【论文精读】Qwen-Image:原生文本渲染与一致性编辑的生成基础模型
大约 8 分钟
【论文精读】Qwen-Image:原生文本渲染与一致性编辑的生成基础模型
摘要
Qwen-Image 为 20B MMDiT 模型,聚焦复杂文本渲染与一致性编辑。借 MSRoPE、双编码与多任务训练及数据工程,在 OneIG/GenEval/DPG、GEdit/ImgEdit 等基准领先,中文与长文本尤佳。
目录
背景与研究目标
- 背景与挑战:主流文本到图像生成模型在“复杂文本渲染(多行、段落级、双语、非拉丁文字)”与“编辑一致性(仅改动目标、语义与视觉同时保真)”上仍存在明显短板。
- 数据与训练鸿沟:真实图像中的文本分布长尾,中文等表意文字更稀缺;多任务编辑对结构保持与指令对齐提出更高要求。
- 研究目标:构建一个统一的图像生成基础模型,兼顾高保真文本渲染与高一致性编辑,并在多基准广泛验证通用能力。
方法与创新点
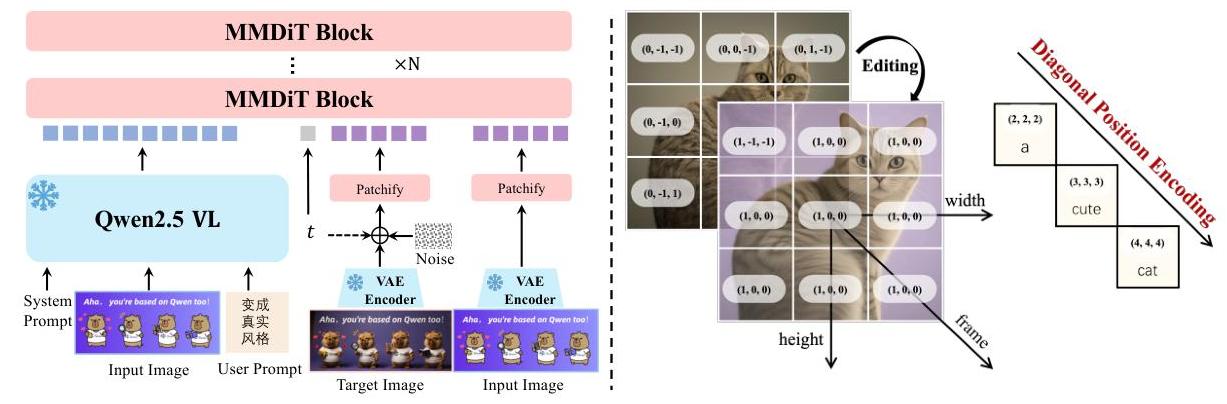
1. 整体流程(骨干与条件)
- 骨干网络:Multimodal Diffusion Transformer(MMDiT)。
- 条件编码:冻结的 Qwen2.5-VL 提供语义特征(文本/图像),VAE 提供像素级重建特征(单编码器、双解码器;仅图像解码器在富文本图像上微调,强化小字重建)。
- 双路条件融合:将 Qwen2.5-VL 的语义嵌入与 VAE 的重建潜变量分别注入 MMDiT 的文本流与图像流,实现“语义一致 + 视觉保真”的编辑约束。
2. 关键创新点
- MSRoPE(Multimodal Scalable RoPE)联合位置编码:将文本视为具有相同位置 ID 的 2D 张量,并沿图像网格对角线对齐,既保留图像侧分辨率缩放优势,又保持文本侧与 1D-RoPE 等效,显著提升文图对齐与可扩展性。
- 多任务训练范式:在 T2I(文本到图像)、TI2I(文本+图像到图像编辑)与 I2I 重建间联合优化,利用双编码输入与帧维度位置区分机制,增强复杂编辑(风格变换、局部替换、姿态操控)的一致性。
- 课程式训练与数据工程:七阶段过滤管线(破损/质量/对齐/文本密度/分辨率/类别平衡/多尺度),配合三类合成数据(纯渲染、复合渲染、结构模板渲染)补齐长尾字符与复杂布局;分辨率从 256→640→1328 渐进提升。
- 后训练对齐:SFT + DPO/GRPO 强化复杂指令遵循与可控生成(在 GenEval 等对齐基准上显著提升)。
3. 关键技术细节
- 文本渲染增强:文本语料严格渲染与质控;密集/极小字体样本过滤与平衡采样,兼顾真实与合成分布。
- 编辑一致性:输入图像同时进入 Qwen2.5-VL 与 VAE,两路特征在 MMDiT 端协同约束,减少无关区域漂移与语义偏移。
- 训练基础设施:生产者-消费者解耦(缓存已编码潜变量),配合 Megatron 混合并行,保障大规模稳定收敛。
实验与结果分析

1. 统一生成与编辑能力
- AI Arena 人评:开源模型中整体第 3,领先多款商用闭源模型(Elo 优势约 30+)。
- OneIG-Bench:中/英双赛道 Overall 均居首;Alignment 与 Text 维度优势显著。
- GenEval:基础版已超 SOTA,经 RL 提升至 0.91,是首个突破 0.9 的基础模型。
- DPG:Overall 88.32,属性/关系等细粒度维度全面领先。
2. 文本渲染(英文/中文/长文本)
| 图片 | 标题 |
|---|---|
 | 中文场景下多店铺与招牌、人物、卡片等复杂文本渲染案例 |
 | 对联、横批、青花瓷等多元素中文文本与场景渲染 |
 | 英文书店橱窗与多本书封面、海报等多文本渲染 |
 | 英文信息图表,多个模块与图标、长文本排版渲染 |
 | 小纸片上长段英文手写体文本渲染 |
 | 玻璃板上中英文混合长文本渲染 |
 | 玻璃板上中英文双语文本渲染 |
 | 海报风格多行英文文本与复杂画面渲染 |
 | PPT页面多图多文本、中文标题与排版渲染 |
- ChineseWord:三难度层级均第一,Overall 58.30,显著超越同类模型;
- LongText-Bench:中文第一、英文第二;
- CVTG-2K(英文多区域渲染):词级准确率与可读性指标处于第一梯队。
3. 图像编辑与视觉理解


- GEdit/ImgEdit:总体评分与细分任务均名列前茅,展示指令编辑的稳定性与保真度;
- 新视角合成(GSO):在 PSNR/SSIM/LPIPS 上与部分专用方法相当,整体具竞争力;
- 深度估计(多数据集零样本):接近专用判别式模型,验证“生成式理解”的有效性。
4. 结果解读
- MSRoPE + 双编码条件有效缓解“文本错漏/重影/位置跑偏”等典型问题;
- 多阶段数据工程与三类文本合成策略共同提升中文与长文本可读性;
- 多任务范式统一“生成-理解-编辑”,在跨任务迁移与一致性上具备优势。
模型启发与方法延伸
- 生成式理解范式:通过建模视觉内容的联合分布,让“理解任务”(深度、视角)作为特定编辑目标统一到生成框架内,减少“判别器依赖”。
- 文本优先的视觉接口(VLUI):当语言难以准确传达布局/颜色/空间关系时,直接生成“图文一体”的可视化解释,提高交互与表达效率。
- 工程可迁移性:MSRoPE 的对角拼接思想与双路条件融合,可迁移到文生视频、版式生成、UI 自动生成等需要“结构+文本”双对齐的场景。
- 数据治理要点:长尾字符与复杂版式需“合成+过滤+再平衡”的闭环;对非拉丁语种(如中文)的专门增强是获得实际可用性的关键。
结论与未来展望
- 贡献总结:提出 MSRoPE、双编码条件与多任务训练范式,配合系统性数据工程与课程式训练,显著提升复杂文本渲染与一致性编辑能力,并在多项权威基准上验证通用领先性。
- 优势与不足:在中文/长文本、复杂编辑与跨任务迁移上优势明显;对极端复杂排版、稀有字体/素材与更高分辨率的一致性仍有提升空间。
- 展望:向视频/3D 扩展的统一生成-理解系统;增强多语言长文本与结构化模板(海报/PPT/UI)可控生成;更强的人类偏好对齐与可解释性评测。