VibeVoice长音频生成 | LongCat-Flash高效MoE | InternVL3.5多模态新SOTA【HF周报】
VibeVoice长音频生成 | LongCat-Flash高效MoE | InternVL3.5多模态新SOTA【HF周报】
摘要
本周亮点:微软发布专为长篇对话设计的TTS模型VibeVoice;美团推出5600亿参数的创新MoE语言模型LongCat-Flash;OpenGVLab的InternVL3.5在多模态基准上再创SOTA。此外,还有来自面壁智能、Wan-AI、StepFun和腾讯混元等机构的最新模型。详见正文,相关参考链接请见文末。
目录
- VibeVoice-1.5B:微软开源的长篇多说话人对话音频生成框架
- LongCat-Flash-Chat:美团推出的5600亿参数高效MoE语言模型
- InternVL3_5-241B-A28B:OpenGVLab发布的新一代开源多模态SOTA模型
- MiniCPM-V-4_5:面壁智能推出的可在手机端运行的GPT-4o级多模态模型
- Wan2.2-S2V-14B:Wan-AI发布的音频驱动电影级视频生成模型
- Step-Audio-2-mini:StepFun推出的端到端音频理解与语音对话模型
- HunyuanVideo-Foley:腾讯混元开源的专业级视频音效生成模型
VibeVoice-1.5B:微软开源的长篇多说话人对话音频生成框架

概要:微软 发布了 VibeVoice-1.5B,一个专为生成富有表现力的长篇、多说话人对话音频(如播客)而设计的开源模型。它利用7.5Hz的超低帧率连续语音分词器,在保持音频保真度的同时大幅提升了处理长序列的计算效率,可合成长达90分钟、支持多达4个不同说话人的语音。
标签:#Microsoft #VibeVoice #文本转语音 #长音频 #多说话人
LongCat-Flash-Chat:美团推出的5600亿参数高效MoE语言模型
概要:美团-LongCat发布了LongCat-Flash-Chat,一个拥有5600亿总参数的MoE语言模型。该模型采用动态计算机制,根据上下文需求激活186亿至313亿参数,平均激活约270亿,优化了计算效率和性能。其架构设计实现了高吞吐量和低延迟的推理。
标签:#美团 #LongCat #MoE #大语言模型 #动态计算
InternVL3_5-241B-A28B:OpenGVLab发布的新一代开源多模态SOTA模型

概要:OpenGVLab 推出了 InternVL3.5系列,这是一个在多功能性、推理能力和推理效率方面取得显著进步的开源多模态模型家族。其关键创新是级联强化学习(Cascade RL)框架和视觉分辨率路由器(ViR),在提升推理性能的同时实现了4.05倍的推理加速,并在多个基准测试中取得了SOTA结果。
标签:#OpenGVLab #InternVL #多模态 #级联强化学习 #SOTA
MiniCPM-V-4_5:面壁智能推出的可在手机端运行的GPT-4o级多模态模型
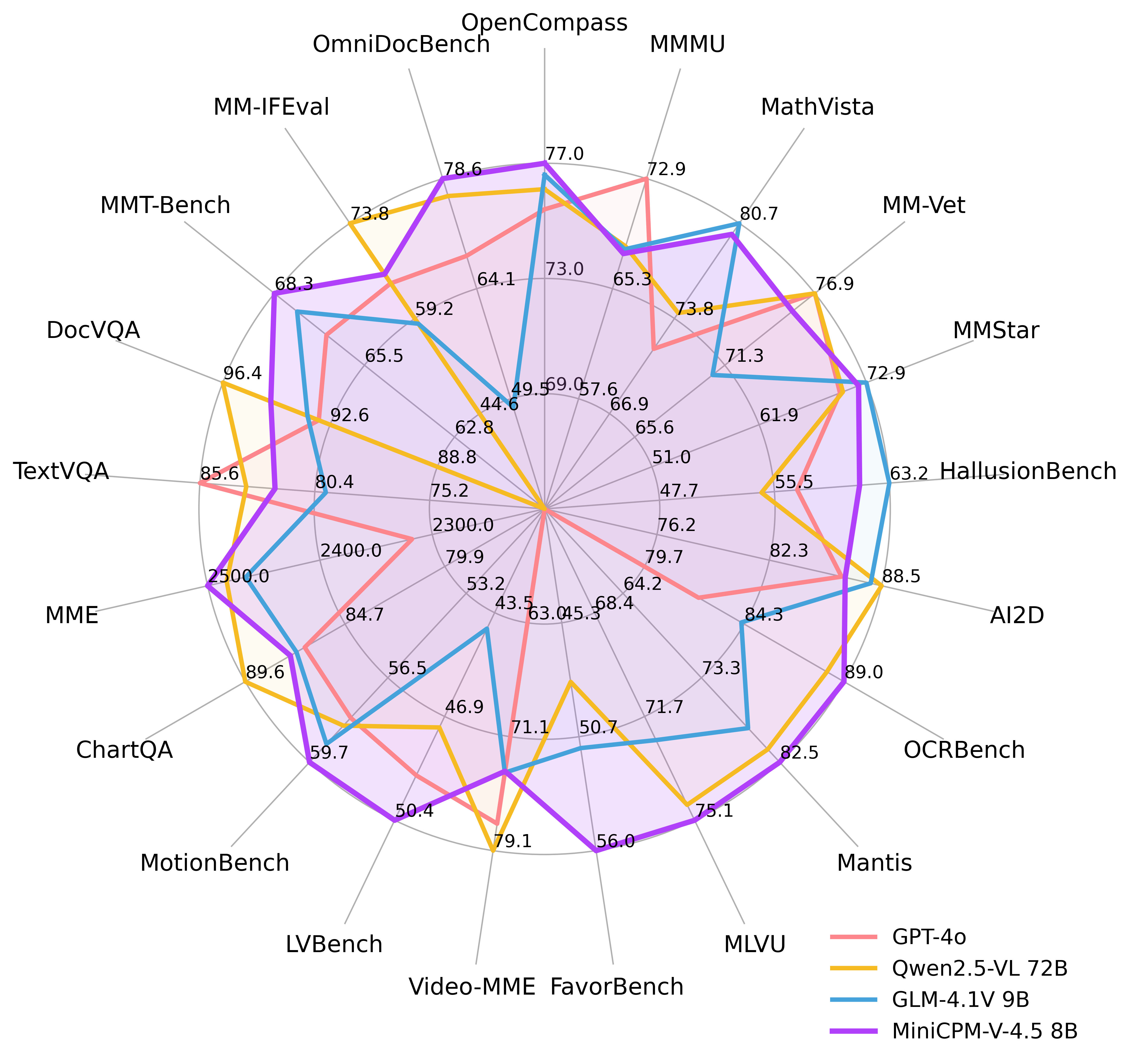
概要:面壁智能(OpenBNB)发布了MiniCPM-V 4.5,这是MiniCPM-V系列的最新模型。该模型基于Qwen3-8B和SigLIP2-400M构建,总参数为8B,在OpenCompass上取得了优异成绩,支持高效的高帧率和长视频理解,并提供可控的快速/深度思维混合模式。
标签:#面壁智能 #MiniCPM #端侧模型 #视频理解 #混合思维
Wan2.2-S2V-14B:Wan-AI发布的音频驱动电影级视频生成模型
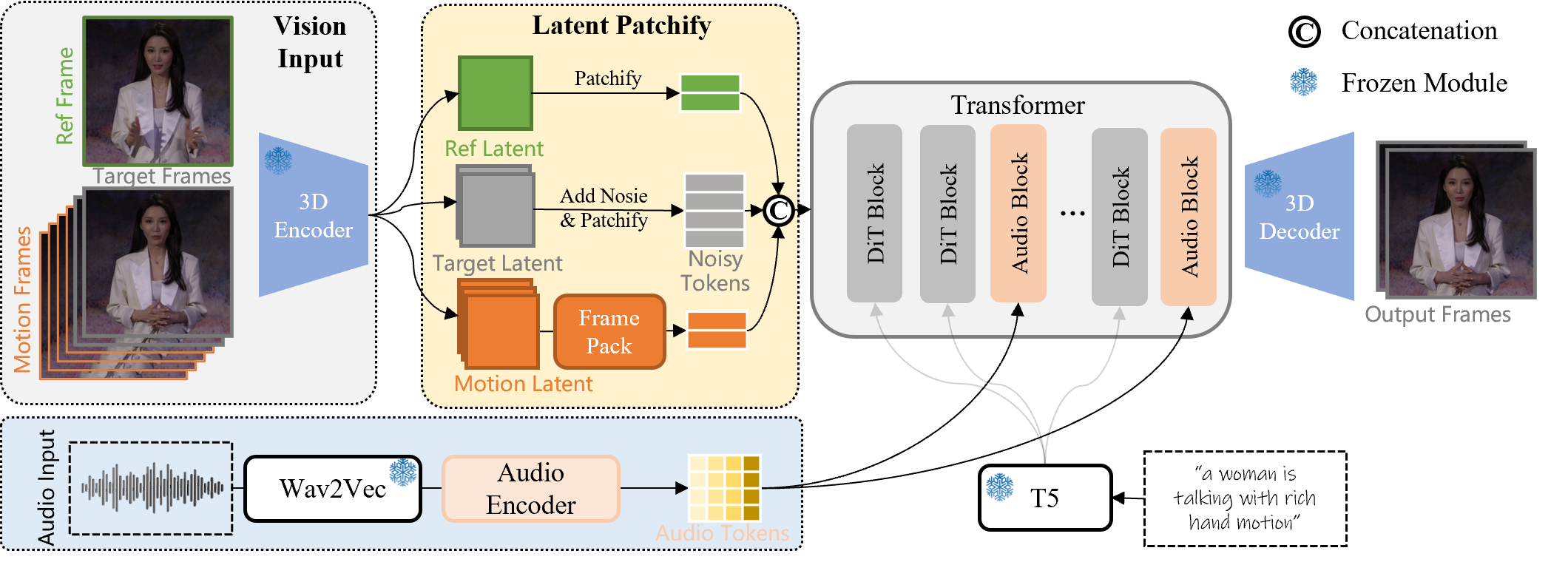
概要:Wan-AI 发布了 Wan2.2-S2V-14B,一个音频驱动的电影级视频生成模型。它引入了混合专家(MoE)架构,并支持通过音频输入结合参考图像和可选的文本提示来生成视频,甚至可以由姿态视频驱动,实现与音频输入同步的特定姿态序列。
标签:#Wan-AI #WanS2V #音频驱动视频 #视频生成 #MoE架构
Step-Audio-2-mini:StepFun推出的端到端音频理解与语音对话模型

概要**:StepFun** 发布了Step-Audio 2-mini,一个专为工业级音频理解和语音对话设计的端到端多模态大语言模型。它在ASR和音频理解方面表现出色,能实现自然智能的交互,并利用工具调用和多模态RAG访问真实世界知识,减少幻觉。
标签:#StepFun #StepAudio #音频理解 #语音对话 #多模态RAG
HunyuanVideo-Foley:腾讯混元开源的专业级视频音效生成模型

概要:腾讯混元 开源了HunyuanVideo-Foley,一个专为视频内容创作者设计的端到端视频音效生成模型。它能生成与复杂视频场景同步且语义对齐的高质量音频,智能平衡视觉和文本信息,并输出48kHz的高保真音频,在多个评测基准上达到SOTA水平。
标签:#腾讯混元 #HunyuanVideoFoley #视频音效 #Foley #多场景同步