Paper2Poster论文到海报自动化|OmniConsistency统一风格化|Jodi融合理解与生成的视觉模型【AI周报】
Paper2Poster论文到海报自动化|OmniConsistency统一风格化|Jodi融合理解与生成的视觉模型【AI周报】

摘要
本周亮点:Paper2Poster推出论文转海报自动化工具;OmniConsistency发布风格一致性学习框架;Jodi统一视觉生成与理解;FlowRL优化文本到图像生成流程;HunyuanVideo-Avatar实现音频驱动数字人。
目录
- Paper2Poster:全自动多模态论文转学术海报系统
- OmniConsistency:在扩散Transformer上的风格无关的一致性学习
- FlowRL:基于强化学习的文本到图像生成流程优化框架
- Jodi:统一视觉生成与理解的扩散模型框架
- Frame In-N-Out:突破边界的可控图像到视频生成框架
- HunyuanVideo-Avatar:高保真音频驱动多角色数字人生成模型
Paper2Poster:全自动多模态论文转学术海报系统
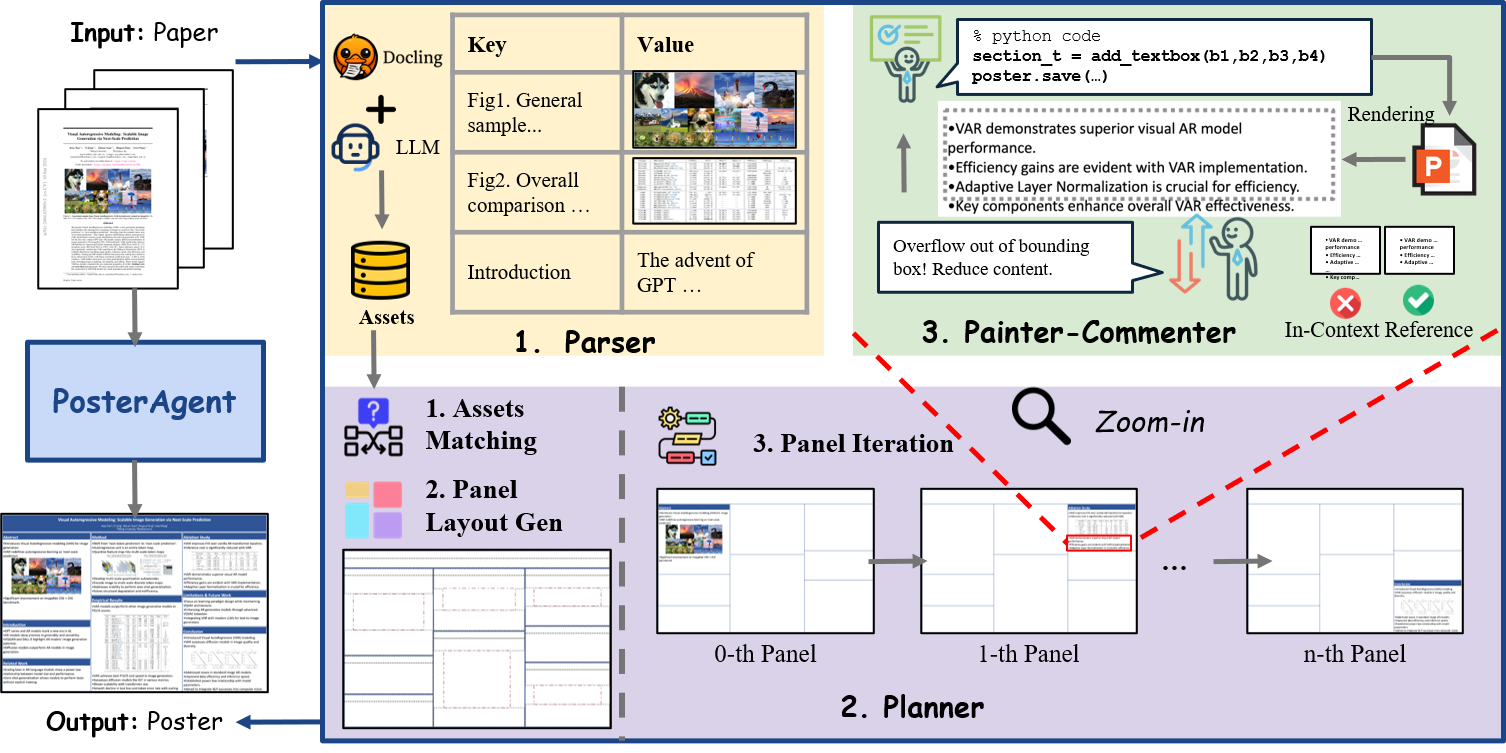
概要:Paper2Poster 是由滑铁卢大学联合牛津大学与新加坡国立大学提出的多模态论文海报生成系统,设计了多智能体框架 PosterAgent,融合结构化解析、自动布局与视觉语言模型优化等能力。系统通过“先提取结构再渲染优化”的流程,可自动将完整学术论文转换为格式规范、内容清晰的 .pptx 学术海报。模型支持全面自动化生成,并引入 PaperQuiz 等创新评估方式,大幅提升效率与表达准确性。项目已全开源,推动科研传播自动化与标准化。
标签:#多模态生成 #论文可视化 #学术传播 #视觉语言模型 #多智能体系统
OmniConsistency:在扩散Transformer上的风格无关的一致性学习

概要:OmniConsistency 是由 新加坡国立大学 Show Lab 提出的一种风格无关的一致性学习插件,旨在提升图像风格迁移中的结构和语义一致性。该方法基于 Diffusion Transformer 架构,采用两阶段训练策略:首先独立训练风格 LoRA 模型构建 LoRA Bank,然后将预训练的风格 LoRA 模块附加到扩散模型上,训练一致性模块以保持图像的结构和语义一致性。OmniConsistency 设计为即插即用的模块,兼容任意风格的 LoRA 模型,显著提升了图像风格迁移的视觉一致性和美学质量,性能可与商业模型 GPT-4o 相媲美。项目已在 Hugging Face 开源,提供模型权重和数据集,促进图像风格迁移研究的开放性与可复现性。
标签:#图像风格迁移 #一致性学习 #扩散模型 #LoRA #视觉一致性
FlowRL:基于强化学习的文本到图像生成流程优化框架

概要:FlowRL 是由 以色列理工学院 和 NVIDIA 研究人员提出的文本到图像生成流程优化框架,旨在通过强化学习方法自动设计高质量的生成流程。该框架引入了奖励模型预测图像质量分数,避免了在训练过程中生成大量图像的高昂计算成本。FlowRL 采用两阶段训练策略:首先训练流程词汇表,然后通过 GRPO(Generalized Reinforcement Policy Optimization)优化策略,引导模型探索性能更优的流程空间。此外,框架还结合了无分类器引导的增强技术,进一步提升生成图像的质量。实验结果表明,FlowRL 能够生成多样性更高、质量更优的图像,优于现有的基线方法。
标签:#文本到图像生成 #强化学习 #流程优化 #图像质量预测 #无分类器引导
Jodi:统一视觉生成与理解的扩散模型框架

概要:Jodi 是由 中国科学院计算技术研究所 提出的一种统一视觉生成与理解的扩散模型框架。该模型通过联合建模图像域和多个标签域,实现了图像生成与理解任务的统一处理。Jodi 基于线性扩散 Transformer 和角色切换机制,支持联合生成、可控生成和图像感知三种任务。为支持多视觉域的联合建模,研究团队构建了包含 20 万张高质量图像和 7 个视觉域标签的 Joint-1.6M 数据集。实验结果表明,Jodi 在生成和理解任务中均表现出色,展现出强大的可扩展性和跨领域一致性。项目已开源,提供训练代码和模型权重,促进多模态研究的开放性与可复现性。
标签:#多模态模型 #视觉生成 #图像理解 #扩散模型 #联合建模
Frame In-N-Out:突破边界的可控图像到视频生成框架
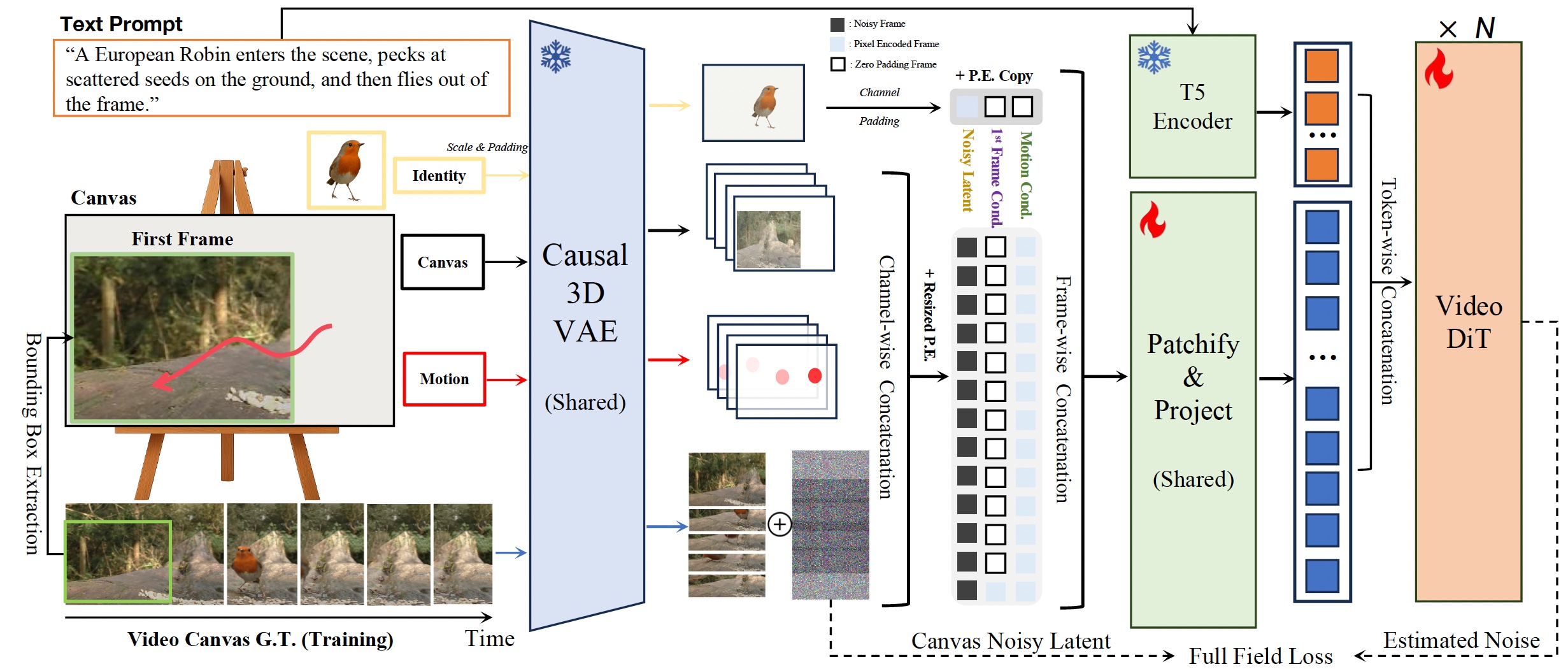
概要:Frame In-N-Out 是由 弗吉尼亚大学计算机视觉实验室 与 Adobe Research 联合提出的图像到视频生成框架,首次引入电影制作中常用的“入画(Frame In)”与“出画(Frame Out)”概念,实现了物体在视频中自然进出画面的可控生成。该框架采用扩展画布(Unbounded Canvas)设计,结合用户指定的运动轨迹和身份参考图像,通过视频扩散变换器(Video Diffusion Transformer)生成具有时间连贯性和细节丰富的视频内容。研究团队还构建了专门的数据集和评估协议,支持多种控制信号的联合建模,显著提升了生成质量和控制精度,为电影制作和创意内容创作提供了新的可能性。
标签:#图像到视频生成 #可控生成 #扩散模型 #无边界画布 #身份参考
HunyuanVideo-Avatar:高保真音频驱动多角色数字人生成模型
概要:HunyuanVideo-Avatar 是由 腾讯混元 与 腾讯音乐天琴实验室 MuseV 联合开发的音频驱动数字人视频生成模型,基于多模态扩散变换器(MM-DiT)架构,实现高保真、情绪可控的多角色视频生成。该模型引入角色图像注入模块解决传统加法式条件方法的训练推理不匹配问题,确保角色一致性和动态表现。音频情绪模块(AEM)从情绪参考图像提取情绪特征,实现细粒度情绪风格控制。面部感知音频适配器(FAA)通过潜在空间面部掩码和交叉注意力机制,支持多角色场景下的独立音频驱动。系统支持照片级写实、卡通、3D 渲染等多种风格虚拟形象,涵盖肖像至全身多视角生成,可根据音频自动控制面部表情、唇形同步及全身动作,在视频质量、运动动态、角色一致性等指标上显著优于现有方法。
标签:#语音驱动 #数字人 #多模态生成 #扩散模型 #情绪控制 #多角色动画