
发布 Illustrious Text‑Enhancer:Tag Booster 和 Mood Enhancer
发布 Illustrious Text‑Enhancer:Tag Booster 和 Mood Enhancer
Illustrious 用户经常问:"如何在不编写冗长 Prompt 的情况下获得更好的结果?" 今天,我们很兴奋地通过 Text‑Enhancer 来回答这个问题,这是一个新系统,可以显著丰富用户 Prompt,用于我们的图像生成平台。
Text‑Enhancer 包含两个智能组件协同工作:
- Tag Booster: 基于我们的 TIPO(Text-to-Image Prompt Optimization)框架构建的 Prompt 增强工具。它扩展短或稀疏的 Prompt(无论是标签还是纯文本),通过将它们与我们模型训练数据中看到的分布对齐。结果是更高保真度的图像和更紧密的 Prompt-图像对齐。
- Mood Enhancer: 基于自定义 LLM 的管道,将最少的输入转换为详细、引人注目的图像 Prompt。通过利用固定的系统 Prompt 和少量示例(配合先进的 KV 缓存策略),它可以从稀疏输入生成丰富的描述,成本和延迟仅为通常 LLM 的一小部分。
Together, Tag Booster 和 Mood Enhancer 减轻了创作者手工制作冗长 Prompt 的负担,同时持续产生更高质量、更符合目标的生成结果。在这篇文章中,我们将深入探讨每个组件的工作原理、底层的技术创新(从多任务 Prompt 模型到 LLM KV 缓存),以及为什么这对 Illustrious 用户来说是一个游戏规则改变者。
从稀疏到丰富:Tag Booster 如何通过 TIPO 丰富 Prompt
从一行 Prompt 创建生动的图像是具有挑战性的——像 Illustrious XL 这样的扩散模型是在 Prompt/说明具有一定丰富性和多样性的数据集上训练的。Tag Booster 通过自动扩展和优化您的 Prompt 使其更像训练分布中的那些来弥补这一差距。它由我们内部的 TIPO 框架提供支持,这是一个专为 Prompt 优化而构建的轻量级多任务语言模型。
什么是 TIPO?
TIPO 代表 Text-to-Image Prompt Optimization——一种与多模态模型的杰出外部研究人员合作开发的新方法。与强力 Prompt 工程或昂贵的大语言模型方法不同,TIPO 使用一个小型、高效的模型(数亿参数,而不是数百亿)在 Prompt 对上训练。本质上,它学会了接受简单的 Prompt 并输出更丰富的 Prompt。从概念上讲,它"从 Prompt 空间的目标子分布中采样精炼的 Prompt",这意味着它添加了我们扩散模型期望的细节类型,在保持原始意图的同时。与使用原始 Prompt 相比,这产生了显著改善的视觉质量、连贯性和细节。
联合任务训练(Tags ↔ Text)
Tag Booster 的 TIPO 模型的一个关键创新是它是联合任务的——它可以处理标签列表和自然语言并将一个转换为另一个。在训练期间,我们给 TIPO 两种任务: "标签到文本" (例如,取一系列简洁的标签并产生完整的描述性句子)和 "文本到标签" (取一个短句并预测重要的标签或关键词)。通过学习两个方向,模型发展了对 Prompt 语义的灵活理解。在实践中,这意味着 Tag Booster 可以解释您的输入格式 并适当地丰富它:
- 如果您提供标签列表或几个词,它将添加高影响力的视觉标签,这些标签在训练数据中与这些概念在统计上相关。
- 如果您提供短句,它将用额外的描述符或风格关键词扩展它,有效地将自由形式的文本翻译成增强的富标签 Prompt。
例如,想象您只输入 "an autumn forest" 。这很短,可能产生一般性的结果。Tag Booster 可能将其丰富为:
- 输入: an autumn forest
- Tag Booster 输出: an autumn forest, golden sunlight, falling leaves, high detail, masterpiece, warm colors

通过添加细节("golden sunlight"、"falling leaves")和风格标签("high detail, masterpiece"),Prompt 现在更好地匹配我们模型的训练内容。这些额外的提示帮助扩散模型专注于预期的场景和美学。在内部测试中,这种方法在图像质量方面取得了显著提升——我们的评估者看到了更生动的色彩、更少的伪影,以及与 Prompt 意图更紧密对齐的构图。这与 TIPO 研究的发现相呼应,该研究报告了使用此类 Prompt 优化时"美学质量的显著改善、视觉伪影的显著减少,以及与目标分布的增强对齐"。
更重要的是,Tag Booster 运行极其快速。因为 TIPO 非常轻量级,添加这一步不会以任何明显的方式减慢生成速度——丰富 Prompt 只需几分之一秒。与仅仅附加固定"魔法关键词"集合的启发式方法不同,Tag Booster 是上下文感知的:它根据您的特定 Prompt 内容定制添加内容。增强的 Prompt 仍然感觉像是您想要的自然延伸,只是有更多细节和清晰度。最终结果是用户以最少的额外努力获得更高保真度的图像,让即使是一个词的 Prompt 也能闪耀,就像它们被精心设计的一样。
用更少努力创造生动叙述:Mood Enhancer 和 LLM 驱动的扩展
虽然 Tag Booster 擅长添加相关关键词和标签,我们也想帮助那些喜欢自然语言 Prompt 或对其图像有特定氛围或故事想法的用户。这就是 Mood Enhancer 发挥作用的地方。Mood Enhancer 使用自定义大语言模型 (LLM) 管道将简短想法转换为丰富、有氛围的 Prompt。如果 Tag Booster 关注精确性和保真度,Mood Enhancer 关注创造力和故事叙述,为 Prompt 注入生动的场景描述、背景和情感基调。
工作原理
我们为 LLM 制作了一个特殊的系统 prompt,配合一组少样本示例,让它学习理想 Illustrious prompt 的风格。例如,系统 prompt 可能说 "You are an art assistant that transforms short prompts into detailed visual descriptions. Include imaginative details and create atmosphere." 然后我们提供一些转换示例(就像向模型展示 prompt 的前后对比)。有了这个固定的 prompt 模板,当用户提供输入时,LLM 将按照这些示例生成详细的 prompt。
考虑用户输入:"futuristic city at night"。这是一个很酷的概念,但相当高层次。Mood Enhancer 会将其转换为:
"A sprawling futuristic cityscape at night, with neon-lit skyscrapers and flying vehicles weaving between the buildings. The streets below are illuminated by holographic billboards and reflected lights. Rain-soaked atmosphere and puddles reflecting neon signs add a cyberpunk mood."
注意稀疏的想法如何变成迷你故事:它保留了核心("futuristic city at night"),但添加了具体的视觉元素(霓虹灯、摩天大楼、全息广告牌)和氛围(雨天、赛博朋克氛围)。这种丰富的 prompt 可以引导扩散模型生成感觉像科幻电影画面的图像,而不是普通的城市。氛围的天赋和具体细节正是 Mood Enhancer 设计注入的。

KV 缓存:超级增强 LLM 效率
使用 LLM 扩展 prompt 引起了一个担忧:成本和速度。高质量的 LLM(具有大参数数量)运行可能缓慢或昂贵,特别是如果每次都要提供长系统 prompt 和示例。我们通过一个巧妙的优化解决了这个挑战:Key-Value 缓存重用用于 LLM 的 prompt。这种技术受到 LLM 部署的最新进展启发(甚至 Anthropic 的 Claude API 也引入了类似的 prompt 缓存 功能来减少多达 90% 的成本)。
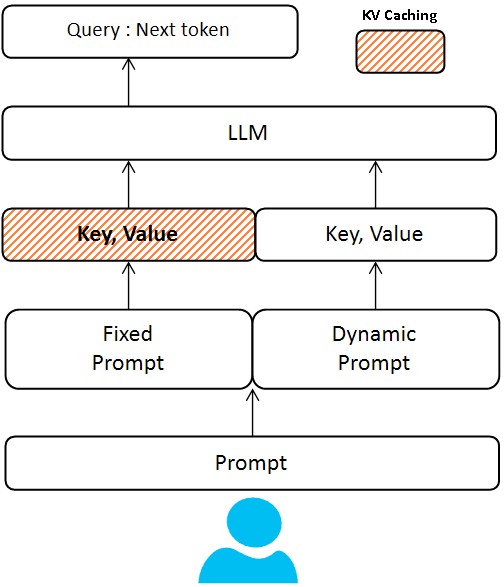
什么是 KV 缓存?
在自回归生成期间,LLM 构建内部 Key 和 Value 张量(自注意力机制的"记忆"),当它们消费 prompt token 时。通常,如果每次都重新生成,您需要为每个请求支付所有 prompt token 的计算成本。但是如果 prompt 的大部分总是相同的(在我们的情况下,Mood Enhancer 的系统消息和少样本示例是固定的),我们可以缓存其 KV 状态一次并重复使用。在实践中,我们通过静态 prompt 部分运行 LLM 一次(每会话或服务器预热),并存储每个 transformer 层的结果键值对。然后对于每个新用户输入,我们 用这个缓存的 KV 初始化 LLM 的状态 并从前缀末尾开始生成,就好像模型"已经看到了"系统 prompt 和示例。
这产生了巨大的效率提升。Mood Enhancer 的固定 prompt 可能相当长(比如说,500 个指令和示例 token 来确保高质量输出)。使用 KV 缓存,这 500 个 token 只处理一次;后续 prompt 只产生新用户输入(可能 5-50 个 token)加上输出 token 的计算。在我们的测试中,这将LLM 推理成本降至每次生成朴素成本的约 20%——有效地减少了 80% 的成本和显著的加速,而输出质量没有任何损失。这些数字与行业报告一致,prompt 缓存在某些场景中可以减少 多达 90% 的输入成本。
技术洞察 - 使其工作
以稳健的方式实现 KV 缓存需要处理一些 LLM 内部机制。现代 transformer 模型(包括我们用于 Mood Enhancer 的模型)经常对 token 使用旋转位置嵌入。这种相对定位方案对于处理长上下文很好,但我们必须确保我们的缓存机制保持位置一致性。简单来说,当我们缓存前缀时,模型已经为这些 token 分配了某些位置相位;当我们稍后附加用户的 token 时,我们必须无缝地继续位置编码,以便模型将其视为一个连续序列。我们通过在生成期间仔细管理位置索引来解决这个问题——本质上,模型在前缀和用户输入之间永远不会"重置",因此没有错位的机会。
另一个挑战是处理标准生成管道中的基于前缀的限制。现成的 API 或库通常假设您一次提供整个 prompt;它们不是为让您注入预计算前缀而设计的。为了克服这一点,我们集成了低级支持,允许在生成时将缓存的键和值反馈到模型中。我们的解决方案类似于最新 LLM API 现在提供的 prompt 缓存,但我们为我们的管道定制构建了它。我们还小心地锁定前缀的确切分词,以便用户输入中的任何内容都不会无意中改变 prompt 的解析方式(这是一个罕见的边缘情况,但我们彻底验证了)。通过这些工程修复,Mood Enhancer 可以在许多生成中安全地重用其 prompt 上下文。
结果?Mood Enhancer 转换的显著更低延迟和成本,使我们能够向用户提供此功能而没有明显的延迟。您实际上免费获得大模型 prompt 头脑风暴的好处,因为繁重的工作被摊销了。
Text‑Enhancer 实际应用:以最少努力获得更好的图像
通过结合 Tag Booster 和 Mood Enhancer,Illustrious 的 Text‑Enhancer 系统确保任何用户输入,无论多么简单,都能发展成用于图像生成的强大 prompt。这一切都在幕后完成——您可以开启这些增强器,输入几个词,并获得精美详细的 prompt 和令人惊艳的图像。
让我们通过一个假设的例子来看看端到端的效果:
- 用户输入: a lonely castle on a hill 只是一个简单的描述——富有感染力,但稀疏。用户没有指定风格、照明或周围细节。
- 经过 Tag Booster: a lonely castle on a hill, medieval fortress, stormy sky, dusk, high resolution, epic scale Tag Booster 识别了主题并添加了关键视觉标签:城堡被识别为中世纪堡垒,添加了可能的设置(黄昏阴云天空)以营造氛围,以及与我们戏剧性风景训练数据对齐的风格标签如"高分辨率,史诗级规模"。
- 经过 Mood Enhancer: "A lonely medieval castle perches atop a mist-shrouded hill beneath a stormy dusk sky. The ancient stone fortress is illuminated by the last rays of twilight, its silhouette standing in epic scale against the darkening valley below. Dramatic clouds roil overhead while wisps of fog cling to the ground, evoking a sense of mystery and grandeur."
Mood Enhancer 将标签编织成丰富的叙述。它保留了所有关键元素(城堡、山丘、阴云黄昏)并增强了它们:我们现在可以感受到氛围并在脑海中看到场景。
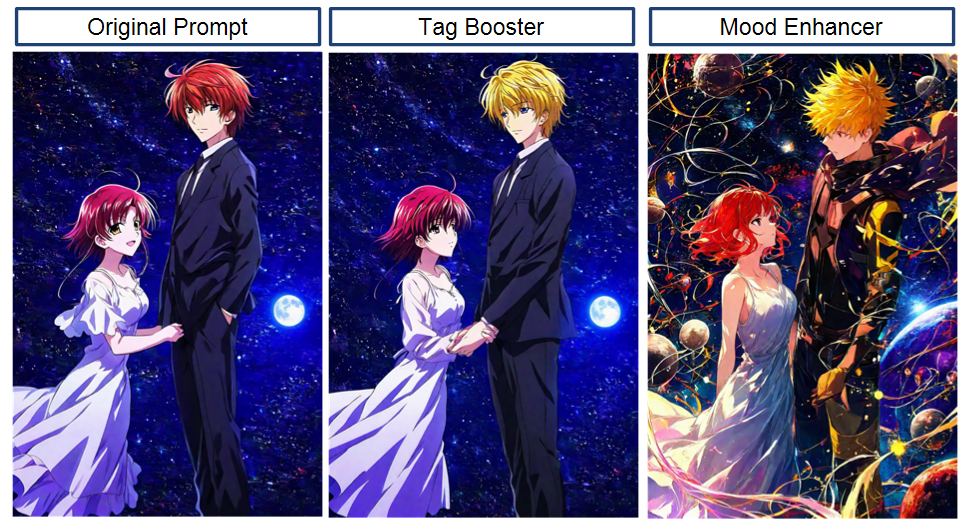
现在想象将最终增强的 prompt 输入 Illustrious XL。输出的差异是天壤之别。事实上,我们内部测试了这一点:
- 没有 Text‑Enhancer,prompt "a lonely castle on a hill" 产生了一个非常普通的城堡图像,天空平淡。
- 使用 Text‑Enhancer,生成的图像要戏剧性和详细得多——城堡有复杂的建筑,天空充满被日落照亮的阴郁云彩,整体构图匹配我们追求的 "雄伟氛围"。
结论
Illustrious Text‑Enhancer(Tag Booster + Mood Enhancer)代表了在自然人类输入和高质量图像生成所需的最佳 prompt 之间架起桥梁的重大飞跃。通过利用先进的 NLP 技术——从专门的 prompt 优化模型(TIPO)到成本高效的 LLM 管道——我们的系统实时处理 prompt 工程的繁重工作。这意味着艺术家和创作者可以专注于他们的创作愿景,而不会陷入找出关键词或描述符的完美组合的困扰中。
从技术角度来看,我们为这些组件如何相互补充感到自豪。Tag Booster 确保 prompt 涵盖所有关键视觉提示并与我们扩散模型的训练数据对齐,提高保真度。Mood Enhancer 通过注入富有想象力的细节和氛围进一步发展,产生讲述故事的输出。由于 KV 缓存等优化,我们在不引入延迟或过高计算成本的情况下实现了这些收益——对用户和平台来说都是双赢。
我们相信这将赋能 Illustrious 的新手和高级用户。新手可以用最少的输入获得出色的结果,专家在充实他们的想法时可以节省时间。这是让 AI 图像生成更直观、更符合您创作意图的又一步。
Text‑Enhancer 功能现在在 Illustrious 中已上线:试试看吧!从一个简单的想法开始,启用 Tag Booster 和 Mood Enhancer,看着您谦逊的 prompt 转变为杰作级的描述。您将获得一张不仅反映您想象的图像,而且其细节和质量水平可能会让您惊喜。
愉快的 prompting,一如既往,让我们知道您的反馈。我们很兴奋看到您用 Tag Booster 和 Mood Enhancer 增强您的想象力所创造的作品!