PixelHacker图像修复新突破 | Voila开源语音大模型 | LegoGPT生成可搭建乐高积木【AI周报】
PixelHacker图像修复新突破 | Voila开源语音大模型 | LegoGPT生成可搭建乐高积木【AI周报】

摘要
本周亮点:PixelHacker引入语义结构引导,提升图像修复质量;Voila实现低延迟情感语音交互;LegoGPT从文本生成稳定LEGO结构;HunyuanCustom支持多模态视频定制;SOAP实现单图3D头像建模与动画控制。其余详见正文。
目录
- PixelHacker:结构与语义一致的图像修复模型
- Improving Editability in Image Generation with Layer-wise Memory:提升图像编辑一致性的层级记忆框架
- HunyuanCustom:腾讯推出多模态视频定制模型,强化身份一致性
- Voila:实时情感语音交互的开源大模型
- Flow-GRPO:将在线强化学习引入Flow Matching模型
- LegoGPT:从文本生成可构建的稳定 LEGO 模型
- SOAP:多风格可动画头像生成框架,支持单图3D建模
PixelHacker:结构与语义一致的图像修复模型
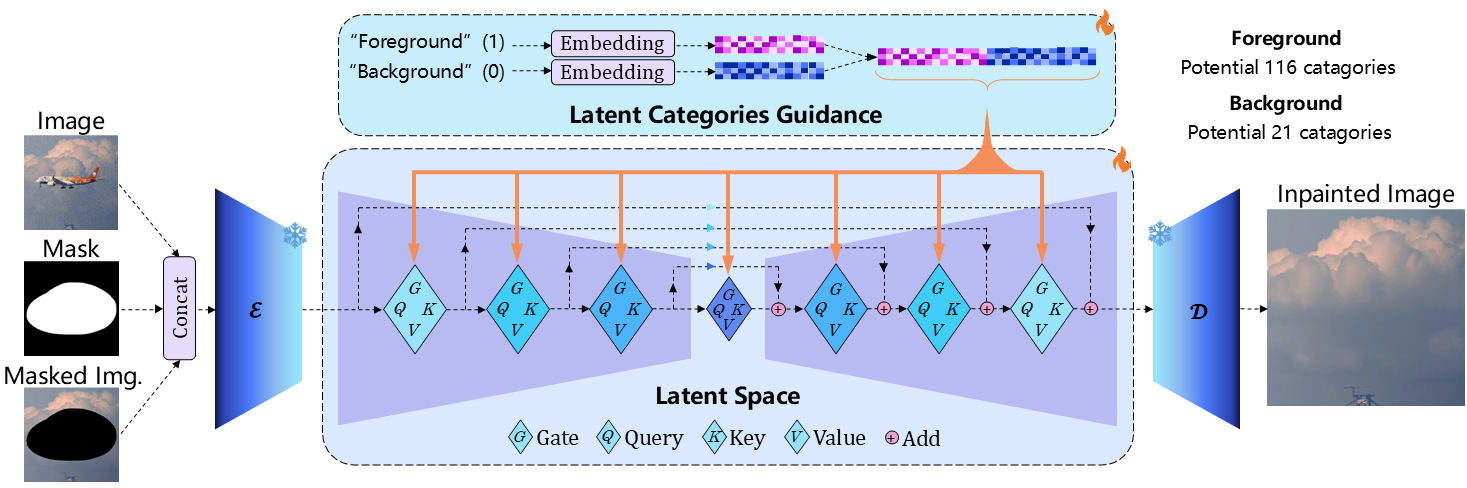
概要:由 华中科技大学 和 VIVO AI Lab 联合提出的 PixelHacker,是一种基于扩散模型的图像修复方法,强调结构与语义的一致性。该方法引入了“潜在类别引导”(Latent Categories Guidance, LCG)机制,通过在去噪过程中注入前景与背景的类别嵌入,提升修复结果的结构完整性和语义准确性。PixelHacker在Places2、CelebA-HQ和FFHQ等多个数据集上均超越现有SOTA方法,展现出卓越的修复能力。
标签:#图像修复 #扩散模型 #结构一致性 #语义一致性 #潜在类别引导
Improving Editability in Image Generation with Layer-wise Memory:提升图像编辑一致性的层级记忆框架

概要:Improving Editability in Image Generation with Layer-wise Memory 是由 首尔大学 研究团队提出的图像编辑框架,旨在解决多次编辑过程中内容一致性和控制性不足的问题。该方法引入了“层级记忆”机制,记录每次编辑的潜在表示和提示嵌入,结合背景一致性引导(Background Consistency Guidance)与多查询解耦(Multi-Query Disentanglement)策略,有效保持背景稳定性并自然融合新元素。用户仅需提供粗略的掩码输入,即可实现高质量的多轮图像编辑,显著提升编辑效率和结果一致性。
标签:#图像编辑 #多轮编辑 #一致性保持 #层级记忆 #CVPR2025
HunyuanCustom:腾讯推出多模态视频定制模型,强化身份一致性
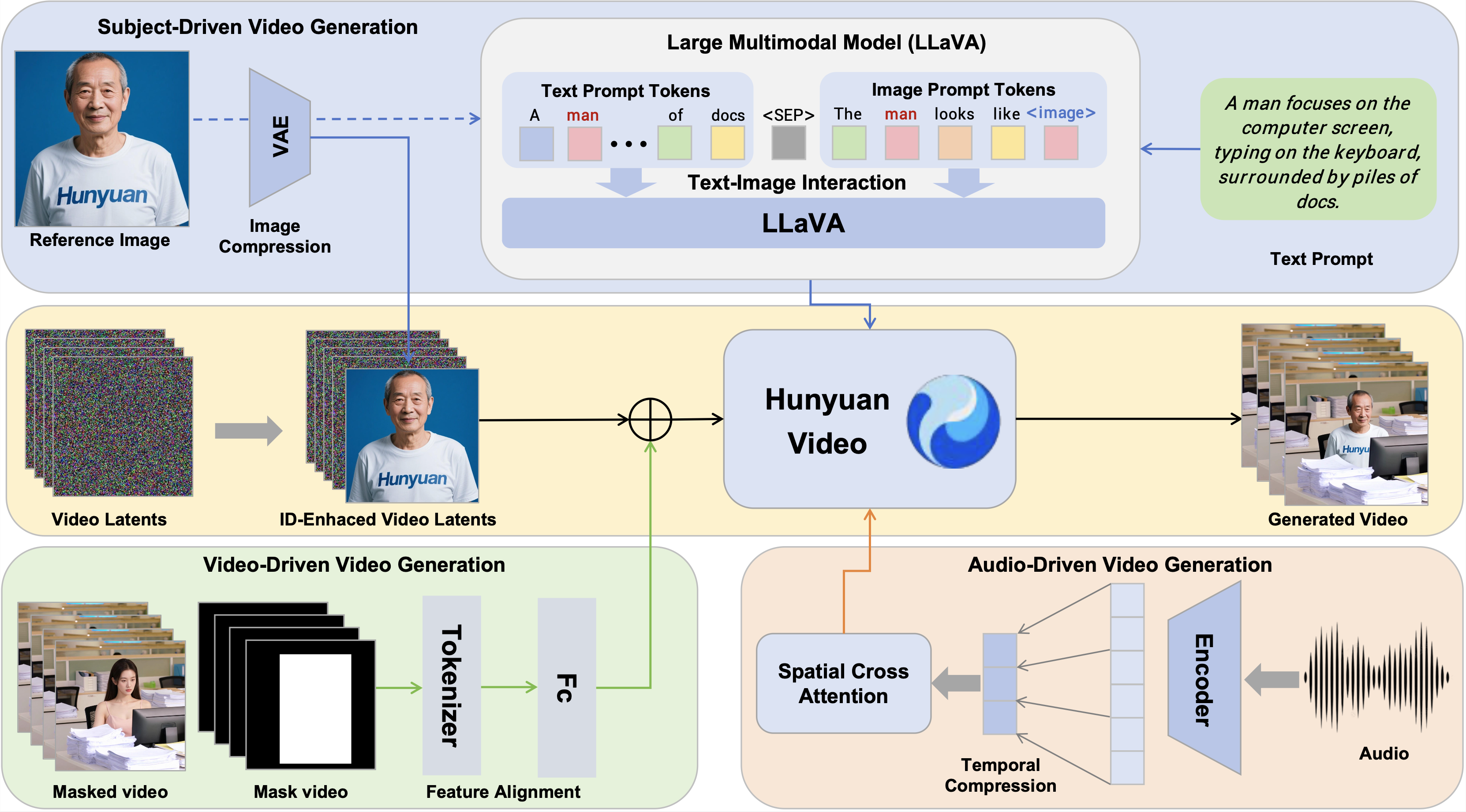
概要:HunyuanCustom 是 腾讯 发布的多模态视频生成模型,专注于在图像、文本、音频和视频等多种输入条件下实现身份一致性的视频定制。该模型基于 HunyuanVideo 构建,融合了 LLaVA 的图文融合模块和时间拼接的身份增强机制,确保视频中主体身份的一致性。此外,HunyuanCustom 引入了音频和视频特定的条件注入机制,实现了多模态输入的解耦控制。实验结果表明,该模型在身份一致性、生成质量和文本视频对齐方面均优于现有方法,适用于虚拟人广告、虚拟试穿和精细化视频编辑等多种应用场景。
标签:#视频生成 #多模态建模 #身份一致性 #可控生成 #虚拟人定制
Voila:实时情感语音交互的开源大模型

概要:Voila 是由 Maitrix.org、UC San Diego 和 MBZUAI 联合推出的开源语音语言基础模型系列,旨在实现低延迟、情感丰富的实时语音交互。该模型采用端到端架构,结合多尺度 Transformer 和大语言模型(LLM),实现了全双工对话和个性化语音生成,响应延迟仅为 195 毫秒,超过人类平均水平。Voila 支持超过百万种预设声音,并可通过 10 秒音频样本快速定制新声音,广泛应用于语音识别(ASR)、文本转语音(TTS)和多语种语音翻译等任务。项目已完全开源,促进下一代人机交互研究。
标签:#语音语言模型 #实时交互 #情感语音合成 #开源AI #多语种翻译
Flow-GRPO:将在线强化学习引入Flow Matching模型([arXiv][1])

概要:Flow-GRPO 是由 CUHK MMLab、清华大学 和 快手科技 联合提出的首个将在线强化学习(RL)机制引入 Flow Matching 模型的框架,旨在提升文本到图像生成的质量与控制能力。该方法通过两项关键技术实现:一是将确定性的常微分方程(ODE)转化为等价的随机微分方程(SDE),以便在 RL 训练中进行有效的采样探索;二是引入 Denoising Reduction 策略,减少训练过程中的去噪步骤,同时保持推理时的时间步数,从而提高采样效率而不降低性能。实验结果显示,Flow-GRPO 在多个文本到图像任务中表现出色,特别是在复杂构图、视觉文本渲染和人类偏好对齐等方面,显著提高了生成图像的准确性和质量。
标签:#Flow Matching #强化学习 #文本到图像生成 #采样效率 #图像质量提升
LegoGPT:从文本生成可构建的稳定 LEGO 模型
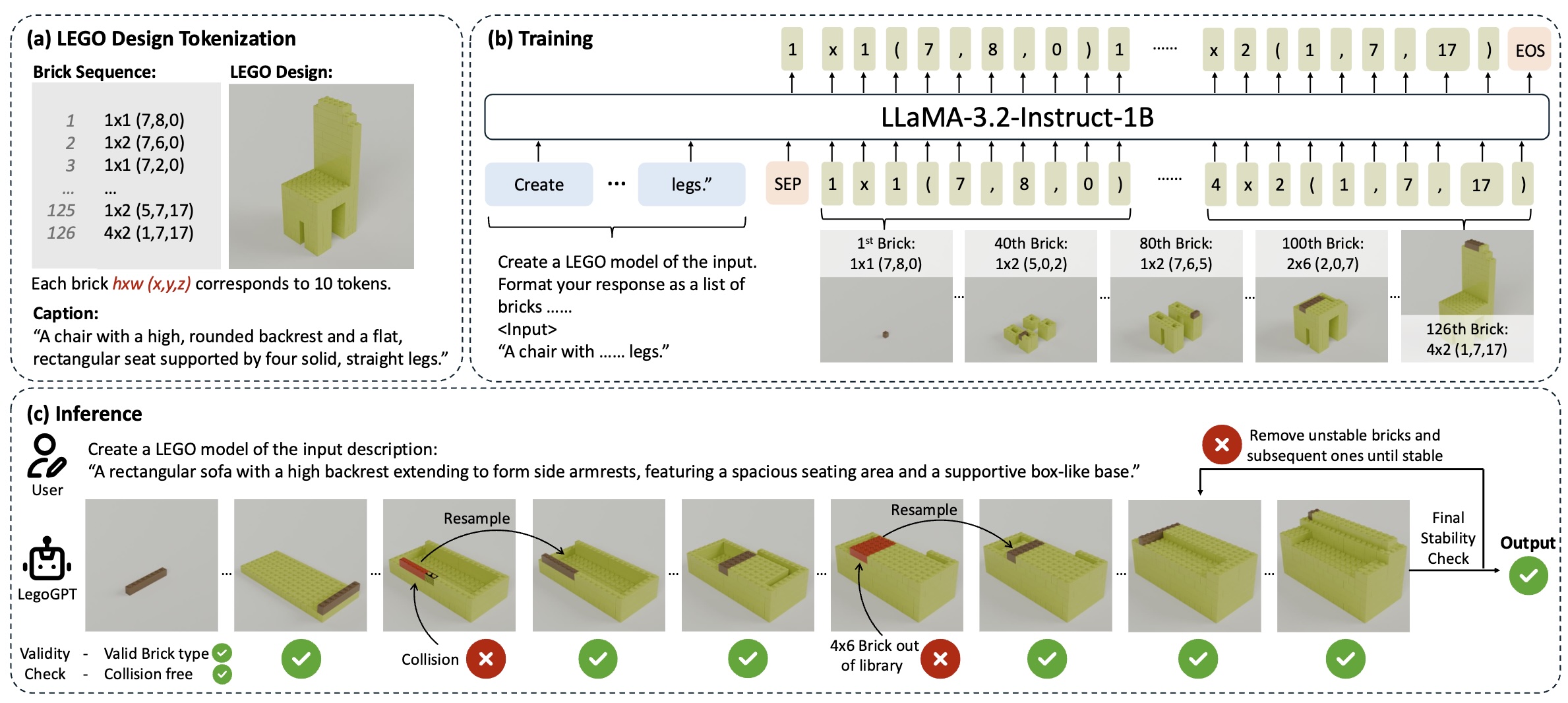
概要:LegoGPT 是由 Carnegie Mellon University 开发的首个能够从文本提示生成物理稳定且可构建的 LEGO 模型的 AI 系统。该方法基于自回归语言模型,结合物理稳定性分析和回滚机制,确保生成的结构在现实中可搭建。训练过程中,研究团队构建了包含 47,000 个 LEGO 结构的 StableText2Lego 数据集,并使用 LLaMA-3.2-Instruct-1B 模型进行微调。推理阶段,模型逐块预测 LEGO 砖块的位置和类型,结合物理约束进行验证,确保结构的稳定性。此外,LegoGPT 还支持生成带有颜色和纹理的 LEGO 模型,提升了视觉表现力。
标签:#文本到3D #物理稳定性 #LEGO生成 #自回归建模 #结构设计
SOAP:多风格可动画头像生成框架,支持单图3D建模
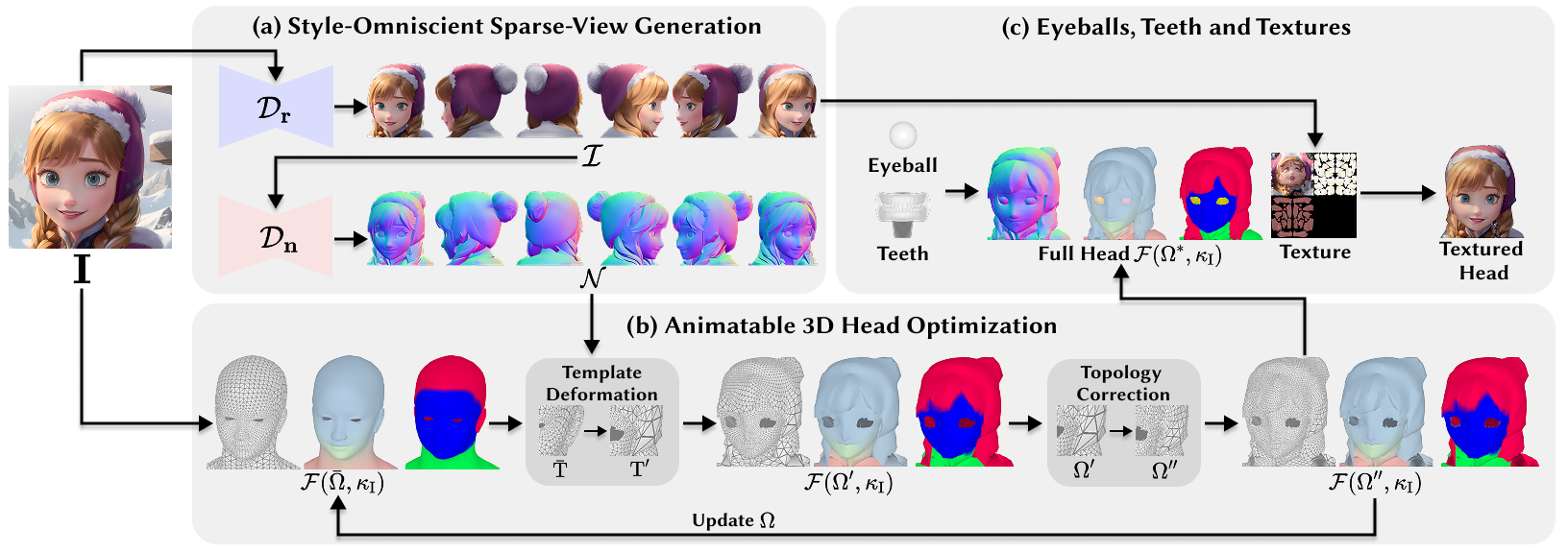
概要:SOAP 是由 MBZUAI 和 西湖大学 提出的多风格可动画头像生成框架,能够从单张图像生成带有拓扑一致性的可动画3D头像,适用于写实、卡通、动漫等多种风格。该方法利用多视角扩散模型和自适应优化管线,结合可微渲染技术,实现了对FLAME网格的变形,同时保持拓扑和绑定结构的一致性。生成的头像支持基于FACS的动画控制,集成了眼球和牙齿,并保留了如辫子发型和配饰等细节。实验结果表明,SOAP在单视图头部建模和基于扩散的图像到3D生成任务中优于现有技术。
标签:#3D头像生成 #多风格支持 #单图建模 #可动画控制 #拓扑一致性
参考链接
- PixelHacker 项目主页
- PixelHacker GitHub 仓库
- PixelHacker 论文链接
- Improving Editability GitHub 仓库
- Improving Editability 论文链接
- HunyuanCustom 项目主页
- HunyuanCustom GitHub 仓库
- HunyuanCustom 论文链接
- Voila 项目主页
- Voila GitHub 仓库
- Voila 论文链接
- Flow-GRPO GitHub 仓库
- Flow-GRPO 论文链接
- LegoGPT 项目主页
- LegoGPT GitHub 仓库
- LegoGPT 论文链接
- SOAP 项目主页
- SOAP GitHub 仓库
- SOAP 论文链接