英法(3600万句对)
- 模型规模:
- Base:6层,$d_{model}=512$,$d_{ff}=2048$,8头,$d_k=d_v=64$
- Big:6层,$d_{model}=1024$,$d_{ff}=4096$,16头
- 训练细节:
- 硬件:8块 P100 GPU
- Base模型:12小时(100k步)
- Big模型:3.5天(300k步)
- 优化器:Adam + 自适应学习率调度
- 正则化:Dropout (0.1~0.3)、Label Smoothing (0.1)
2. 主要实验结果
| Model | EN-DE BLEU | EN-FR BLEU | 训练成本 (FLOPs) |
|---|---|---|---|
| GNMT + RL | 24.6 | 39.9 | $2.3 \times 10^{19}$ |
| ConvS2S | 25.2 | 40.5 | $9.6 \times 10^{18}$ |
| Transformer (Base) | 27.3 | 38.1 | $3.3 \times 10^{18}$ |
| Transformer (Big) | 28.4 | 41.8 | $2.3 \times 10^{19}$ |
结论:Transformer 在翻译任务上超越当时所有模型,且训练成本更低。
3. 消融实验(表 3)
| 变体/超参 | BLEU 变化 | 说明 |
|---|---|---|
| 单头 attention | -0.9 | 多头更优,头数过多无益 |
| 前馈层宽度减小 | - | 表现下降 |
| 去除位置编码 | 大幅下降 | 位置编码不可或缺 |
| 去除残差/LayerNorm | 不收敛 | 训练极不稳定 |
| Dropout 调整 | - | 适当 dropout 防止过拟合 |
| learned pos embed | ≈ | 与 sin/cos 编码效果相近 |
4. 长序列建模效率分析
| 层类型 | 复杂度/层 | 顺序操作数 | 最大路径长度 |
|---|---|---|---|
| Self-Attention | $O(n^2 d)$ | $O(1)$ | $O(1)$ |
| RNN | $O(n d^2)$ | $O(n)$ | $O(n)$ |
| CNN | $O(k n d^2)$ | $O(1)$ | $O(\log_k n)$ |
| 限制Self-Attn | $O(r n d)$ | $O(1)$ | $O(n/r)$ |
分析:Self-Attention 并行度高($O(1)$ 顺序操作),路径最短($O(1)$),适合长距离依赖建模,但复杂度随序列长度二次增长。
5. 注意力可视化分析
不同注意力头学习不同的语言特征模式,如句法结构、指代关系等。

模型启发与方法延伸
- 通用性:已成为 NLP、CV、音频等多模态领域的基础架构
- 衍生模型:BERT、GPT、ViT 等都基于 Transformer 发展而来
- 工程优势:结构简单,参数少,易扩展,调参简单
- 局限性:归纳偏置弱,需要大数据支撑;计算复杂度随序列长度二次增长
结论与未来展望
Transformer 架构彻底变革了序列建模范式,其高效并行性和强大表达能力推动了大模型和生成式 AI 的发展。该架构简洁而强大,设计理念影响深远。未来 Transformer 将在多模态、长序列处理等方向持续演进,也为后续模型设计提供了范式参考。
参考链接
阅读提示
- 结合 The Illustrated Transformer 的可视化理解注意力机制
- 思考问题:为什么 Transformer 能取代 RNN?位置编码如何影响模型性能?多头注意力的直观意义是什么?
- 尝试从头实现简化版 Transformer,加深对核心机制的理解