T-LoRA开启单图微调新时代 | MemOS发布LLM记忆操作系统 | OmniPart推动3D可编辑生成【AI周报】
T-LoRA开启单图微调新时代 | MemOS发布LLM记忆操作系统 | OmniPart推动3D可编辑生成【AI周报】

摘要
本周亮点:MemOS 推出首个大模型记忆操作系统,T‑LoRA 实现单图扩散微调,OmniPart 支持可控 3D 生成,FM‑Vision‑Evals 建立多模态视觉评测基准。详见正文,参考链接见文末。
目录
- T‑LoRA:单图像扩散模型快速定制,无训练也不卡精度
- MemOS:面向 LLM 的记忆操作系统
- VLV‑AutoEncoder:无监督扩散蒸馏视觉语言模型
- 4KAgent:通用图像到4K超分辨率的智能代理系统
- OmniPart:可编辑语义部件驱动的 3D 对象生成框架
- FM‑Vision‑Evals:评测多模态模型的视觉理解能力基准平台
T‑LoRA:单图像扩散模型快速定制,无训练也不卡精度

概要:T‑LoRA 是由 ControlGenAI 团队提出的一种高效扩散模型适配技术,针对“仅有一张概念图像”的场景设计。该方法引入时步感知低秩适配机制(Timestep‑Dependent Low‑Rank Adaptation),并在参数初始化中加入正交策略,解决了标准 LoRA 在有限样本下的过拟合与泛化不足问题。T‑LoRA 可根据扩散时步动态调节低秩矩阵更新,并实现各组件参数独立初始化,显著提升概念保真度与文本对齐效果。设定下,其在单图临摹情况下对扩散模型进行快速细调,相较原 LoRA 方法大幅提高质量与对齐度,同时支持 Diffusers 框架,几秒内完成训练,适合高效低资源自定义。
标签:#图像生成 #扩散模型定制 #LoRA优化 #单图适配
MemOS:面向 LLM 的记忆操作系统
概要:MemOS 是由来自 上海交通大学 、 人大 、 中科大 等机构联合提出的“记忆操作系统”框架,旨在将长期记忆作为大型语言模型(LLMs)的一级资源进行管理。MemOS 定义了包含纯文本、激活和参数三类格式的内存单元——MemCube,赋予它们统一的生命周期管理、检索、融合与版本控制能力。系统具备预测性调度、异步融合机制和可移植记忆协议,支持跨模型、跨会话甚至设备共享记忆。实验证明,在 LoCoMo 基准上,MemOS 相比 OpenAI 基线模型在时间推理任务上提升了 159% 性能,整体准确率提升近 39%,同时令 token 使用量减少约 61% 。
标签:#记忆操作系统 #LLM记忆 #长期推理 #MemCube架构 #跨模型融合
VLV‑AutoEncoder(Vision‑Language‑Vision Auto‑Encoder):无监督扩散蒸馏视觉语言模型

概要:VLV‑AutoEncoder 是由 约翰霍普金斯大学 、 清华大学 和 瑞士莱斯大学 学者联合提出的创新模型,具备通过无监督方法利用扩散模型(如 Stable Diffusion)进行知识蒸馏的能力。该框架首先冻结文本生成扩散模型的解码器,并将其作为“语义信息瓶颈”。通过视觉编码器提取图像特征,对应转换为语言嵌入,之后由预训练大语言模型生成高质量图像描述。基于此设计,VLV 能显著降低训练成本(约 1,000 美元)且不需海量图文对齐数据,即在图像标注任务上实现性能与 GPT‑4o / Gemini 2.0 Flash 等顶尖模型相当。该方法不仅具备语义空间重构与多图像组合理解能力,还实现了从图像到语言的高质量端到端自动生成。
标签:#多模态自监督 #扩散蒸馏 #视觉语言模型 #知识瓶颈 #高效训练
4KAgent:通用图像到4K超分辨率的智能代理系统

概要:4KAgent 是 斯坦福大学 联合 Snap Inc 等一同开发的一款图像超分辨率智能代理系统,专为将任意输入图像提升至 4K 质量而设计。系统采用多智能体结构,由感知代理(Perception Agent)分析图像内容与降质类型,并生成恢复策略,由恢复代理(Restoration Agent)执行递归式“执行→反思→回滚”流程。该模型还集成 Q-MoE 专家策略与专用人脸修复流程,以不同模块协同优化不同图像区域。团队制作了大规模测试集 DIV4K-50,用于评价超分精度与重建质量。4KAgent 在处理传统照片、AI 图像、遥感和显微成像等广泛场景下表现稳定,其通用性和模块化设计使其可适配多种恢复任务。
标签:#图像超分 #Agent #4K增强 #Q-MoE #面部修复
OmniPart:可编辑语义部件驱动的 3D 对象生成框架
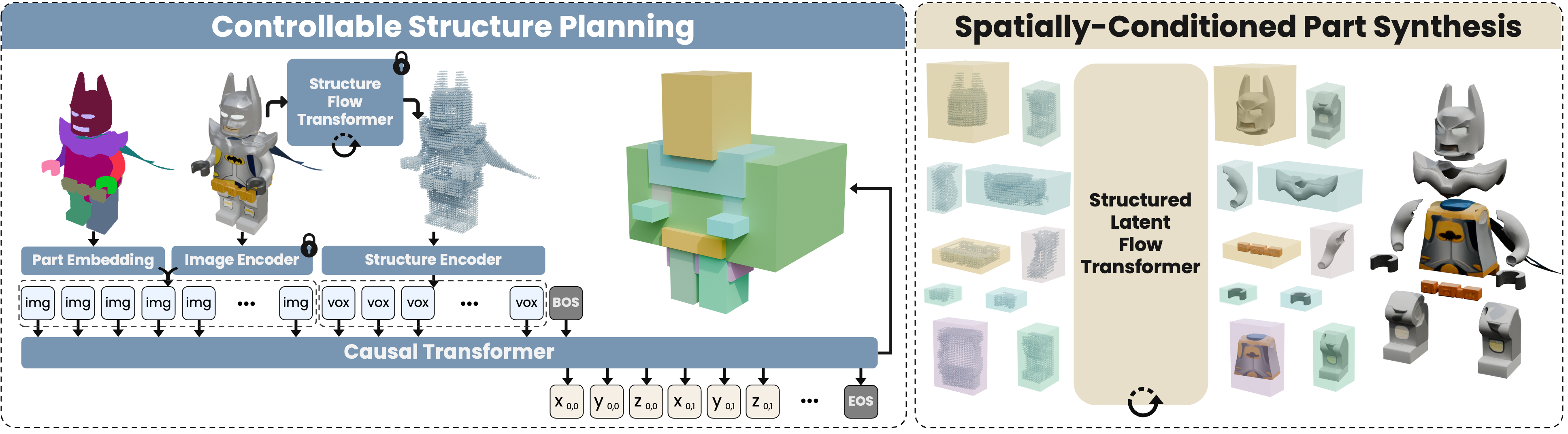
概要:OmniPart 是一项面向交互式应用的创新研究,由一组学者共同提出,旨在生成具有显式、可编辑部件结构的 3D 资产。相较于传统生成的整体网格,OmniPart 能根据用户定义的部件粒度,自动规划部件结构并通过顺序生成方式创建各部件,兼顾结构连贯与部件语义解耦。其核心包括自回归结构规划模块和空间条件调整流(rectified flow)模型,使生成对象既具备高度可编辑性,又在整体形态上保持稳健一致。凭借该框架,用户可以仅输入单张 2D 图像并指定部分 mask,即可迅速获得可控、可编辑的 3D 模型。
标签:#3D生成 #语义解耦 #可编辑部件 #自回归规划 #扩散模型
FM‑Vision‑Evals:评测多模态模型的视觉理解能力基准平台

概要:FM‑Vision‑Evals 是 EPFL VILAB 发布的首个基于 prompt chaining 框架,多任务评测包括语义分割、目标检测、图像分类、深度估计和表面法线预测等标准视觉任务的数据集。团队通过将视觉任务拆解为可由 MFM(如 GPT‑4o、Gemini、Claude、Qwen2‑VL、Llama 等)以文本方式处理的子任务,建立统一评测流程,形成公平可比较的评价体系。研究发现:GPT‑4o 在语义任务上表现最优,但所有多模态基础模型(MFMs)在几何任务上均落后于专业视觉模型;相比之下,MFMs 在语义任务上表现接近,但仍不及专用模型。基于 GPT‑4o 的原生图像生成探索显示其存在“语义重构”倾向而非精准像素级输出。
标签:#视觉基准 #多模态评测 #Benchmark #GPT‑4o