
Illustrious XL 3.0-3.5-vpred: 2048分辨率与自然语言
Illustrious XL 3.0-3.5-vpred 标志着 Stable Diffusion XL(SD XL)模型的一项重大进展,显著支持从 256 到 2048 分辨率的无缝扩展。特别是 v3.5-vpred 变体,在自然语言理解能力上达到了类似于迷你大型语言模型(LLMs)的精细程度,这是通过对 CLIP 与 UNet 组件的广泛同时训练实现的。
训练目标与概述:eps 与 vpred
Illustrious v3.0-v3.5 系列设计了两种不同的训练目标以探索行为差异:
V3.0-epsilon 使用 epsilon 预测(噪声预测),确立了作为未来训练任务(尤其是与 LoRA 训练兼容)稳定"基底"模型的地位。该模型在默认状态下输出的风格较 vpred 变体更具特色,在某些美学评分中有时表现最佳。
V3.0-vpred 则采用 velocity 预测(v 参数化),展示出更强的组合理解能力,但最初伴随着严重问题,包括灾难性遗忘、领域偏移、颜色过饱和以及因零终端 SNR(Zero Terminal SNR)实现失误而导致的色板崩溃。
V3.5-vpred 则在实验性设置下训练,试图缓解上述问题。该模型显示出颜色更稳定,但并不天然生成鲜艳色彩,其功能已转移至特定的控制令牌(controlling tokens)。
不幸的是,v 参数化变体在微调 / PEFT 方面存在一些问题,我认为这是 Illustrious 系列中非常关键的特性。目前正在进行细致测试,以解决该模型稳定微调的方法,并将在后续分享当前对此现象的假设。

 58.46% 的像素颜色为"纯白 #FFFFFF"。这是一个异常结果,表明 v 参数化目标模型可能会发生崩溃。
58.46% 的像素颜色为"纯白 #FFFFFF"。这是一个异常结果,表明 v 参数化目标模型可能会发生崩溃。
v 参数化技术中的技术挑战
v 参数化的主要问题在于,由于零终端 SNR(Zero Terminal SNR)导致的方差估计错误。这一误差使模型在初期过度移除噪声,过早高估图像清晰度,从而导致整个去噪过程中颜色饱和度过高或不真实。
尽管存在这些挑战,v 参数化仍带来了显著的组合改进。例如,该模型能够成功解释复杂的方向性提示(例如"左侧是黑色,右侧是红色"),这一成就此前的 epsilon 模型难以实现。
(不过,epsilon 模型在随机性无法解释的布局方面有显著改进。见下文)
对比测试——颜色分离与复杂提示
以下展示三种不同设置:
- 简单提示:使用少于 75 个 token 的简单提示进行推理。
- 复杂提示(424 tokens):使用超长、复杂且经过"释义"的句子以混淆模型。
- 使用简单提示进行 FFT 分析:对模型中间潜变量进行FFT(快速傅立叶变换)分析,以研究低频信号变化。

模型部分遵循提示:"There are two girls in the image. The girl in the left is red hair with sea-black eyes. The girl in the right is blue hair, and firey ruby eyes" with high success rate, however exposes oversaturation in colors.
简单提示推理结果还展示了 v3.0 模型的一些有趣现象。
v3.0 Epsilon 同样显示出显著改进,这一点我仍然解释得不够充分。
"There are two girls in the image. The girl in the left is red hair with sea-black eyes. The girl in the right is blue hair, and firey ruby eyes" with high success rate, however exposes oversaturation in colors." 采样器:Euler,调度类型:Normal,CFG scale:7.5

v3.0-epsilon 推理结果。令人惊讶的是,epsilon 模型有时表现良好,这里是 25 次中有 23 次成功。

v3.0-vpred 推理结果。模型在默认情况下颜色过饱和。

v3.5-vpred 推理结果。模型呈现中间色调的颜色分离效果。
复杂提示推理结果
以下为用于推理的复杂提示:
A breathtaking scene unfolds with two girls standing together, a striking contrast in both appearance and demeanor. The girl on the left has flowing, deep red hair, cascading in soft waves down her shoulders, with strands illuminated by the ambient light. Her eyes are a mesmerizing shade of sea-black, like the ocean at midnight, deep and endless, reflecting a quiet mystery. She has a gentle, thoughtful expression, her lips slightly parted as if about to speak, her gaze filled with an unspoken story. She wears an elegant, dark-blue dress with silver embroidery resembling delicate ocean waves, flowing like liquid silk around her slender frame. The gentle breeze lifts the fabric slightly, giving her an ethereal presence.
Beside her, the girl on the right is a vivid contrast—her hair is a brilliant shade of blue, short yet tousled with an electric vibrancy, strands catching the light like crystalline ice. Her fiery ruby-red eyes burn with intensity, gleaming with an almost supernatural glow. Her sharp, confident smirk reveals her bold personality, a spirit unafraid of the world. She is clad in a striking ensemble—black with intricate red patterns resembling flickering flames, an outfit that exudes strength and energy. The contrast of her fiery eyes against her cool-toned hair creates an almost otherworldly effect, as if she embodies the elements themselves.
The setting complements their striking presence—perhaps a twilight sky over a vast ocean, where the last remnants of the sun cast a golden glow across the waves, mixing with the incoming darkness. The wind rustles through their hair as they stand close, an unspoken connection between them. Or maybe they are in a futuristic cityscape, neon lights reflecting in their eyes, the bustling energy of the world around them barely touching the silent understanding they share. Their postures mirror their personalities—one calm, introspective, a quiet storm; the other bold, fiery, a force of nature.
The image captures the balance between them—opposites yet intertwined, like fire and water, night and day. Their expressions, their outfits, and the atmosphere all tell a story waiting to be unraveled. masterpiece

v3.0-vpred 推理结果。模型无法生成稳定输出,暴露出颜色过饱和问题。

社区驱动的 v 参数化模型结果。模型同样存在颜色过饱和,且未能很好地遵循提示。


其他流行的 epsilon 预测模型结果。该提示揭示了模型的一些问题。

v3.0-epsilon 生成结果。模型能够生成相对更稳定的风格化输出,在所有结果中表现较好。

Flux.1-Schnell 生成结果。模型在遵循提示方面表现得非常出色,但缺乏风格化效果。

Illustrious-v3.5-vpred 生成结果。模型展示出与 Flux 类似的稳定生成效果,但失去了风格化生成,这一点与 v3.0-epsilon 不同。我注意到 Flux 的提示遵循"明显好且稳健",而 v3.5-vpred 的提示遵循"可能较为局限"——高度依赖提示的格式。
去噪模式分析
所有推理均使用 empty black background 提示,并采用 DDIM 10 步进行。

v3.0-epsilon

v3.0-vpred

v3.5-vpred
数学见解与调整
后续分析表明,对方差计算进行数学调整后,vpred 训练过程趋于稳定,显著提升了对提示词的理解能力。而 epsilon 模型仍然存在难以准确遵循复杂条件的问题,其原因在于对初始噪声采样的过度依赖,尽管它能够生成风格化的输出。
近期研究中提及的"黄金噪声"现象强调了良好初始噪声条件对模型性能的关键作用,这进一步证明了 vpred 方法在复杂提示词场景下的优越性。
简而言之,epsilon 模型主要关注低频特征,无法有效跨越色彩域,这导致了解剖结构问题以及糟糕的初始条件适应性。
相比之下,v-参数化模型能够通过初始阶段的高噪声去除来克服这一问题。

事实上,零终端 SNR(Zero Terminal SNR)或 v-参数化使得"第一步非常强",但对后续步骤作用有限。在第一步之后,主色调基本固定,低频特征也基本锁定,因此模型不再期望在后续步骤中调整主要色彩。
然而,由于"信噪比估计"(SNR Estimation)或方差计算的误差,颜色会在某一步骤发生回退。

这一现象相当复杂,无论使用何种采样器、调度器,甚至在推理过程中是否采用零终端 SNR,都会出现这一情况。
在没有 CFG(Classifier-Free Guidance)的情况下,模型的可视化效果有所提升——在"中间步骤"中,实际上尝试生成人工的高频特征!
由于模型并未经过大量"空白图像"的训练,因此模型天生假设"应该存在某种合理的高频特征",这一点与 epsilon 目标一致。这种假设(bias)是固有的。
此外,img2img 过程也表现出显著的特征:过冲(overshooting)潜变量在初始步骤后会出现明显的"颜色反转"。这意味着"模型在某种程度上学会了修正过冲现象"。我目前有一些想法可以验证并进一步改进这一现象,正在计划更多实验设置。初步思路是测试不同的采样器和调度器,以利用初始步骤的特性,并在后续步骤中指数级递减——这在理论上是合理的。
当我在数学上充分准备好解决这一过冲问题时,我将推出 Illustrious v4。
数据集见解与颜色控制
然而,对 v-参数化变体进行颜色控制的正确性同时暴露了另一个问题——
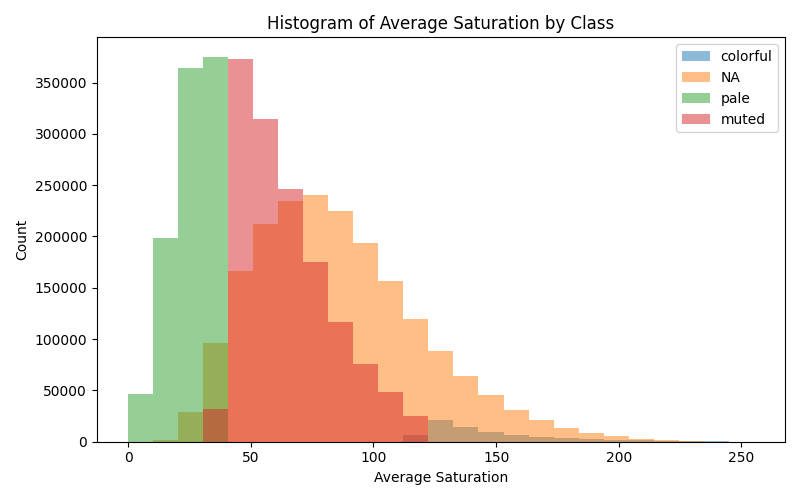
模型会遵循数据集的平均颜色。如果数据集中并不以鲜艳色彩为主导,那么期望模型自然生成鲜艳色彩是不现实的。
事实上,"变色"图像占比不到 10%——因此,模型在自然情况下不会显示鲜艳色彩。
以下是一个简单的颜色分析:
我们可以认为一张图像是"色彩丰富的",当其饱和度(saturation)大于 120,且饱和度标准差(saturation stdev)小于 50(表示色彩变化较少)。在对 440 万张图像的采样分析中,结果并不令人惊讶——大多数图像并非"色彩丰富"或"饱和"——那么模型又如何能学会"鲜艳色彩"呢?
数据集中仅有极少部分图像是"鲜艳或色彩丰富"的。
如果大多数图像都不鲜艳,我们如何在不牺牲柔和色彩的前提下控制颜色,而不让模型对特定颜色产生偏见?
答案是:进一步分析数据集,并引入控制标记(control tokens)。
在此,我们引入"控制标记",通过图像分析明确标记:
对比度(Contrast):'低对比度','中等对比度','高对比度','极高对比度'
亮度(Brightness):'暗','正常亮度','亮','极亮'
清晰度(Sharpness):'模糊','略微清晰','清晰','非常清晰'
动态色彩(Dynamic Colors):'静态色彩','中等动态色彩','高动态色彩','极高动态色彩'
色彩丰富度(Colorfulness):'单色调','中等色彩丰富度','高色彩丰富度','极高色彩丰富度'
饱和度(Saturation):'柔和色彩','普通色彩','鲜艳色彩','极鲜艳色彩'
控制标记专门适用于 v3.0-epsilon 和 v3.5-vpred 模型,但 v3.0-vpred 模型可能无法很好地适配这些标记。不过,视觉结果可能会因色彩鲜艳而显得"更具吸引力"——在使用适当提示词时,或许能得到令人满意的效果。
这一思路相当简单,但某些情况仍未得到良好处理。例如,数据集中"极暗"或"极白"图像的数量极少,这与某些观点(如"模型需要 #000000 或 #FFFFFF")相悖。
此外,常见短语"dark"(黑暗)可能存在歧义——对于某些应用场景而言,使用"black theme"(黑色主题)可能更为合适。
遗憾的是,我目前尚未有足够时间分析具体哪些区域包含这些 HSV 精确颜色——后续会对此进行进一步分析。
学术命名惯例
以下为 v3.0-epsilon 与 v3.5-vpred 的结果对比:


看到这两个结果,您可能会认为"第一幅图是 v3.5-vpred,第二幅图是 v3.0-epsilon",但事实并非如此——第一幅图出自 v3.0-epsilon,第二幅图则为 v3.5-vpred。
这里的命名完全出于学术考虑,尤其"3"代表"第三次学术突破"。
部分提示在不同版本上可能表现更佳。
演示版将尽快推出,届时您可进行比较与试验。
LoRA 训练问题
v 参数化模型上的 LoRA 训练效果不佳——这一问题在 v0.1-vpred 模型、noobai vpred 模型以及基于流的方法中均有所体现。一种假设是:低频特征本不适合在样本量有限的数据集上进行训练,其稳定性远逊于高频特征。由于 v 参数化模型在低信噪比步骤上给予更高权重,模型自然更易受到低频特征的影响,这导致去噪核出现大幅度崩溃。鉴于 LoRA 训练所使用的数据集远小于常规训练数据,其脆弱性几乎不可避免。
目前正在探索一种方法,即采用加权采样时间步长来缓解这一问题——因为模型似乎更受低信噪比步骤影响,并且增加鲁棒性有望改善这一状况。我希望能尽快展示令人满意的结果。
持续的研究与未来方向
Lumina-2.0-Illustrious(名称可能变更)目前正在 OnomaAI 的支持下进行训练,尽管预算有限。
从部分样本来看,我认为该模型目前已达到目标状态的"20% v0.1水平"——我们在训练过程中再次投入了数千美元,并经过多次试验与错误。当前正在仔细测试整体计算预算,待预算覆盖后,训练将加速进行。我们承诺,模型准备好后将开源,这将有助于新生态系统的构建。



理论上,训练成功后,该模型将类似于体积较小的自然语言理解 DiT 模型。
与 Flux 模型不同的是,这种模型在 LoRA 训练上的预算大幅降低——在最坏情况下,它可以作为最小的"草稿"生成器,稳健地理解各种设置与姿态的自然语言提示。在最佳情况下,我们甚至有望实现一次性生成图中嵌入文本的功能!
Flux 模型表现优秀,但训练计算量庞大,而模型本身也很庞大。这也是为何我们支持那些在预算范围内尝试训练或缩小 Flux 模型的人——这一点之前是秘密,如今已公开。我们将继续为开源社区做出贡献,可能是秘密进行,也可能公开进行。事实上,我们也已经尝试并公开了 SD3.5 模型的微调结果。您可能已经看到了一些效果。
我正准备披露更多内容,后会有期!