【论文精读】AlexNet:ImageNet Classification with Deep Convolutional Neural Networks
大约 6 分钟
【论文精读】AlexNet:ImageNet Classification with Deep Convolutional Neural Networks

摘要
AlexNet 是深度学习领域的奠基之作,在 ImageNet 分类竞赛中以创新技术(如 ReLU、Dropout、重叠池化、多 GPU 并行)显著降低分类错误率。本文剖析其深度卷积神经网络设计与实验结果,探讨对深度学习发展的启发与影响。
目录
背景与研究目标
数据集与任务背景
论文选用 ImageNet 数据集作为实验基准,其 ILSVRC 子集包含 120 万张训练图像、5 万张验证图像和 10 万张测试图像,共 1000 个类别。这些规模和复杂度为深度学习的应用提供了理想的测试平台,同时对传统图像分类算法提出了挑战。
主要参考文献
AlexNet 的设计借鉴了以下研究工作:
- ReLU 的奠基研究:Nair 和 Hinton(2010)在《Rectified Linear Units Improve Restricted Boltzmann Machines》中,首次提出 ReLU 能显著提升受限玻尔兹曼机(RBM)的训练效果,启发了 AlexNet 的激活函数设计。
- VGG 的延续性工作:Simonyan 和 Zisserman(2014)提出的 VGG 网络表明,通过深度扩展可以进一步提升卷积网络的特征提取能力。
方法与创新点
网络架构设计
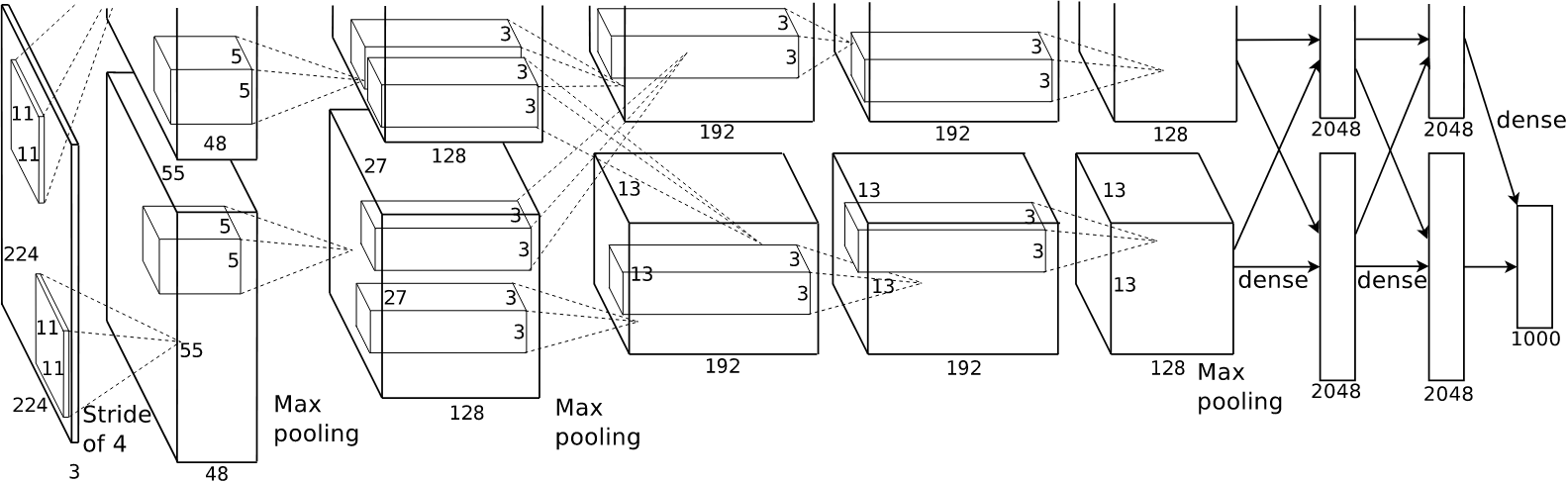
AlexNet 采用一个由 8 层神经网络(5 层卷积层和 3 层全连接层)组成的深度 CNN 架构。架构中的关键设计包括:
- 大卷积核:第一层卷积层采用 11×11 的大卷积核以捕获更多上下文信息,后续卷积核逐步减小至 5×5 和 3×3。
- 局部连接:采用部分连接策略减少计算负担,提高训练效率。
ReLU 激活函数与局部响应归一化(LRN)
- ReLU 的引入:传统激活函数(如 Sigmoid 和 Tanh)存在梯度消失问题,而 ReLU ($f(x) = \max(0, x)$) 通过非饱和性操作有效缓解了这一问题,大幅加快了训练速度。
- LRN 的作用:通过模拟生物神经元间的竞争机制,LRN 对局部响应进行归一化以增强泛化能力。ReLU 与 LRN 的结合,被证明在 ImageNet 数据集上显著提高了模型的性能。
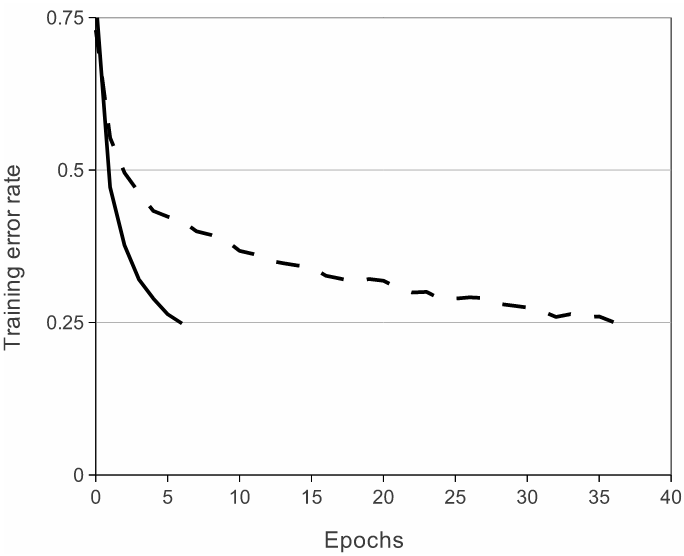
多 GPU 并行训练
- 设计原理:为克服单 GPU 内存限制,将网络切分到两块 GPU 上运行,分别处理一半的卷积核。只有在第三层卷积时,两个 GPU 的信息被整合。
- 技术意义:这种策略减少了计算资源瓶颈,并启发了后续分布式深度学习的研究。
重叠池化
- 创新点:传统池化通常采用不重叠的池化窗口,而重叠池化通过设置 3×3 的池化窗口和步长 2,在特征提取过程中减少信息丢失。
- 意义:这一方法在边缘和纹理提取上表现优异,提高了模型的鲁棒性。
Dropout 正则化与数据增强
- Dropout 正则化:在全连接层随机屏蔽 50% 神经元的输出,防止特征协同适应现象,显著减少过拟合。
- 这种方法在训练期间会动态生成不同的神经网络结构,而测试阶段则使用所有神经元,并将它们的输出乘以 0.5,以近似模拟大量网络的预测平均值。
- 数据增强:
- 随机裁剪:从 256×256 的图像随机生成 224×224 的训练样本,同时生成水平翻转版本,从而增加训练数据的多样性。
- PCA 颜色扰动:基于主成分分析 (PCA),对 RGB 通道添加随机扰动,使训练图像的颜色分布更加多样化。该方法有效提升了模型对光照和颜色变化的鲁棒性。
实验与结果分析
实验设置与数据处理
- 硬件环境:使用两块 NVIDIA GTX 580 GPU(内存仅 3GB)。
- 数据预处理:
- 随机裁剪和 PCA 颜色扰动扩展了数据集。
- 数据分为训练集、验证集和测试集,保证了实验结果的科学性。
关键实验结果与图表解读
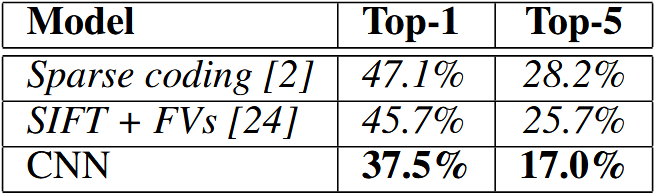
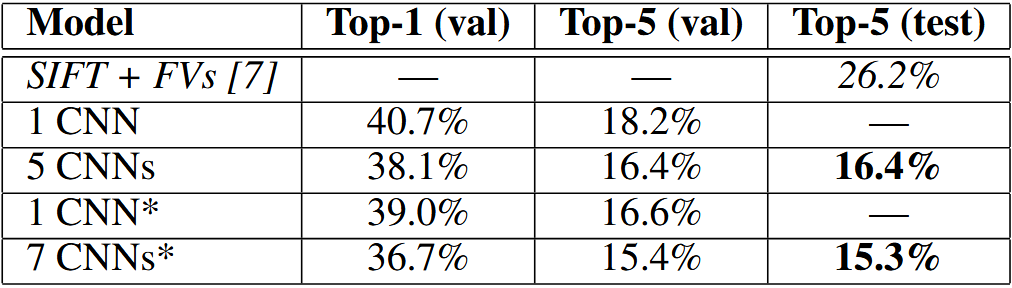
- 性能指标:
- ILSVRC-2010:Top-1 错误率从 47.1% 降至 37.5%。
- ILSVRC-2012:Top-5 错误率降至 15.3%,优于第二名的 26.2%。


- 特征可视化:
- 第一层卷积核学到了颜色和边缘等低层次特征。
- 深层卷积核捕捉了高层次语义特征。
模型启发与方法延伸
技术启发
- ReLU 的成功:激发了 Leaky ReLU、PReLU 和 GELU 等改进版本的研究。
- 正则化方法:Dropout 推动了 Batch Normalization 和 Layer Normalization 等技术的发展。
工程实践
- 分布式训练:AlexNet 的多 GPU 并行方法为后续大规模分布式训练提供了技术启发。
- 数据增强:论文的随机裁剪与颜色扰动方法至今仍是深度学习领域的重要工具。
结论与未来展望
AlexNet 在 ImageNet 数据集上的突破,标志着深度学习在计算机视觉领域的全面崛起。论文的创新技术(如 ReLU、Dropout、重叠池化、多 GPU 并行等)奠定了深度神经网络设计的基础,但仍有改进空间:
- 理论解释不足:ReLU 和 Dropout 的理论分析有待进一步完善。
- 多 GPU 方法的扩展性有限:现有分布式训练技术已逐渐取代其设计。
未来研究可通过优化训练方法、改进数据增强策略,推动深度学习在更大规模任务上的应用。