Wan2.1 FusionX视频生成升级 | Hunyuan3D-2.1高保真3D创作 | Show-o2统一多模态架构【AI周报】
Wan2.1 FusionX视频生成升级 | Hunyuan3D-2.1高保真3D创作 | Show-o2统一多模态架构【AI周报】

摘要
本周亮点:Wan2.1-FusionX视频生成提速25%;Hunyuan3D-2.1生产级PBR材质3D生成;Show-o2统一多模态架构;MiniMax-M1百万级上下文推理;PartPacker零件级3D生成;其余详见正文。
目录
- Only-Style-PP:聚焦风格精粹的图像迁移技术
- Ming‑Omni:首个全模态统一模型,融合语音与图像生成功能
- PartPacker:高效零件级 3D 对象生成模型
- Hunyuan3D‑2.1:可生成高保真PBR材质的单图3D资产系统
- Wan2.1-FusionX:社区驱动的高性能开源视频生成模型
- MiniMax-M1:全球首个百万级上下文混合专家推理模型
- Show-o2:原生增强统一多模态模型
Only-Style-PP:聚焦风格精粹的图像迁移技术

概要:Only‑Style‑PP 是由 雅典国家技术大学 团队提出的一种专注于“仅提取并迁移风格”的图像风格迁移方法。它通过创新的 Filter-and-Paste-Patch 流程,从源图像中精确提取风格,然后将风格信息转移到目标图像的内容区域,而有效避免内容特征的干扰。该方法在细节保真度和风格一致性方面表现突出,尤其适用于需要保持内容清晰而只改变风格的场景。
标签:#图像风格迁移 #风格保留 #FilterAndPastePatch #高保真
Ming‑Omni:首个全模态统一模型,融合语音与图像生成功能
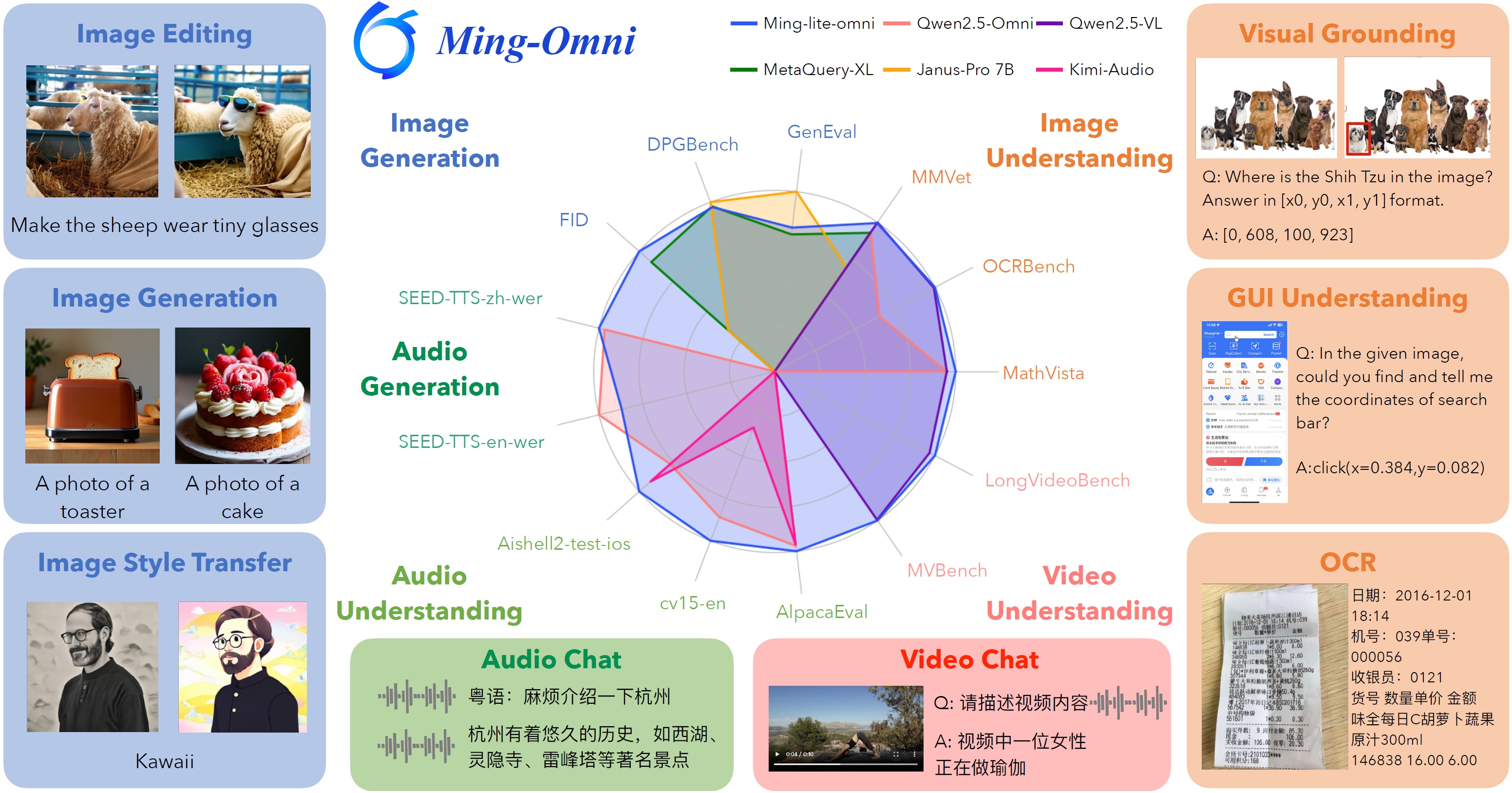
概要:Ming‑Omni 是由 Inclusion AI 与 Ant Group 联合推出的全新统一多模态模型,覆盖图像、文本、音频和视频的输入和生成能力。其核心架构采用多专家混合(MoE)设计,配备模态专用编码器与路由器(Ling),实现无缝模态融合。通过集成高质量音频解码器与图像生成模块(Ming‑Lite‑Uni),该模型能够进行上下文感知对话、文字转语音、图像生成与多模态编辑。Ming‑Lite‑Omni 版本仅启用 2.8B 参数却在图像、音频、视频与文字任务中的多项基准超越 Qwen 或 Gemini 等大型闭源模型,在跨模态表现上与 GPT‑4o 不相上下,是首个公开匹配其模态能力的开源模型 。
标签:#多模态模型 #统一感知生成 #MoE架构 #音频生成 #图像生成
PartPacker:高效零件级 3D 对象生成模型

概要:PartPacker 是由 NVIDIA Research、北京大学 和 斯坦福大学 合作推出的首个端到端单视图零件级 3D 对象生成框架。不同于常见的融合式网格,该方法通过“双体素封装”策略,将生成任务划分为两个互补体素结构,支持任意数量的语义独立部件生成。系统基于扩散 Transformer(DiT)架构,无需预分割,通过独特的体素打包机制,实现对每个部件的并行推理和高效生成。在 Objaverse‑XL 数据集上表现卓越,生成速度从数分钟缩短至 30 秒,且在质量、多样性和泛化能力上全面优于现有图像到 3D 零件生成方法 。项目已在 GitHub 和 Hugging Face Spaces 上开源,包含完整代码、预训练模型、演示接口和交互式体验,极大推动了可编辑 3D 内容自动化生成的研究进展。
标签:#3D生成 #零件级网格 #扩散Transformer #双体素封装 #可编辑
Hunyuan3D‑2.1:可生成高保真PBR材质的单图3D资产系统
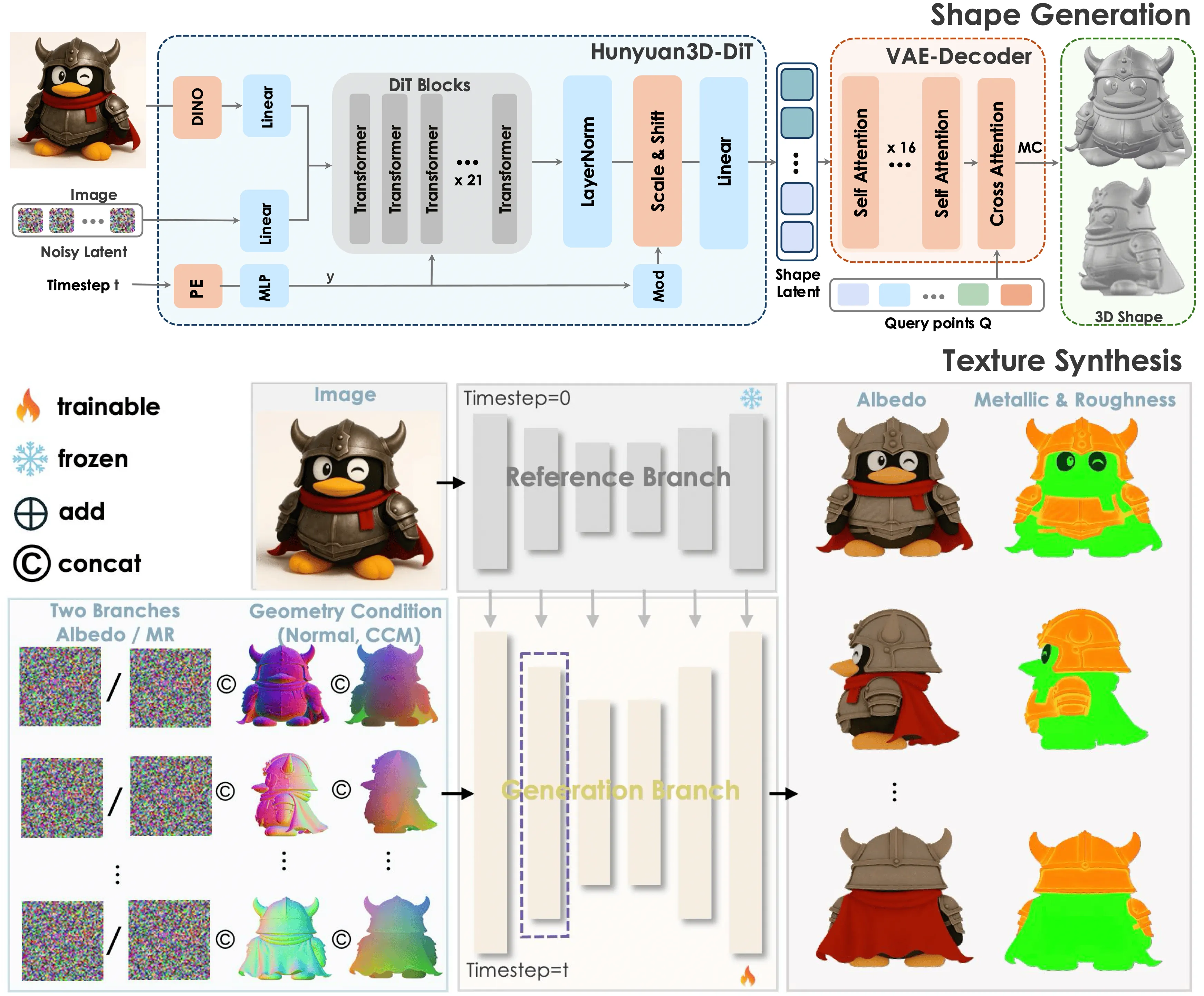
概要:Hunyuan3D‑2.1 是由 腾讯混元 团队开发的先进 3D 生成与纹理合成系统,面向游戏、影视、工业设计等生产级场景。该系统包括两个核心模块:Hunyuan3D‑DiT(形状生成)和 Hunyuan3D‑Paint(PBR 材质纹理合成),分别负责从单张图像生成高保真网格和物理基础渲染纹理。整个流程是模块化、可灵活选配多视角建模或仅形状输出,支持模型微调与真实部署。官方于 6 月 13 日全面开源,包括训练代码、权重和 demo,以及 Hugging Face Space 在线演示 。实验验证显示 Hunyuan3D‑2.1 在几何质量与纹理一致性上全面超越现有开源及闭源模型,生成速度从分钟级降至几十秒级,真正实现“生产级”3D 内容自动化。
标签:#3D生成 #PBR材质 #单图网格 #高保真 #模块化流程
Wan2.1-FusionX:社区驱动的高性能开源视频生成模型

概要:Wan2.1 FusionX 是社区贡献者(vrgamedevgirl84)基于 WAN 2.1 14B 模型打造的开源文本/图像驱动视频生成基础模型。它集成了多个研究型组件(如 CausVid、AccVideo、MoviiGen1.1、MPS Reward LoRA 等),显著提升生成流程中的动态流畅度、场景一致性与细节表现腰。该模型对 ComfyUI 极度友好,仅需 6–8 步即可生成高品质视频,且生成速度较原始 WAN 模型提升约 25%。最新版本还支持 LoRA 插件化,同时兼容 GGUF 格式,极大增强部署灵活性和社区模型融入能力。
标签:#视频生成 #文本生成视频 #社区贡献 #ComfyUI #LoRA
MiniMax-M1:全球首个百万级上下文混合专家推理模型

概要:MiniMax-M1 是由中国上海 MiniMax 团队推出的开源混合专家推理模型,具备混合稀疏 MoE 架构和高效 lightning attention 技术,支持长达 100 万 token 的上下文处理,相较 DeepSeek-R1 模型达到 8 倍上下文长度。该模型通过 CISPO 强化学习算法实现高效训练,仅耗时三周完成全量训练,成本低至约 $534,700。MiniMax-M1 在长文本推理、编程任务和复杂工具调用等方面表现出色,在 LiveCodeBench、GPQA 等基准中达到或超越 Qwen3-235B 和 DeepSeek-R1。
标签:#推理模型 #混合专家 #百万上下文 #强化学习 #高效推理
Show-o2:原生增强统一多模态模型

概要:Show-o2 是由 新加玻国立大学 Show Lab 与 字节跳动 联合推出的 Show-o 改进版本,采用单一 Transformer 架构融合自回归和流匹配机制,实现文本、图像、视频的统一理解与生成。该模型通过 3D 因果变分自编码器空间与双路径空间-时序融合结构,在语言 head 使用自回归,在图像/视频 head 应用流匹配(flow matching),有效统一多模态能力。Show-o2 支持视觉问答、图像生成、视频生成、引导修复/补全等任务,通过两阶段训练策略提升大尺度处理能力,在内容生成和理解任务中均达到或超过当前最佳水平。
标签:#统一多模态 #Transformer #自回归+流匹配 #3D VAE #图像视频生成
参考链接
- Only-Style-PP 项目页面
- Only-Style-PP Github 仓库
- Only-Style-PP 论文
- Ming-Omni 项目页面
- Ming-Omni Github 仓库
- Ming-Omni 论文
- PartPacker 项目页面
- PartPacker Github 仓库
- PartPacker 论文
- Hunyuan3D-2.1 项目页面
- Hunyuan3D-2.1 Github 仓库
- Hunyuan3D-2.1 论文
- Wan14BT2VFusioniX Hugging Face
- Wan14BT2VFusioniX Civitai
- MiniMax-M1 官网
- MiniMax-M1 Github 仓库
- MiniMax-M1 论文
- Show-o2 Github 仓库
- Show-o2 论文