GLM‑4.1V‑Thinking注入多模态推理 | Keye-VL聚焦短视频理解 | Ovis-U1统一多模态生成【AI周报】
GLM‑4.1V‑Thinking注入多模态推理 | Keye-VL聚焦短视频理解 | Ovis-U1统一多模态生成【AI周报】

摘要
本周亮点:GLM‑4.1V‑Thinking多模态推理、Keye-VL短视频理解、Ovis-U1统一多模态生成、DepthAnything-AC深度估计、Calligrapher数字书法等。其余内容详见正文,代码、论文见文末参考链接。
目录
- GLM‑4.1V‑Thinking:视觉 LLM 理解与推理的多模态扩展
- Keye-VL:快手推出的多模态大语言模型视听理解专家
- LongAnimation:基于全局-局部记忆的视频动画色彩一致性生成
- Ovis‑U1:统一多模态理解、图像生成与编辑的 3B 参数模型
- DepthAnything‑AC:泛条件下的鲁棒单目深度估计系统
- Calligrapher:自由风格数字书法定制系统
GLM‑4.1V‑Thinking:视觉 LLM 理解与推理的多模态扩展

概要:GLM‑4.1V‑Thinking 是清华大学 THUDM 推出的视觉语言模型 GLM‑4.1V 的新版本,集成了“链式思维”(chain‑of‑thought)机制,增强其在图像理解和推理任务中的表现。该研究通过在图文对齐的基础上加入思维链监督,使模型能够生成连贯的中间推理步骤,从而在 Visual Spatial Reasoning、图文问答、场景理解等任务上提升 5‑10% 性能。评估显示与原始 GLM‑4.1V 相比,新增的逻辑推理能力使其在“多步推断”任务中效果更加准确、解释性更强。研究者开源了训练架构、示例数据与评测脚本,便于社区进一步扩展与落地。
标签:#视觉LLM #chain‑of‑thought #多模态推理 #GLM
Keye-VL:快手推出的多模态大语言模型视听理解专家
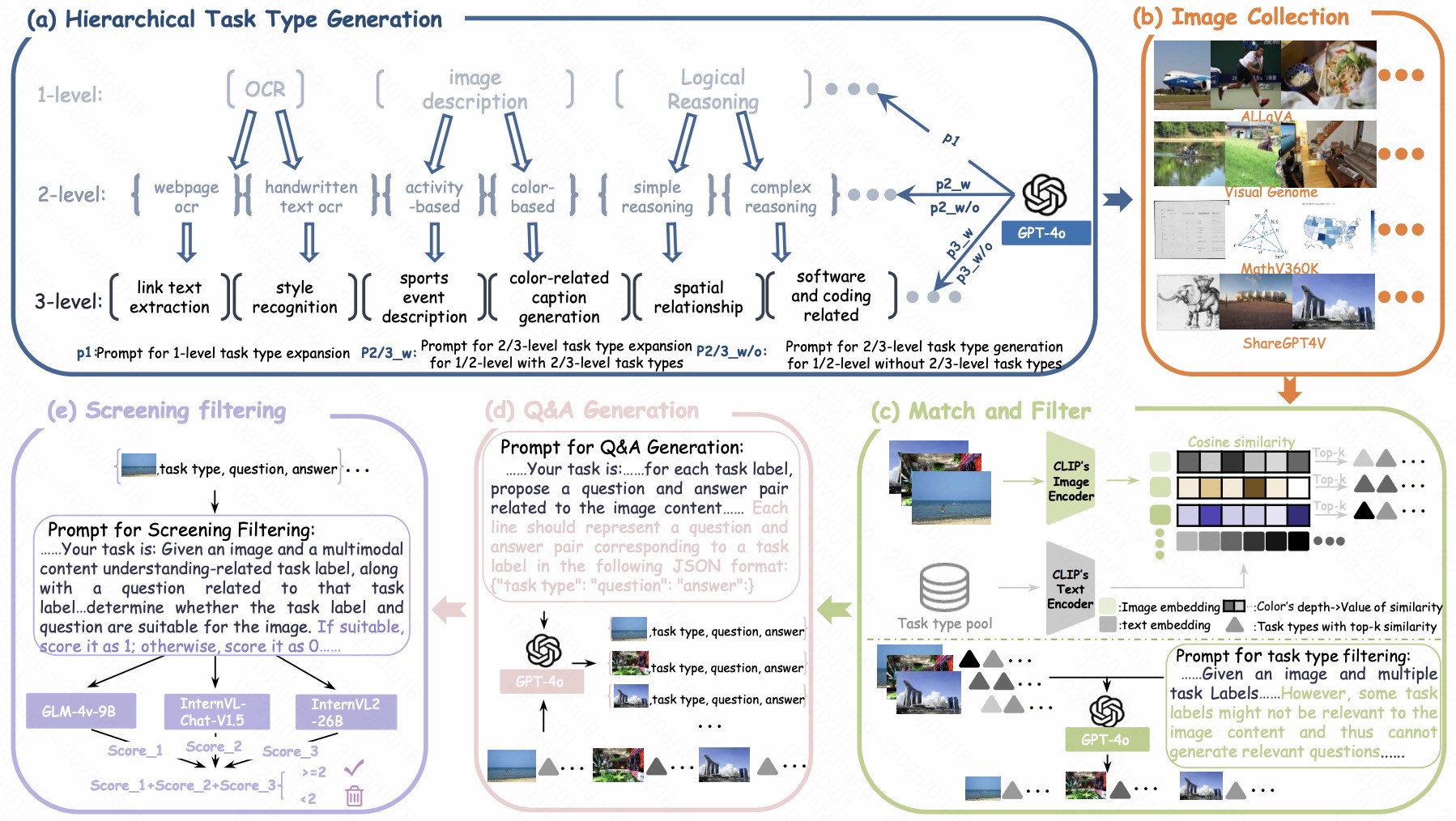
概要:Keye-VL 是由快手(Kuaishou)的 Keye 团队推出的 8B 参数开源多模态基础模型,专门优化用于短视频理解任务,同时保持强劲的图像与文本处理能力。该模型架构包含 SigLIP 初始化的视觉编码器、基于 Qwen3-8B 的语言解码器,以及动态分辨率支持和 3D RoPE 位置编码。训练流程分为四阶段预训练结合两阶段后训练,特别是在思维链与多模态推理策略上进行了创新。评测结果显示其在 Video-MME、TempCompass、KC-MMBench 等多个短视频基准任务中达到 SOTA 性能,并保留了图像理解竞争力 。项目完全开源于 GitHub 和 Hugging Face,提供模型、训练脚本与 Demo 工具,推动社区在视频多模态分析方向的进步。
标签:#多模态LLM #视频理解 #短视频 #理解生成融合 #情境推理
LongAnimation:基于全局-局部记忆的视频动画色彩一致性生成
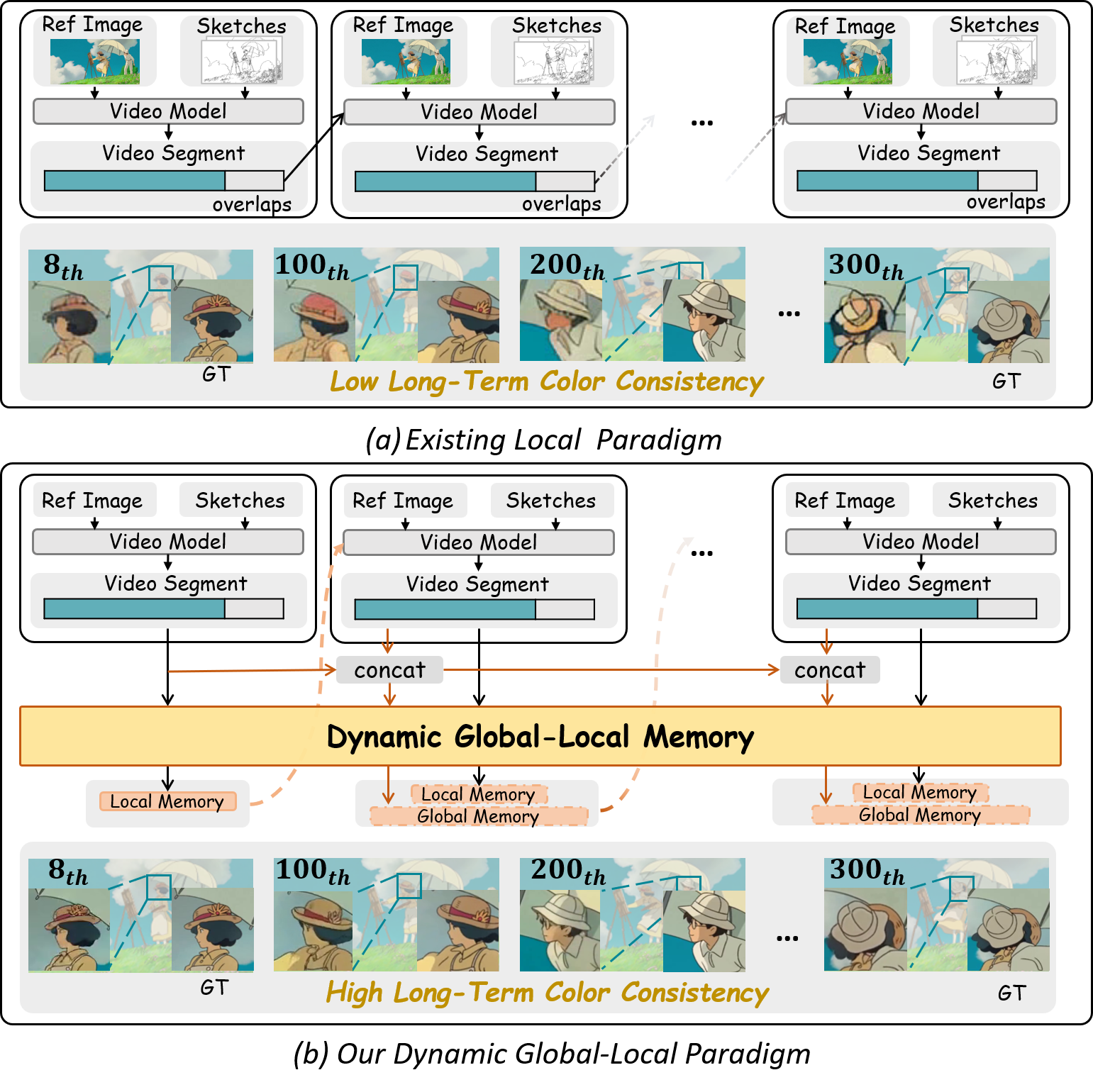
概要:LongAnimation 是由中国科学技术大学与香港科技大学提出的长动画色彩生成系统,旨在解决现有方法在长序列色彩一致性方面的不足。它创新性地引入“动态全局-局部记忆”(Dynamic Global-Local Memory, DGLM)机制,结合 SketchDiT 提取局部参考特征,并融合全局历史帧信息,再通过 Color Consistency Reward 进一步强化输出色彩的一致性。此外,生成过程中采用渐进融合策略,实现流畅过渡,实验展示其可稳定处理长达 500 帧动画,生成效果比短序列方法在 FVD 等指标上提升了 35% 至 49%。项目已于 ICCV 2025 接收,并在 GitHub 和演示网站公开代码和模型([github.com][1])。
标签:#视频生成 #颜色一致性 #长动画 #全局局部记忆 #扩散模型
Ovis‑U1:统一多模态理解、图像生成与编辑的 3B 参数模型

概要:Ovis‑U1 是由 AIDC‑AI(与阿里巴巴团队关联)提出的首个 30 亿参数级统一多模态模型,通过“一个模型完成理解、生成与编辑”获得突破。该模型基于 Ovis 系列架构,引入扩散型视觉解码器(MMDiT)与双向 token refiner,实现在图像理解、文本生成图像及图像编辑任务上的高性能表现。在统一训练流程中同时结合这三种任务,Ovis‑U1 在 OpenCompass 多模态学术评测中获得 69.6 分,高于同级开源模型;在 DPG-Bench/GenEval 文本生成图像基准中表现优异;在图像编辑基准 ImgEdit-Bench 和 GEdit-Bench-EN 上分别取得 4.00 和 6.42 分,全面超越闭源模型质量。项目采用 Apache‑2.0 授权开源,已发布 GitHub 源码、Hugging Face 模型与 Spaces 演示,支持 ComfyUI 插件集成,是目前最完整的“多模态理解-生成-编辑”端到端系统。
标签:#统一多模态 #图像理解 #文本生成图像 #图像编辑 #扩散解码器
DepthAnything‑AC:泛条件下的鲁棒单目深度估计系统
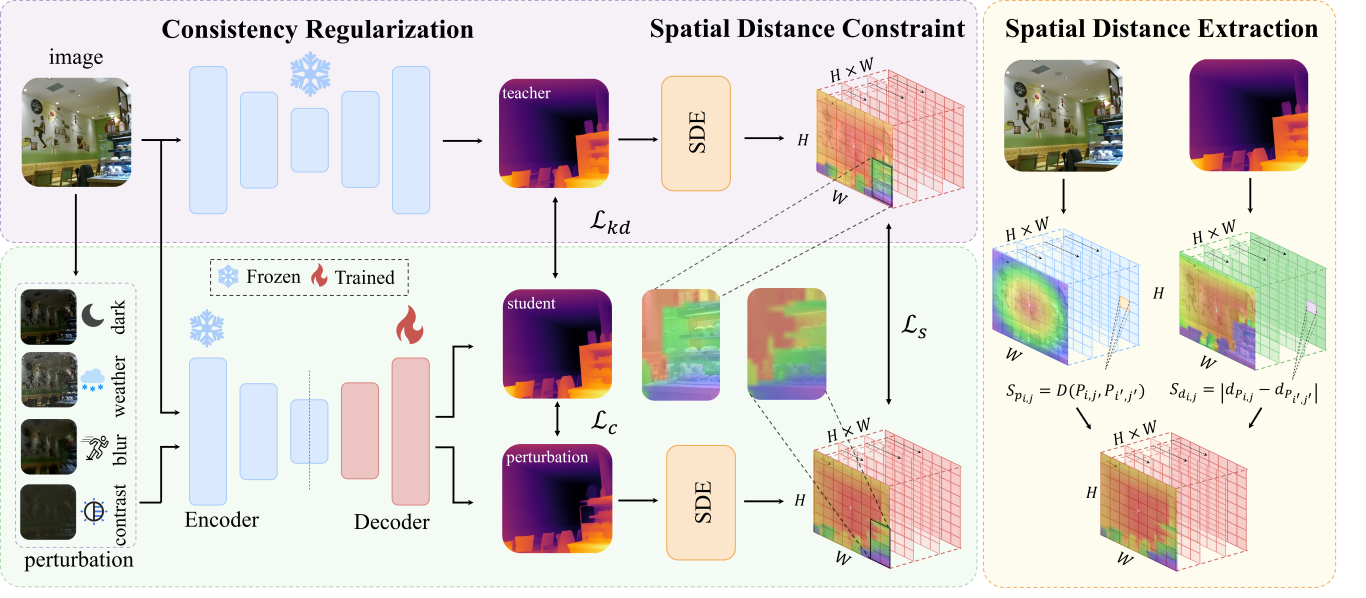
概要:DepthAnything‑AC 是由南开大学 VCIP 团队提出的单目深度估计模型,专门针对低光、雨雾等复杂环境,在无需标签的情况下进行微调。该方法引入无监督一致性正则化技术,结合空间距离约束(Spatial Distance Constraint),提升模型在语义边界和细节结构上的敏感性。实验结果显示,该模型在真实恶劣天气数据集和合成扰动测试中均获得出色表现,成为迄今为止复杂条件下最稳定的深度估计方案。项目代码、权重与评测工具已在 GitHub 与 Hugging Face 开源发布。
标签:#单目深度估计 #无监督 #一致性正则 #空间约束 #复杂环境
Calligrapher:自由风格数字书法定制系统

概要:Calligrapher 是华科与蚂蚁集团等联合提出的一种扩散模型驱动的高质量数字书法生成系统,专注于艺术级文字样式定制。该方法以“自由风格输入”为特色,通过自蒸馏机制构建风格基准数据集,局部风格注入编码器精细提取笔触风格,并结合参考图像嵌入 denoising 过程,实现高度一致的书法风格与精确字形定位。大量实验证明,Calligrapher 在多个字体与设计场景中都能忠实重现复杂书法细节,其输出精度和美学效果显著优于传统方法。项目已开源,提供训练代码、模型权重与示例演示,支持高质量排版与品牌设计应用 。
标签:#数字书法 #扩散模型 #风格注入 #自蒸馏 #艺术排版