TextCrafter精准文本渲染|MoCha电影级角色合成|AnimeGamer动漫生活模拟【AI周报】
TextCrafter精准文本渲染|MoCha电影级角色合成|AnimeGamer动漫生活模拟【AI周报】

摘要
本周亮点:TextCrafter精准渲染文本;MoCha推出电影级角色合成;Any2Caption增强视频生成;AnimeGamer实现动漫生活模拟;ACTalker多模态音视频生成;OpenDeepSearch赋能搜索AI。其余详见正文。
目录
- TextCrafter:复杂视觉场景下的多文本精确渲染
- MoCha:迈向电影级别的角色合成
- Any2Caption:实现可控视频生成的通用条件描述
- AnimeGamer:基于多模态大语言模型的无限动漫生活模拟
- ACTalker:支持多模态控制的音视频生成框架
- DreamActor-M1:融合混合引导的人像动画生成框架
- OpenDeepSearch:开源推理代理赋能搜索AI
TextCrafter:复杂视觉场景下的多文本精确渲染

概要:TextCrafter 是由 南京大学PCALab 提出的一种新颖方法,旨在解决复杂视觉文本生成(CVTG)任务中存在的文本混淆、遗漏和模糊等问题。该方法采用渐进式策略,将复杂的视觉文本分解为独立组件,确保文本内容与其视觉载体之间的强对齐性。此外,TextCrafter 引入了令牌聚焦增强机制(token focus enhancement mechanism),在生成过程中突出视觉文本的重要性。研究团队还构建了新的基准数据集 CVTG-2K,用于严格评估生成模型在 CVTG 任务中的性能。实验结果表明,TextCrafter 在复杂场景的文本生成准确性方面优于现有技术。
标签:#复杂视觉文本生成 #CVTG #文本渲染 #DiT
MoCha:迈向电影级别的角色合成
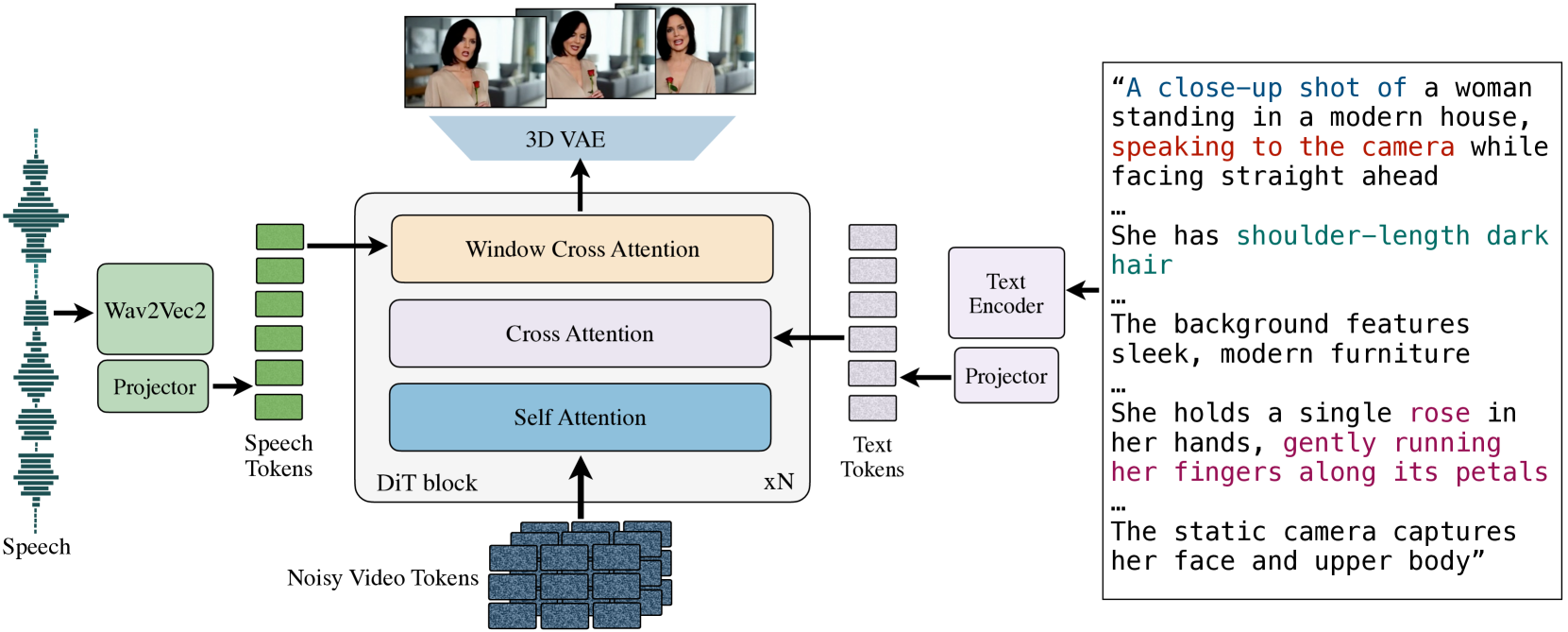
概要:MoCha 由 Meta GenAI 和 滑铁卢大学 联合推出,旨在直接从语音和文本生成全身说话角色动画。不同于传统的仅限于头部的生成方法,MoCha 能生成完整的人物形象。其核心创新包括引入语音-视频窗口注意力机制,确保语音与视频的精确同步;采用联合训练策略,利用语音和文本标注的视频数据,提升模型对多样化角色动作的泛化能力。此外,MoCha 设计了带有角色标签的结构化提示模板,实现多角色的轮流对话生成。实验结果显示,MoCha 在真实感、表现力、可控性和泛化性方面树立了新的标准。
标签:#角色合成 #视频生成 #语音驱动 #多角色对话 #注意力机制
Any2Caption:实现可控视频生成的通用条件描述

概要:Any2Caption 是由 快手科技 和 新加坡国立大学 等机构联合提出的框架,旨在通过解耦条件解释与视频合成步骤,实现对视频生成的精确控制。该方法利用多模态大语言模型(MLLMs),将文本、图像、视频以及区域、运动、摄像机姿态等特定线索转化为密集且结构化的描述,为视频生成模型提供更精确的指导。此外,研究团队构建了包含337K实例和407K条件的大规模数据集 Any2CapIns,用于任意条件到描述的指令微调。综合评估表明,Any2Caption 在提升视频生成模型的可控性和生成质量方面具有显著优势。
标签:#可控视频生成 #多模态大语言模型 #条件描述 #可控生成
AnimeGamer:基于多模态大语言模型的无限动漫生活模拟
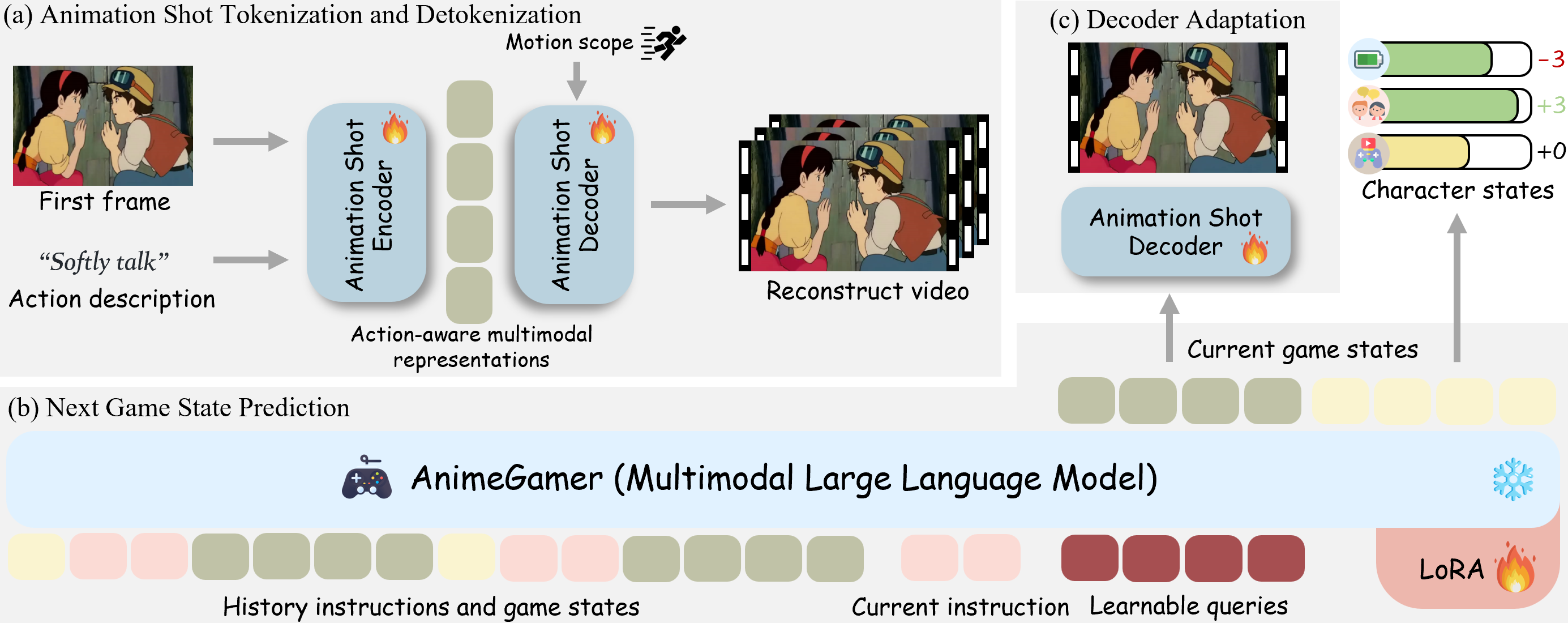
概要:AnimeGamer 由 腾讯ARC实验室 和 香港城市大学 联合推出,旨在通过多模态大语言模型(MLLMs)实现无限制的动漫生成。该方法通过引入动作感知的多模态表示,结合视频扩散模型,生成动态的动画片段,展现角色动作和状态更新。与传统方法相比,AnimeGamer 能够在游戏状态生成中保持上下文一致性和动态性,为玩家提供沉浸式的动漫角色体验。实验结果表明,AnimeGamer 在游戏体验的各个方面均优于现有方法。
标签:#动漫生活模拟 #多模态大语言模型 #视频生成 #游戏状态预测 #视频扩散模型
ACTalker:支持多模态控制的音视频生成框架
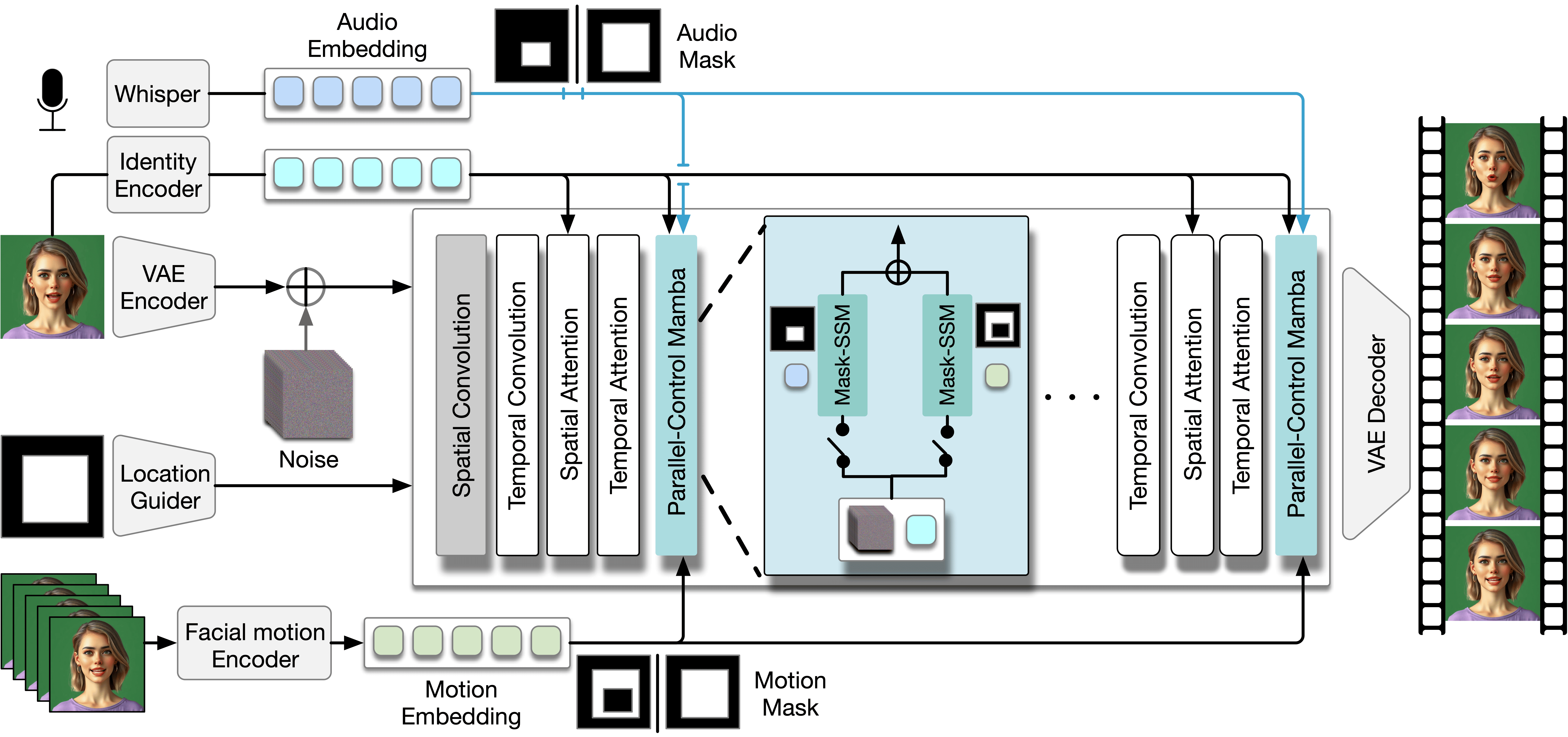
概要:ACTalker 是由 香港科技大学 和 腾讯 等机构联合提出的端到端视频扩散框架,旨在通过多信号控制生成自然的说话人头像视频。该框架设计了并行的 Mamba 结构,每个分支利用单独的驱动信号控制特定面部区域,并通过门控机制实现灵活的视频生成控制。为确保生成视频在时间和空间上的自然协调,ACTalker 引入了 Mask-SSM 策略,使每个驱动信号独立控制对应的面部区域,避免控制冲突。实验结果表明,该方法能够生成由多种信号驱动的自然面部视频,且 Mamba 层能够无缝整合多种驱动模态而无冲突。
标签:#说话人头像生成 #多模态控制 #视频扩散模型 #面部动画
DreamActor-M1:融合混合引导的人像动画生成框架
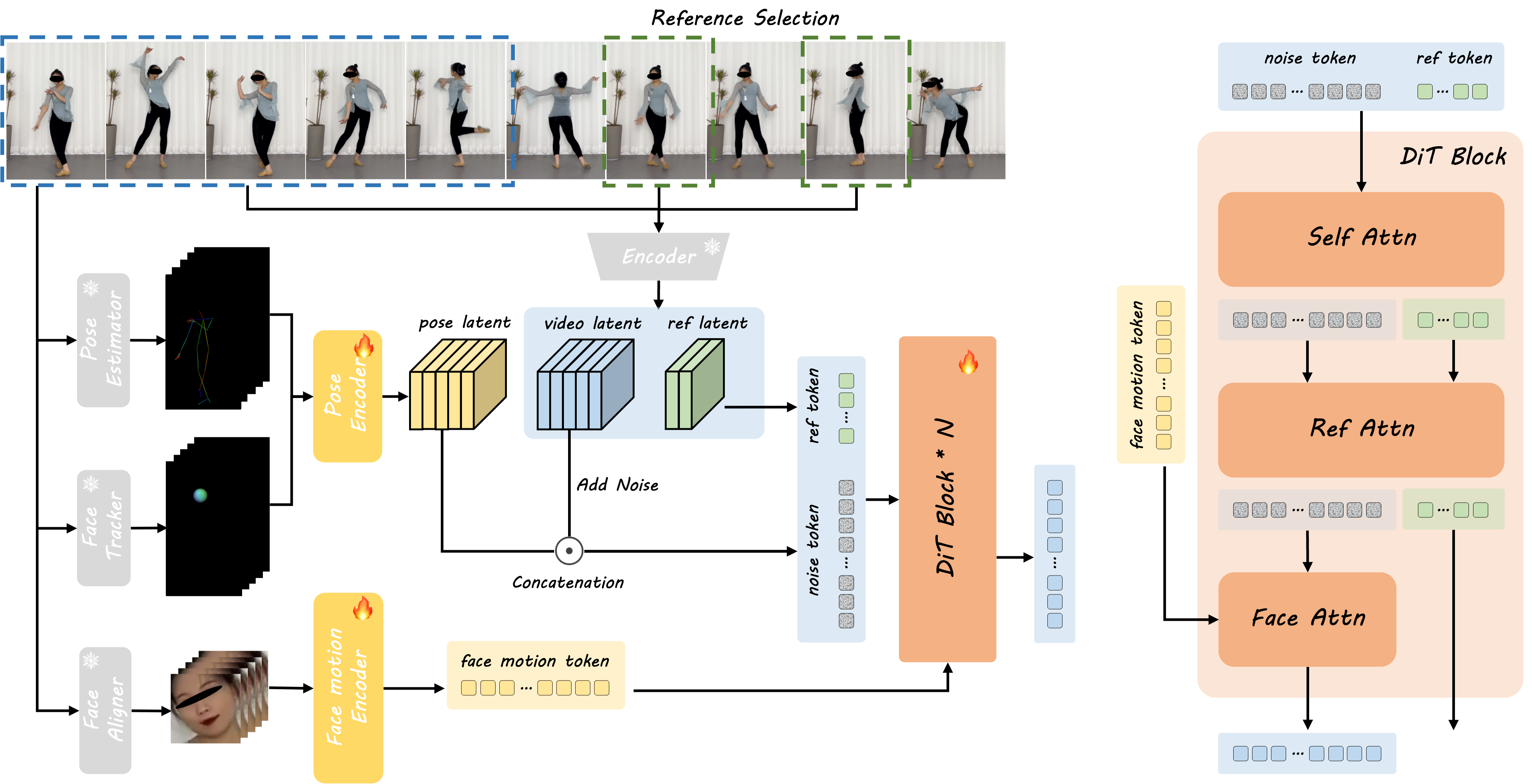
概要:DreamActor-M1 由 字节跳动智能创作团队 提出,是一个基于扩散Transformer(DiT)的创新人像动画生成框架,旨在解决现有人像动画方法在精细控制、多尺度适应性和长期时间一致性方面的不足。该方法通过融合隐式面部表示、3D头部球体和3D身体骨架,实现对面部表情和身体动作的精确控制,生成具有表现力且能保持身份一致性的人像动画。此外,采用渐进式训练策略,处理从肖像到全身等不同尺度的人体姿态,并通过整合连续帧的运动模式与互补的视觉参考,确保在复杂动作中的长期时间一致性。实验结果表明,DreamActor-M1 在肖像、上半身和全身动画生成方面均优于现有技术,生成的视频在视觉质量、时间一致性和身份保持方面表现出色。
标签:#人像动画 #扩散Transformer #混合引导 #时间一致性 #多尺度适应
OpenDeepSearch:开源推理代理赋能搜索AI
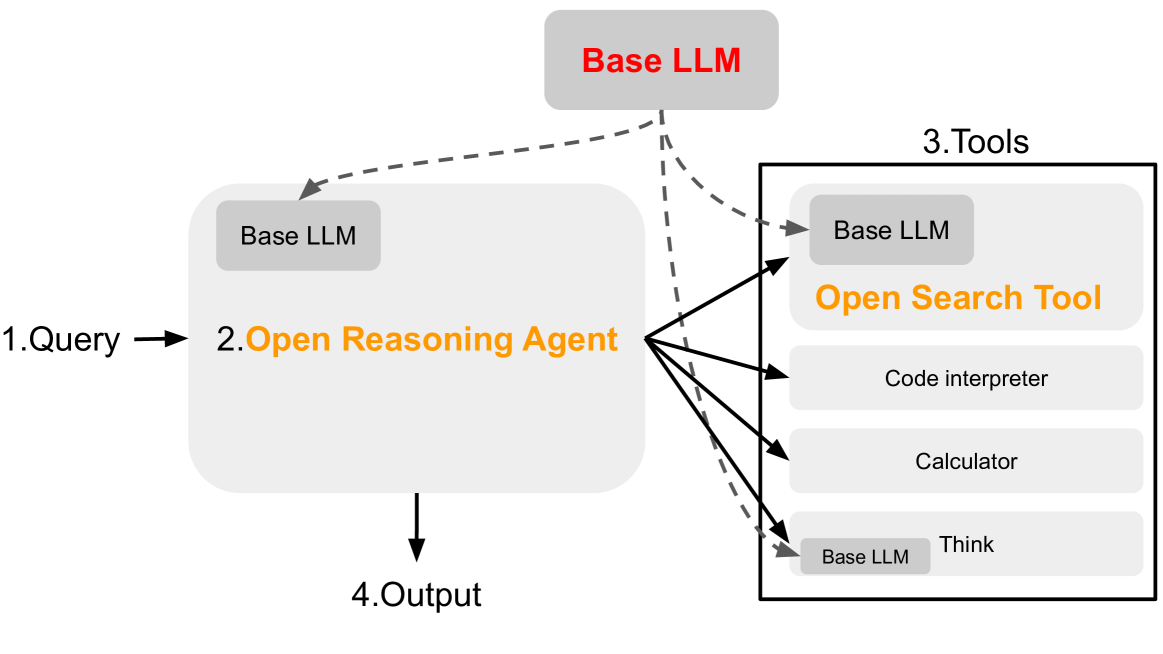
概要:OpenDeepSearch (ODS) 由 Sentient Foundation 开发,旨在缩小专有搜索AI解决方案(如Perplexity和ChatGPT Search)与开源替代方案之间的差距。ODS通过引入推理代理,增强了开源大型语言模型(LLMs)的推理能力,使其能够明智地利用网络搜索工具回答查询。具体而言,ODS包含两个核心组件:Open Search Tool和Open Reasoning Agent。Open Search Tool高效地从网络检索信息,而Open Reasoning Agent利用LLMs生成深入的回答。评估结果显示,ODS在单跳查询(如SimpleQA)上表现与闭源替代方案相当,在多跳查询(如FRAMES基准)上表现更优,准确率提高了9.7%。该项目的开源特性为企业和开发者提供了定制AI搜索解决方案的灵活性,推动了搜索增强AI的民主化进程。
标签 #推理代理 #搜索AI #LLMs #Agent