FramePack压缩加速视频生成 | Step1X-Edit开源高质量图像编辑 | DreamID高保真换脸【AI周报】
FramePack压缩加速视频生成 | Step1X-Edit开源高质量图像编辑 | DreamID高保真换脸【AI周报】

摘要
本周亮点:FramePack提出上下文压缩方法以提升视频生成效率;Step1X-Edit开源图像编辑框架,性能接近闭源模型;DescribeAnything实现精细的局部图像视频描述;DreamID基于扩散模型实现高保真换脸。其余详见正文。
目录
- FramePack:提升视频生成效率的上下文压缩框架
- Step1X-Edit:开源图像编辑框架,媲美 GPT-4o 与 Gemini2 Flash
- Describe Anything:局部区域的精细图像与视频描述模型
- DreamID:基于扩散模型的高保真快速换脸方法
- DreamO:多条件图像定制统一框架
- StyleMe3D:多编码器驱动的3D风格迁移框架,提升艺术风格一致性
FramePack:提升视频生成效率的上下文压缩框架
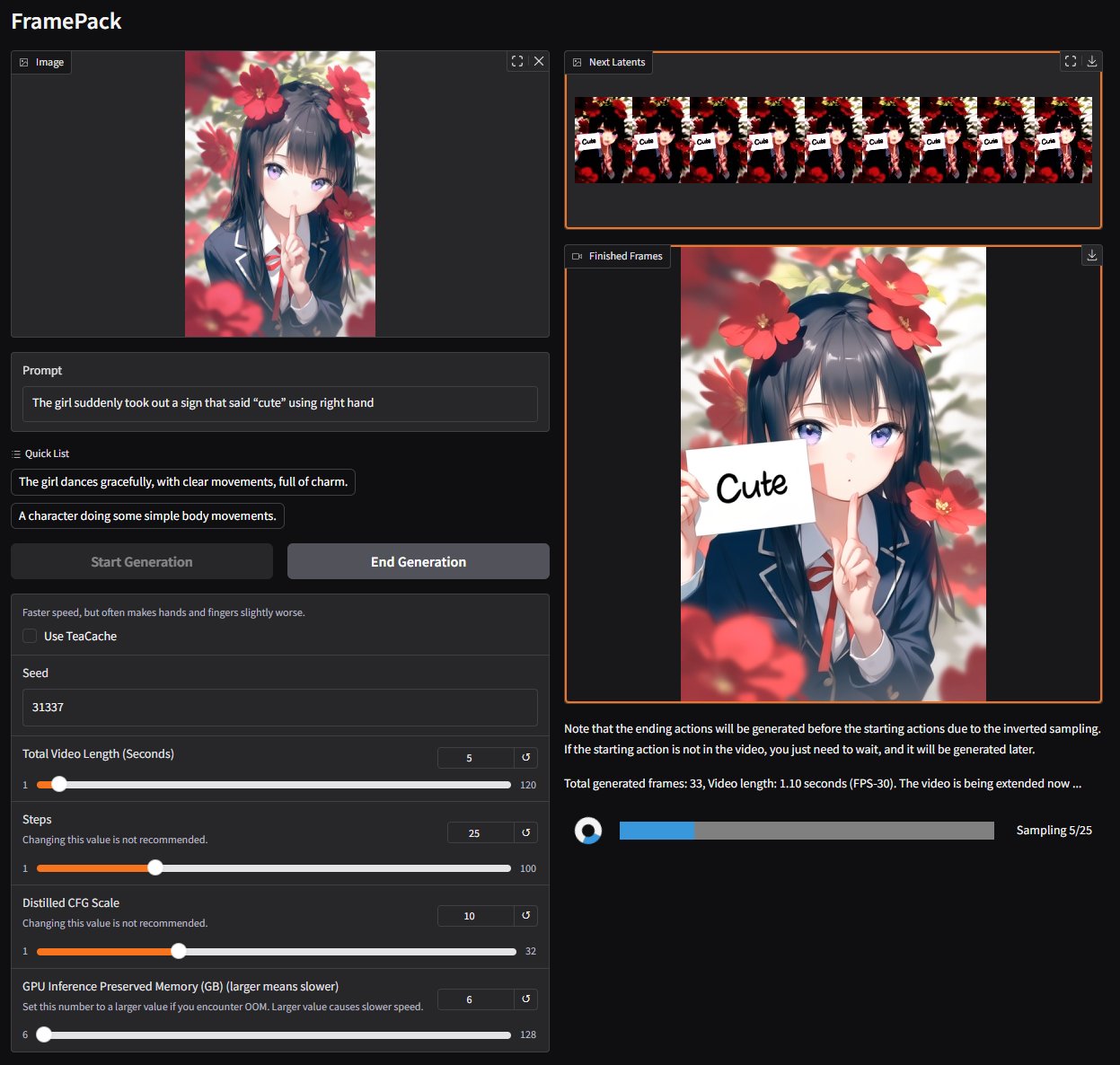
概要:FramePack 是由 张吕敏 提出的创新视频生成框架,旨在解决长序列视频生成中的计算瓶颈问题。该方法通过对输入帧进行压缩,使得 Transformer 的上下文长度固定,从而在不增加计算负担的情况下处理大量帧。FramePack 能够在仅使用 6GB GPU 内存的情况下,以每秒 30 帧的速度生成视频,即使在笔记本电脑上也能实现高效的视频扩散生成。
标签:#视频生成 #上下文压缩 #Transformer #高效计算 #视频扩散
Step1X-Edit:开源图像编辑框架,媲美 GPT-4o 与 Gemini2 Flash

概要:Step1X-Edit 是由 阶跃星辰 发布的开源图像编辑模型,旨在缩小与闭源模型(如 GPT-4o、Gemini2 Flash)之间的性能差距。该框架结合多模态大语言模型(Multimodal LLM)处理参考图像与用户编辑指令,提取潜在嵌入(latent embedding),并通过扩散图像解码器生成目标图像。训练过程中,团队构建了高质量的数据生成流程,确保数据多样性与代表性。评估结果显示,Step1X-Edit 在新提出的 GEdit-Bench 基准上显著优于现有开源模型,性能接近领先的闭源模型,推动了图像编辑领域的发展。
标签:#图像编辑 #多模态大模型 #扩散模型 #开源框架 #高质量数据生成
Describe Anything:局部区域的精细图像与视频描述模型
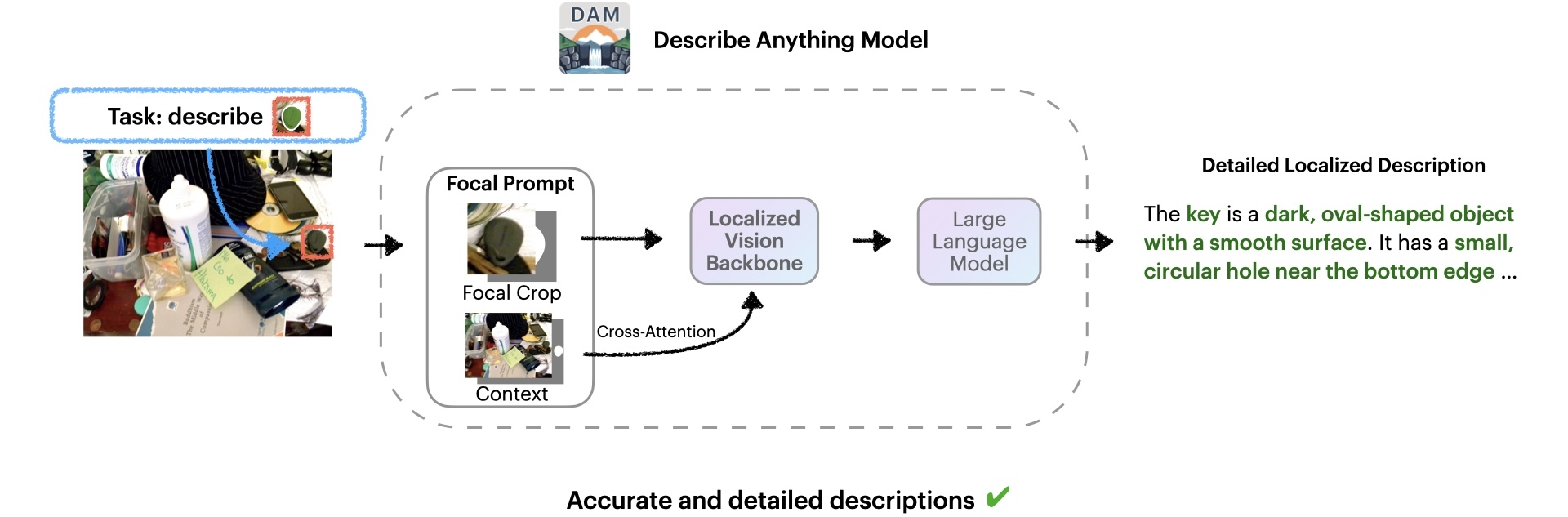
概要:Describe Anything Model (DAM) 是由 NVIDIA 与 UC Berkeley 等机构联合开发的多模态大模型,专注于图像和视频中指定区域的精细化描述。用户可通过点击、框选、涂鸦或掩码等方式指定区域,DAM 结合“Focal Prompt”机制与局部视觉骨干网络,生成包含纹理、颜色、形状等细节的丰富描述。该模型支持图像与视频的区域描述,视频仅需在一帧上标注目标区域,DAM 即可追踪并描述其在时序中的变化。此外,DAM 提供指令控制的描述风格调整和零样本区域问答能力,适用于数据标注、辅助分析等多种场景。
标签:#局部描述 #图像视频理解 #多模态模型 #区域问答 #视觉语言模型
DreamID:基于扩散模型的高保真快速换脸方法

概要:DreamID 是由 字节跳动 智能创作团队 提出的一种基于扩散模型的高保真换脸方法。该方法引入了显式的三元组身份组(Triplet ID Group)监督机制,显著提升了身份相似性和属性保留能力。通过采用加速扩散模型 SD Turbo,DreamID 将推理步骤减少至单次迭代,实现了高效的像素级端到端训练。其模型架构包括 SwapNet、FaceNet 和 ID Adapter,能够在复杂光照、大角度和遮挡等挑战场景下,生成高质量的 512×512 分辨率换脸图像,推理时间仅需 0.6 秒。
标签:#扩散模型 #换脸 #身份保留 #高保真 #快速推理
DreamO:多条件图像定制统一框架
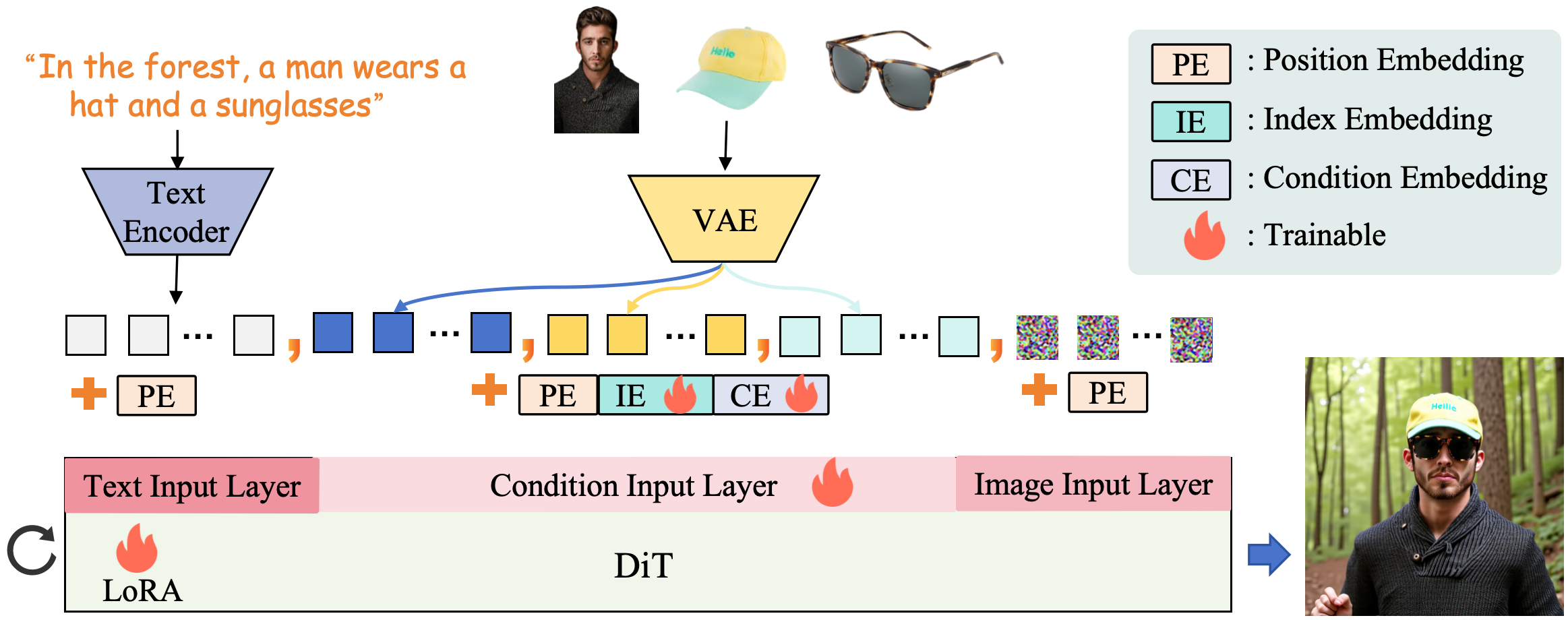
概要:DreamO 是由 字节跳动 智能创作团队 提出的图像定制统一框架,基于 Diffusion Transformer(DiT)架构,支持身份、主体、风格、试穿等多种条件的灵活组合与控制。该方法引入特征路由约束(Feature Routing Constraint)以增强条件一致性,并设计占位符策略(Placeholder Strategy)实现条件位置控制。训练过程中,DreamO 构建了涵盖多种定制任务的大规模数据集,并采用三阶段渐进式训练策略:初始阶段处理简单任务,全面训练阶段增强定制能力,质量对齐阶段纠正低质量数据引入的偏差。
标签:#图像定制 #多条件控制 #DiffusionTransformer #特征路由 #渐进式训练
StyleMe3D:多编码器驱动的3D风格迁移框架,提升艺术风格一致性

概要:StyleMe3D 是一个 阶跃星辰 和 上科大 提出的由多个编码器驱动的 3D 高斯点云风格迁移框架,旨在解决传统 3D Gaussian Splatting 在艺术风格迁移中的语义错位和细节破碎问题。该方法引入多模态风格条件控制、语义解耦和感知质量优化机制,包括动态风格得分蒸馏(DSSD)、对比风格描述子(CSD)、多尺度优化(SOS)和 3D 高斯质量评估(3DG-QA)。通过仅优化 RGB 属性,StyleMe3D 保持几何结构完整性,实现从单一物体到复杂场景的风格一致性,适用于游戏、虚拟世界和数字艺术等应用场景。
标签:#3D风格迁移 #高斯点云 #多模态建模 #语义解耦 #实时渲染