X‑Omni融合生成与理解|HunyuanWorld‑1.0构建可交互3D世界|ScreenCoder自动图像转代码【AI周报】
X‑Omni融合生成与理解|HunyuanWorld‑1.0构建可交互3D世界|ScreenCoder自动图像转代码【AI周报】

摘要
本周亮点:X‑Omni利用强化学习驱动多模态理解与高质量图像生成统一;HunyuanWorld‑1.0从图像或文本构建可交互的3D世界;ScreenCoder构建多智能体UI编码系统,实现图像到代码自动转换。详见正文,相关参考链接请见文末。
目录
- X‑Omni:强化学习驱动的统一多模态自回归图像生成
- HunyuanWorld 1.0:文本/图像生成可交互沉浸式 3D 世界
- ARC-Hunyuan‑Video‑7B:视频理解与生成统一框架
- GPT‑Image‑Edit‑1.5M:百万级 GPT 生成图像编辑三元组数据集
- ScreenCoder:多智能体驱动的视觉到前端代码生成系统
- AlphaVAE:端到端 RGBA 图像生成与重构统一模型
X‑Omni:使用强化学习提升离散自回归图像生成质量的统一多模态模型
 概要:X‑Omni 是腾讯混元团队提出的首个基于强化学习的统一多模态模型,通过引入语义图像 tokenizer 与离散自回归机制,实现图像与文本的一体化生成与理解。团队使用强化学习优化 SFT 模型,使得生成图像质量、美学评分与长文本渲染能力均超过其他开源统一模型,同时准确遵循复杂指令并在任意分辨率下生成高保真图像。此模型已在 GitHub 和 Hugging Face 上发布,并附带 LongText‑Bench 基准与推理代码供社区使用。
概要:X‑Omni 是腾讯混元团队提出的首个基于强化学习的统一多模态模型,通过引入语义图像 tokenizer 与离散自回归机制,实现图像与文本的一体化生成与理解。团队使用强化学习优化 SFT 模型,使得生成图像质量、美学评分与长文本渲染能力均超过其他开源统一模型,同时准确遵循复杂指令并在任意分辨率下生成高保真图像。此模型已在 GitHub 和 Hugging Face 上发布,并附带 LongText‑Bench 基准与推理代码供社区使用。
标签:#自回归图像生成 #强化学习 #多模态统一 #长文本渲染 #复杂指令控制
HunyuanWorld 1.0:从文本或图像生成可探索、可交互的沉浸式 3D 世界
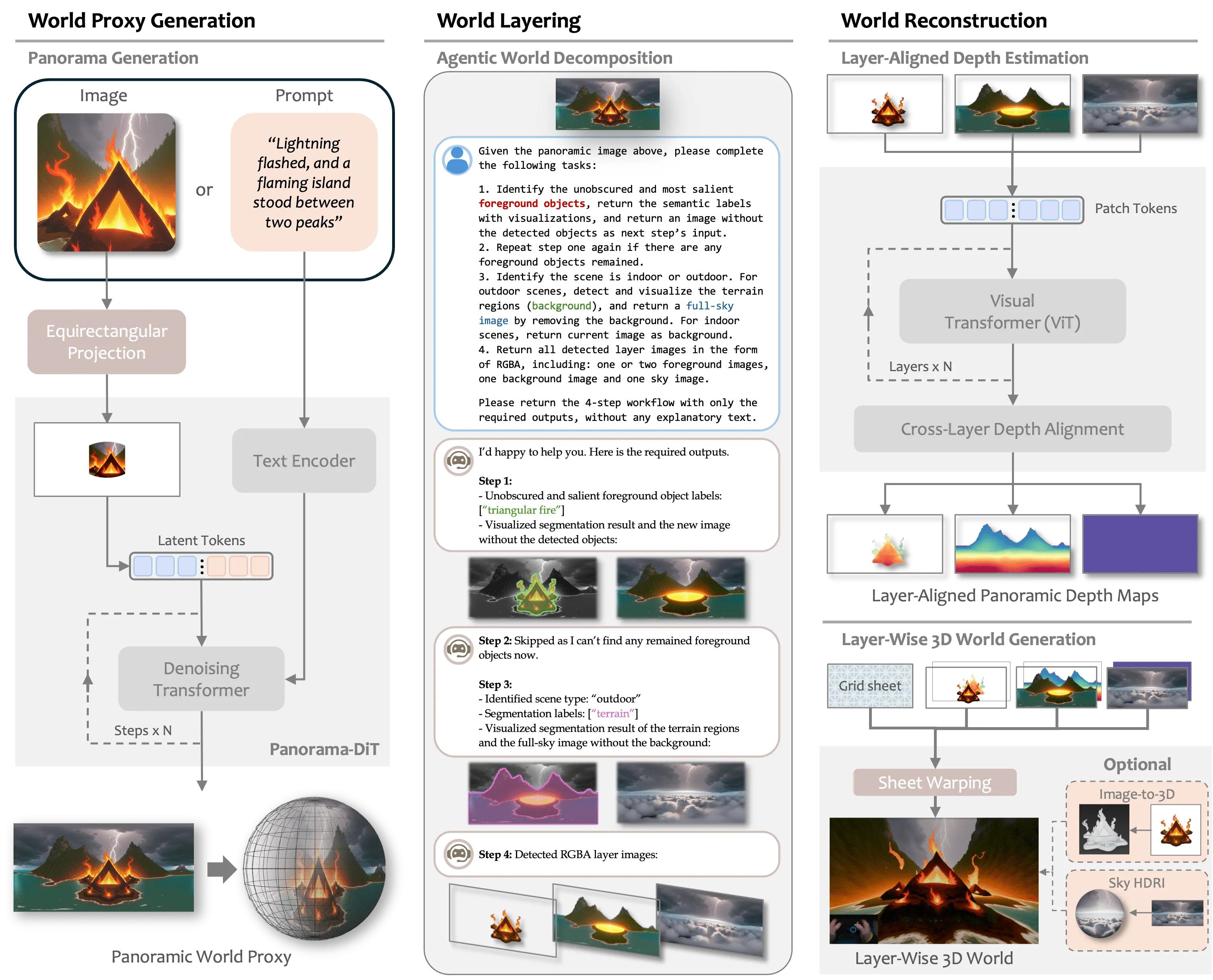 概要:HunyuanWorld 1.0 是腾讯混元团队发布的首个支持模拟交互的 3D 世界生成系统,能够通过文本或单张图像构建具有语义分层与可导出的 3D mesh 世界。它使用全景图像作为生成代理,将场景拆解为语义层、再通过分层结构生成可探索的模型,兼顾内容一致性与渲染效率。系统支持虚拟现实、游戏开发与物理模拟应用,在多个基准上优于现有模型,并具备真实世界可应用能力。
概要:HunyuanWorld 1.0 是腾讯混元团队发布的首个支持模拟交互的 3D 世界生成系统,能够通过文本或单张图像构建具有语义分层与可导出的 3D mesh 世界。它使用全景图像作为生成代理,将场景拆解为语义层、再通过分层结构生成可探索的模型,兼顾内容一致性与渲染效率。系统支持虚拟现实、游戏开发与物理模拟应用,在多个基准上优于现有模型,并具备真实世界可应用能力。
标签:#3D世界生成 #全景代理 #语义分层 #互动模拟 #游戏与VR支持
ARC-Hunyuan‑Video‑7B:7B 模型驱动的视频理解与生成统一框架
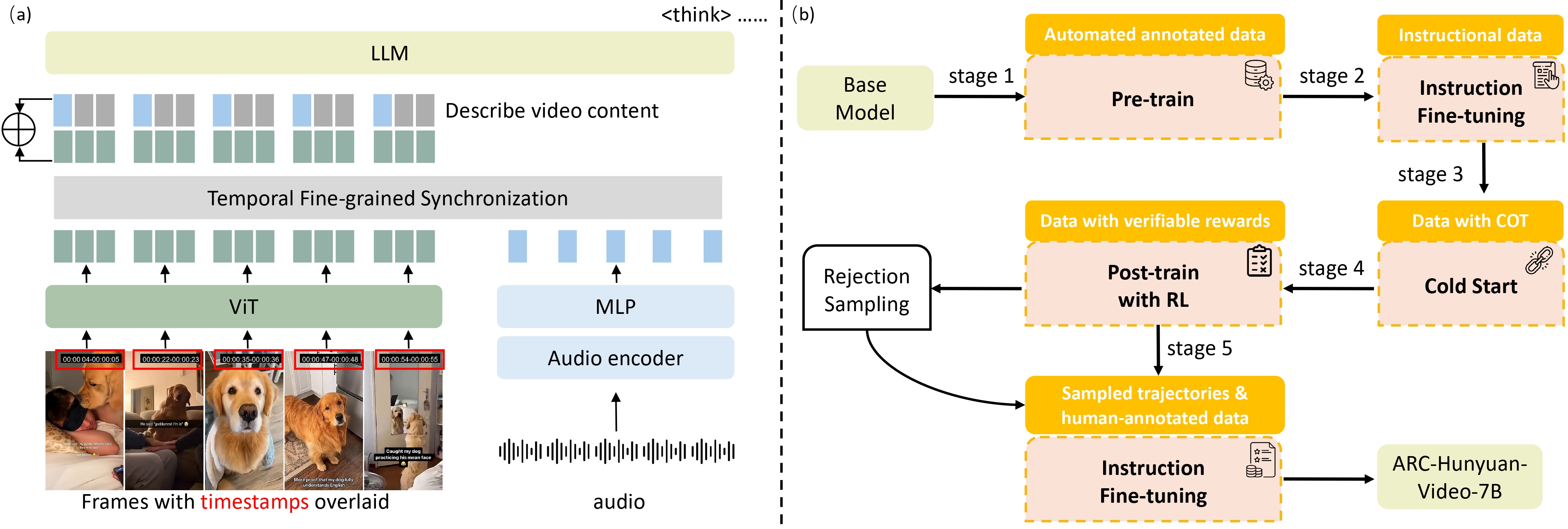 概要:ARC‑Hunyuan‑Video‑7B 是腾讯ARC团队开发的一款多模态语言模型,专注将视频理解、文本生成与视频生成任务整合至统一框架。该模型采用大规模视频文本对齐数据训练,并通过 ARC-VL 编码器和视频生成 decoder 模块协同工作,实现从视频帧描述、问答推理到视频生成的多任务支持。内部评测表明,相较于同参数规模的开源模型,该系统在视频问答、生成准确性与时序连贯性上均具有显著优势。
概要:ARC‑Hunyuan‑Video‑7B 是腾讯ARC团队开发的一款多模态语言模型,专注将视频理解、文本生成与视频生成任务整合至统一框架。该模型采用大规模视频文本对齐数据训练,并通过 ARC-VL 编码器和视频生成 decoder 模块协同工作,实现从视频帧描述、问答推理到视频生成的多任务支持。内部评测表明,相较于同参数规模的开源模型,该系统在视频问答、生成准确性与时序连贯性上均具有显著优势。
标签:#多模态语言模型 #视频理解 #文本生成 #统一框架 #7B模型
GPT‑Image‑Edit‑1.5M:百万级 GPT 生成图像编辑三元组数据集

概要:GPT‑Image‑Edit‑1.5M 是 UCSC‑VLAA 等团队基于 GPT‑4o 自动生成的图像编辑集合,整合并增强了 OmniEdit、HQ‑Edit 与 UltraEdit 三大数据源,构建了包含 150 万条指令-原图-编辑图的统一训练集。输出图像经过重新渲染,指令语义被重写优化,提高质量与对齐度。经 fine‑tune 后的 FluxKontext 模型在 GEdit‑EN、ImgEdit‑Full 及 Complex‑Edit 基准上表现优异,明显超越此前开源方案并逼近 GPT‑4o 等闭源模型表现。
标签:#图像编辑数据 #GPT-4o生成 #大规模三元组 #模型微调 #高质量对齐
ScreenCoder:多智能体驱动的视觉到前端代码生成系统
 概要:ScreenCoder 是由香港中文大学等团队提出的一款创新型系统,能够将界面设计(如手绘图或 mockup)自动转换为对应的 HTML/CSS 前端代码。系统设计为三阶段模块化流程:首先由 Grounding agent 基于视觉语言模型对界面组件进行识别与标注;接着 Planning agent 构建层次布局树;最后 Generation agent 通过 prompt 驱动生成高结构精度的代码。该框架还作为图像—代码对训练引擎,可实时生产大量数据并用于微调视觉语言模型,显著提升布局理解与生成准确度。大量实验显示其在结构一致性、代码正确率和语义对齐方面优于现有端到端方法。
概要:ScreenCoder 是由香港中文大学等团队提出的一款创新型系统,能够将界面设计(如手绘图或 mockup)自动转换为对应的 HTML/CSS 前端代码。系统设计为三阶段模块化流程:首先由 Grounding agent 基于视觉语言模型对界面组件进行识别与标注;接着 Planning agent 构建层次布局树;最后 Generation agent 通过 prompt 驱动生成高结构精度的代码。该框架还作为图像—代码对训练引擎,可实时生产大量数据并用于微调视觉语言模型,显著提升布局理解与生成准确度。大量实验显示其在结构一致性、代码正确率和语义对齐方面优于现有端到端方法。
标签:#视觉语言模型 #前端自动化 #多智能体架构 #布局理解 #UI生成
AlphaVAE:端到端 RGBA 图像生成与重构统一模型

概要:AlphaVAE 是清华大学最新提出的 RGBA (红绿蓝 + alpha 通道) 图像生成与重构 VAE 模型。创新地在变分自编码器中引入 alpha 通道感知机制,使模型能处理透明背景与遮罩信息,在仅使用 8K 图像训练的情况下,其 PSNR 提高约 4.9 dB,SSIM 提升约 3.2%,超出此前基于百万图像训练的 LayerDiffuse 方法。该方法采用复合训练目标,包括 alpha-blended 像素重构、patch 级保真损失、感知一致性与双 KL 发散约束,保证 RGB 与 alpha 表示间的潜变量一致性。AlphaVAE 提供了一种高效泛化能力强的生成方案,为 RGBA 图像建模提供了新的可能性。
标签:#RGBA 图像 #变分自编码器 #alpha 感知 #高保真重构 #小样本训练
参考链接
- X‑Omni 项目主页
- X‑Omni Github 仓库
- X‑Omni 论文
- HunyuanWorld 1.0 项目主页
- HunyuanWorld 1.0 Github 仓库
- HunyuanWorld 1.0 论文
- ARC‑Hunyuan‑Video‑7B 项目公告
- ARC‑Hunyuan‑Video‑7B Github 仓库
- ARC‑Hunyuan‑Video‑7B 论文
- GPT‑Image‑Edit 项目主页
- GPT‑Image‑Edit Github 仓库
- GPT‑Image‑Edit 论文
- ScreenCoder Github 仓库
- ScreenCoder 论文
- AlphaVAE Github 仓库
- AlphaVAE 论文