多模态理解与生成统一Token化框架|NitroFusion单步图像生成|Imagine360探索全景生成视频【AI周报】
多模态理解与生成统一Token化框架|NitroFusion单步图像生成|Imagine360探索全景生成视频【AI周报】

摘要
本周聚焦生成式AI:TokenFlow提供多模态生成框架;NitroFusion实现一步图像生成;Imagine360支持全景内容创作;HunyuanVideo引领多模态视频生成;Art-Free-Diffusion打破风格限制。详见正文。
目录
- TokenFlow:多模态理解与生成统一Token化框架
- NitroFusion:一步高保真扩散模型生成
- Imagine360:沉浸式360°全景视频生成框架
- HunyuanVideo:大规模多模态视频生成系统
- OneShotOneTalk:单张图像生成全身会话化身
- Open-Sora-Plan:开源大型视频生成模型计划
- Art-Free-Diffusion:突破艺术风格限制的生成模型
TokenFlow:多模态理解与生成统一Token化框架
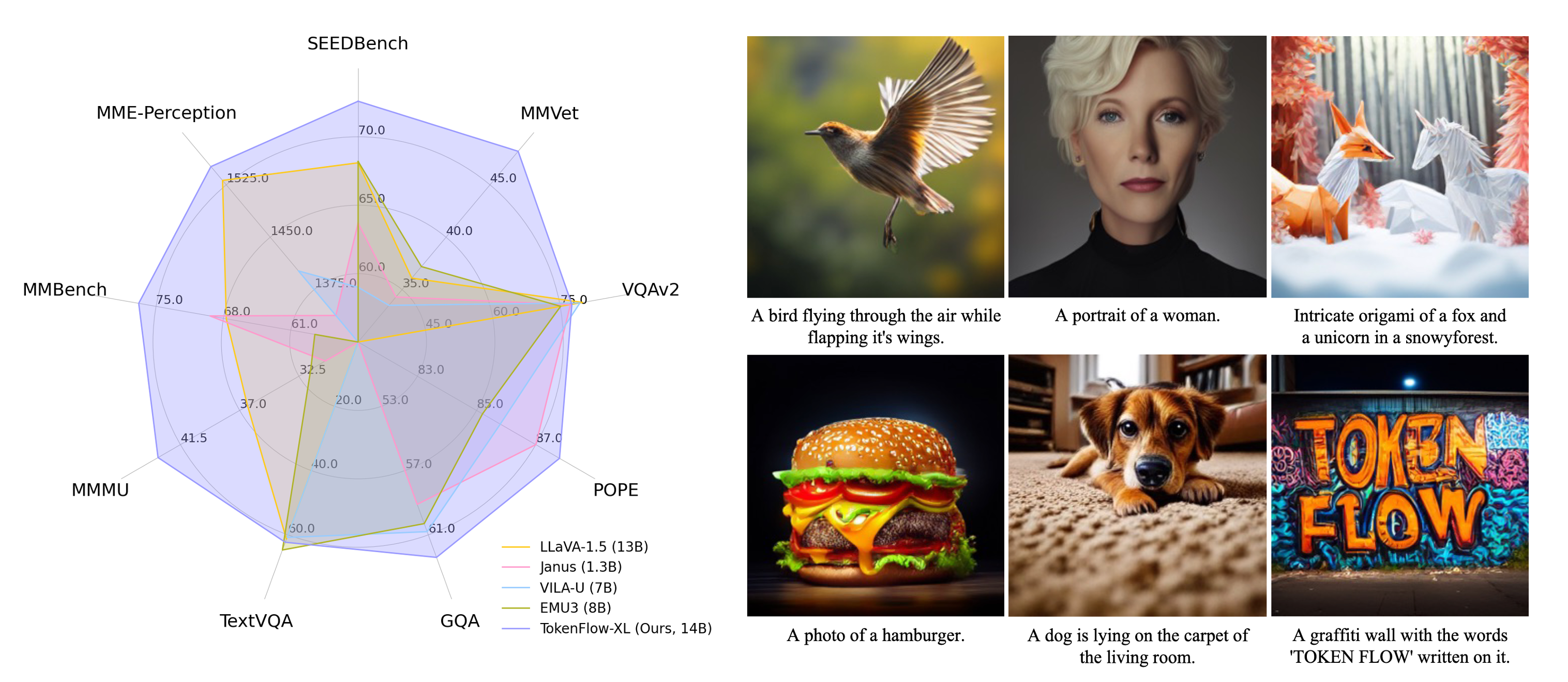
概要:TokenFlow 是一种创新的视觉 Token 化框架,旨在统一多模态理解与生成任务。通过引入双编码结构,分别处理语义与像素级特征,TokenFlow 实现了高质量的图像生成和精准的多模态理解。该设计有效解决了传统单编码方法中的粒度权衡问题,支持局部区域编辑、特征增强以及多任务学习。实验结果显示,其在 LLaVA 和 GenEval 等基准上的性能领先,生成图像的 FID 分数达到 0.63。
标签:#多模态AI #图像生成 #Diffusion模型 #Token化
NitroFusion:一步高保真Diffusion模型生成
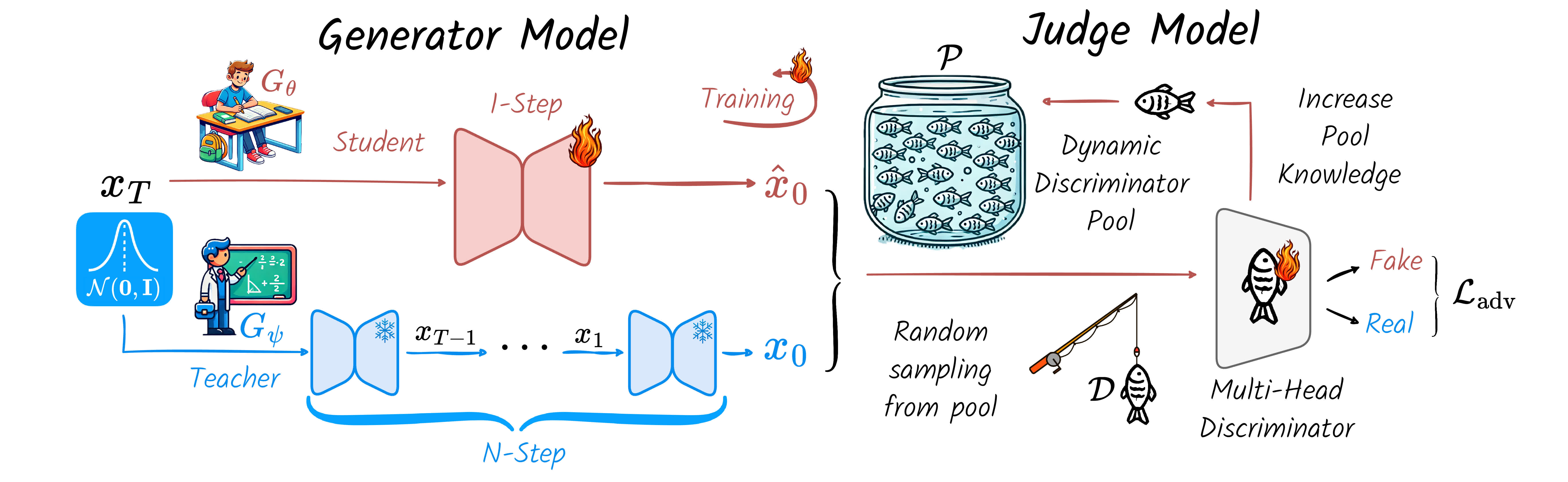
概要:NitroFusion 是由 萨利大学 提出的一种单步文本到图像Diffusion生成框架,采用动态对抗训练策略解决传统一步Diffusion模型的质量下降问题。框架通过多头判别器实现细粒度质量控制,并结合全局-局部判别机制,兼顾生成细节与整体一致性。此外,NitroFusion 支持在 1-4 步之间动态选择降噪过程,提供质量与生成速度的灵活权衡,适用于多样化的生成场景。
标签:#Diffusion模型 #一步生成 #对抗训练 #高保真生成
Imagine360:沉浸式360°全景视频生成框架
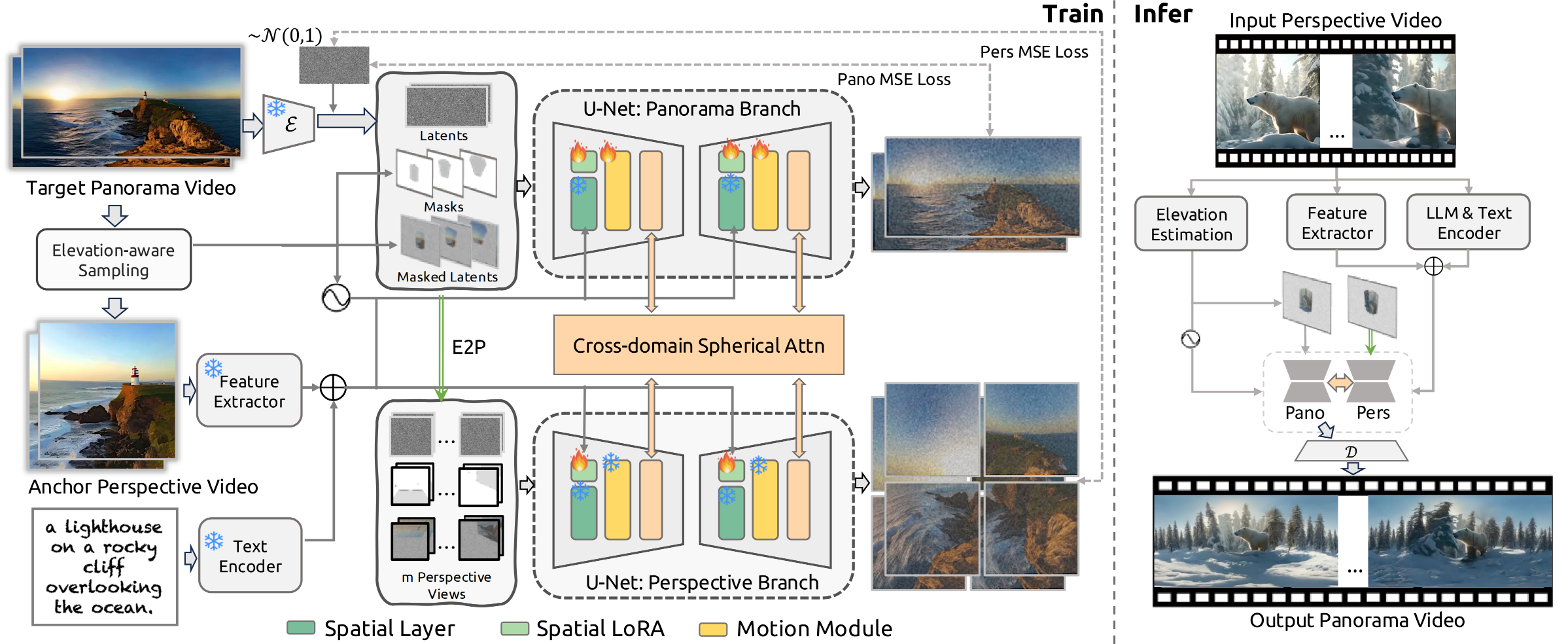
概要:Imagine360 是 CUHK、上交、S-Lab 和 上海AI实验室 一同一种从透视视频生成沉浸式 360° 全景视频的框架,通过双分支网络结合全景视频去噪模块实现高质量生成。框架采用抗极点遮罩(antipodal mask)优化长距离运动依赖,并引入空间 LoRA 层增强运动与视觉一致性。实验表明,Imagine360 在运动连贯性和图像质量上显著优于现有方法,适用于个性化 VR 内容创作和全景视频生成。
标签:#全景视频 #视频生成 #运动一致性 #VR设计 #LoRA
HunyuanVideo:大规模多模态视频生成系统
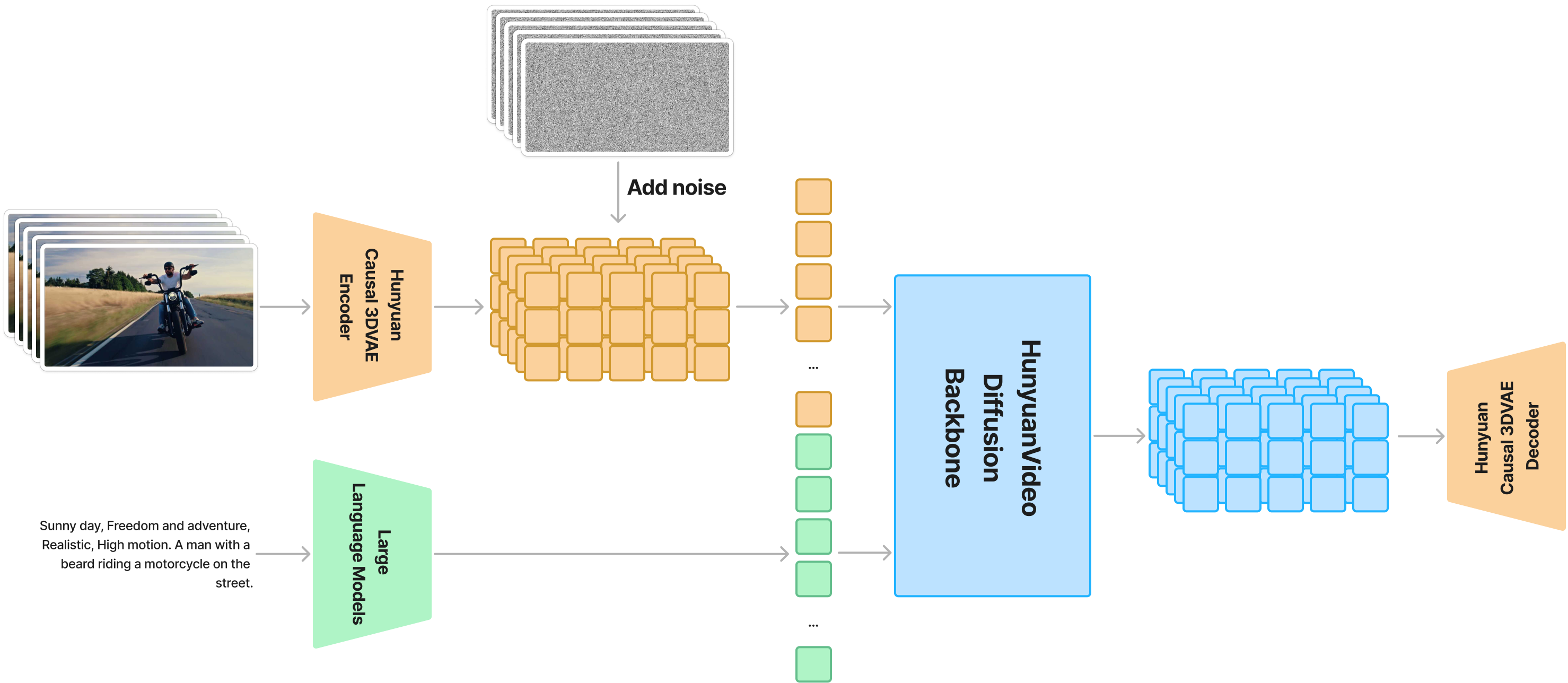
概要:HunyuanVideo是 腾讯 推出的一款开放源代码的视频生成基础模型,支持文本、图像或音频输入生成高质量视频。系统采用 3D VAE 和多模态大模型架构,通过时间-空间压缩策略大幅提升生成效率。其特点包括文本-视频对齐优化、多模态信息融合及生成稳定性,在视觉质量和动作多样性上超越现有闭源基准模型。
标签:#视频生成 #多模态AI #腾讯Hunyuan #3D VAE #文本-视频对齐
OneShotOneTalk:单张图像生成全身会话化身
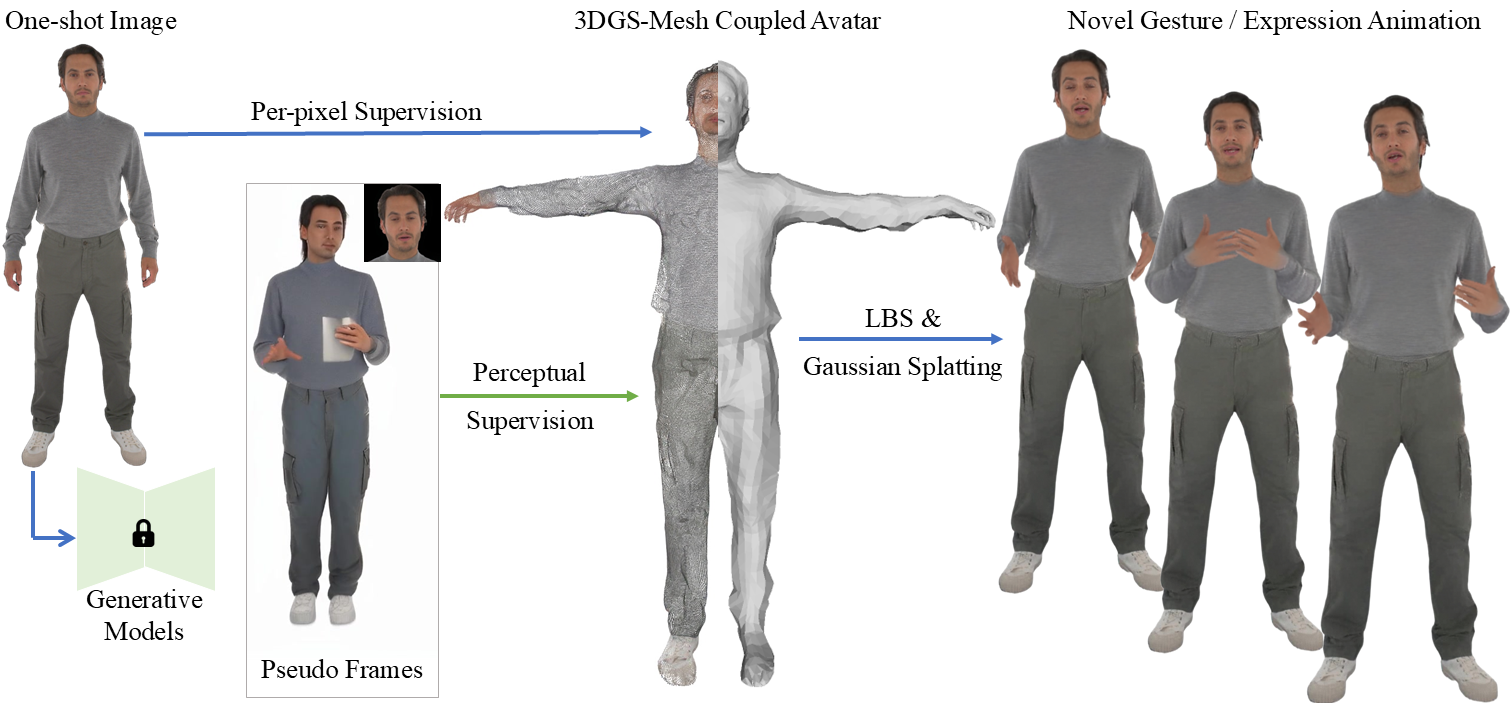
概要:OneShotOneTalk 是 中科大 和 港理 一种通过单张图像生成动态全身会话化身的方法。框架利用基于姿势引导的图像到视频Diffusion模型,生成伪标签视频,并通过3D网格与姿态混合表征减少伪标签中的噪声与不一致。该方法显著提升了对新表情与动作的泛化能力,支持高保真度的动画生成,在虚拟形象和交互领域有重要应用。
标签:#数字人生成 #会话动画 #图像到视频 #中科大 #3D动作
Open-Sora-Plan:开源大型视频生成模型计划

概要:Open-Sora-Plan 是由北大 Yuan Group 领导的开源项目,致力于复现 OpenAI 的 Sora 模型,并拓展其应用能力。通过引入 3D 注意力机制和波浪驱动潜能 VAE(WF-VAE),框架支持从图像到视频的转换,并优化多模态输入对视频生成的控制。系统还通过分布式训练和新型数据策略,提升生成视频的时间一致性与视觉质量。
标签:#视频生成 #SoraI #分布式训练 #北京大学 #VAE
Art-Free-Diffusion:突破艺术风格限制的生成模型

概要:Art-Free-Diffusion 是 上科大、MIT 和 东北大学 一种避免依赖艺术数据训练的生成模型,专注于生成与自然内容高度一致的照片级图像。通过引入 "Art Adapter",该框架可在仅使用少量风格样本的情况下,实现高效的风格转移。其创新点在于采用基于文本编码的Latent Diffusion模型,避免传统方法对艺术风格的过度记忆,提供更高的伦理合规性和创意灵活性。
标签:#图像生成 #风格转移 #艺术适配器 #Diffusion模型
参考链接
- TokenFlow 项目主页
- TokenFlow GitHub
- TokenFlow 论文
- NitroFusion 项目主页
- NitroFusion Hugging Face
- NitroFusion 论文
- Imagine360 项目主页
- Imagine360 GitHub
- Imagine360 论文
- HunyuanVideo 项目主页
- HunyuanVideo GitHub
- HunyuanVideo 论文
- OneShotOneTalk 项目主页
- OneShotOneTalk 论文
- Open-Sora-Plan GitHub
- Open-Sora-Plan 论文
- Art-Free-Diffusion 项目主页
- Art-Free-Diffusion GitHub
- Art-Free-Diffusion 论文