【论文精读】ResNet:Deep Residual Learning for Image Recognition
大约 7 分钟
【论文精读】ResNet:Deep Residual Learning for Image Recognition
摘要
ResNet 通过残差学习成功解决超深网络的训练难题,克服梯度消失与退化问题。在 ImageNet 分类任务中以 3.57% Top-5 错误率刷新纪录,并在目标检测、分割等任务中展现卓越性能。本文解析其核心设计、实验验证及影响。
目录
背景与研究目标
数据集与任务背景
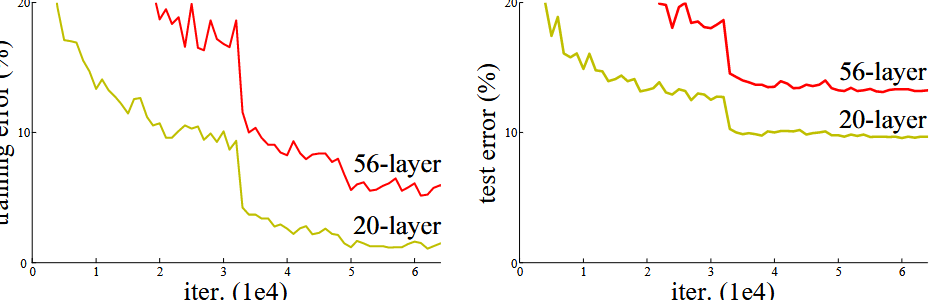
论文基于 ImageNet 数据集(1000 类,120 万训练图像)和 CIFAR-10(10 类,6 万图像)展开实验。随着 CNN 深度增加,模型在复杂任务中表现提升,但面临梯度消失和网络退化两大瓶颈。
主要参考文献
ResNet 的设计灵感来源于以下工作:
- 梯度消失问题:He 等人(2015)提出的权重初始化方法,以及 Ioffe 和 Szegedy(2015)的批归一化(Batch Normalization)技术,为训练深层网络奠定了基础。
- 残差表示理论:Highway Networks 的跨层连接设计启发了残差块的构建。
方法与创新点
残差学习的数学原理
在传统神经网络中,目标是直接逼近一个映射 $H(x)$,但当网络变得很深时,梯度容易消失,导致优化困难。ResNet 通过引入残差学习,让网络学习一个残差函数 $F(x) = H(x) - x$,从而将最终映射表示为:
$$ H(x) = F(x) + x $$
优化更容易的原因:
- 目标简化:如果 $H(x)$ 接近恒等映射,则 $F(x)$ 变成 0,使得优化更稳定。
- 性能兜底:即使新增层未能学习到有效特征,网络仍可退化为浅层版本,避免性能损失。
类比理解:普通深度网络像是在陡峭山坡上行走,容易摔倒(梯度消失)。ResNet 的残差连接相当于提供了“阶梯”,使得优化过程更加稳定。
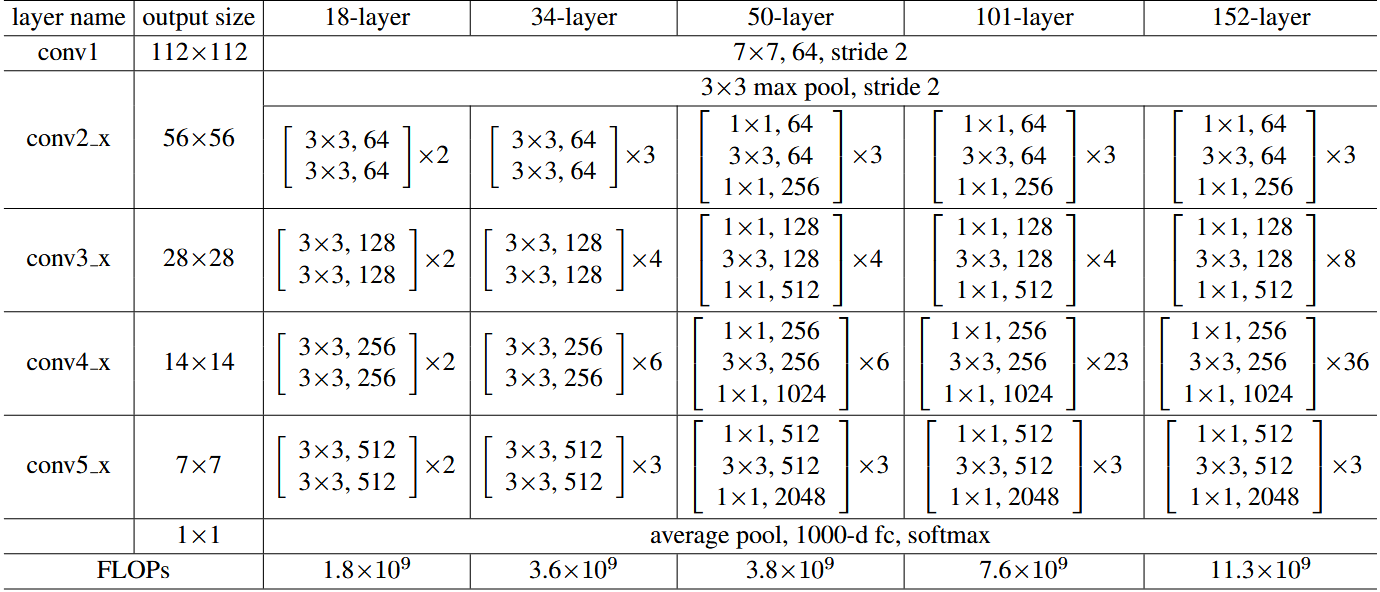
网络架构设计
基础残差块
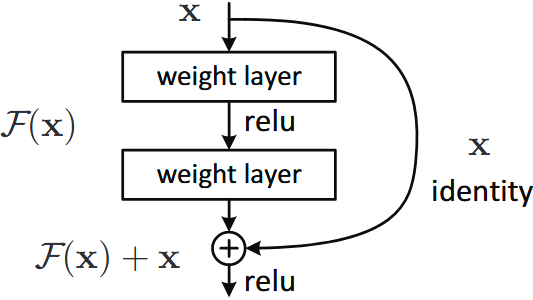
- 残差连接:通过恒等映射实现 $H(x) = F(x) + x$,确保深层网络至少不差于浅层网络。
- 适用于较浅的网络,如 ResNet-18 和 ResNet-34。
瓶颈残差块
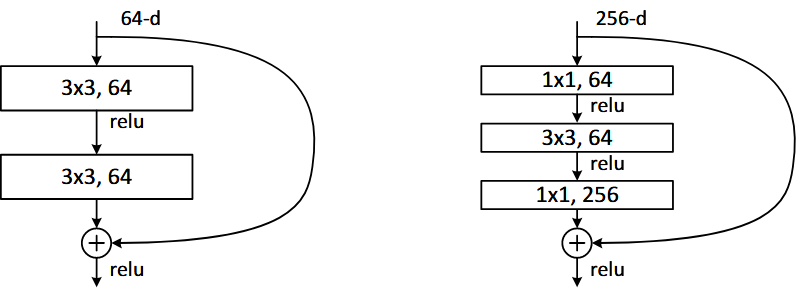
- ResNet-50 及以上深层网络采用 $1 \times 1$ → $3 \times 3$ → $1 \times 1$ 结构:
- $1 \times 1$ 卷积:降维,减少计算量。
- $3 \times 3$ 卷积:执行特征提取。
- $1 \times 1$ 卷积:升维,还原通道数。
残差学习与梯度传播
- 退化问题解决:传统深层网络随着深度增加出现性能下降,而残差连接允许梯度直接回传至浅层,缓解梯度消失。
- 恒等映射优势:即使新增层未能学习有效特征,网络仍可退化为浅层版本,避免性能损失。
批归一化与初始化策略
- 批归一化(BN):每个卷积层后加入 BN 层,加速训练并提升稳定性。
- He 初始化:配合 ReLU 激活函数,使用 He 初始化方法避免梯度爆炸。
实验与结果分析
实验设置与数据处理
- 硬件环境:8 GPU 并行训练,采用同步 SGD 优化器。
- 数据增强:随机裁剪、水平翻转和 PCA 颜色扰动,提升模型鲁棒性。
ImageNet 分类实验
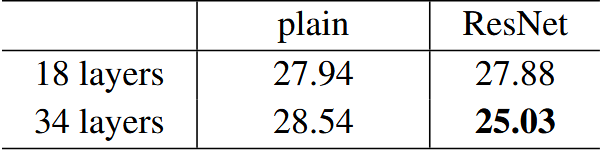
ResNet vs Plain Network
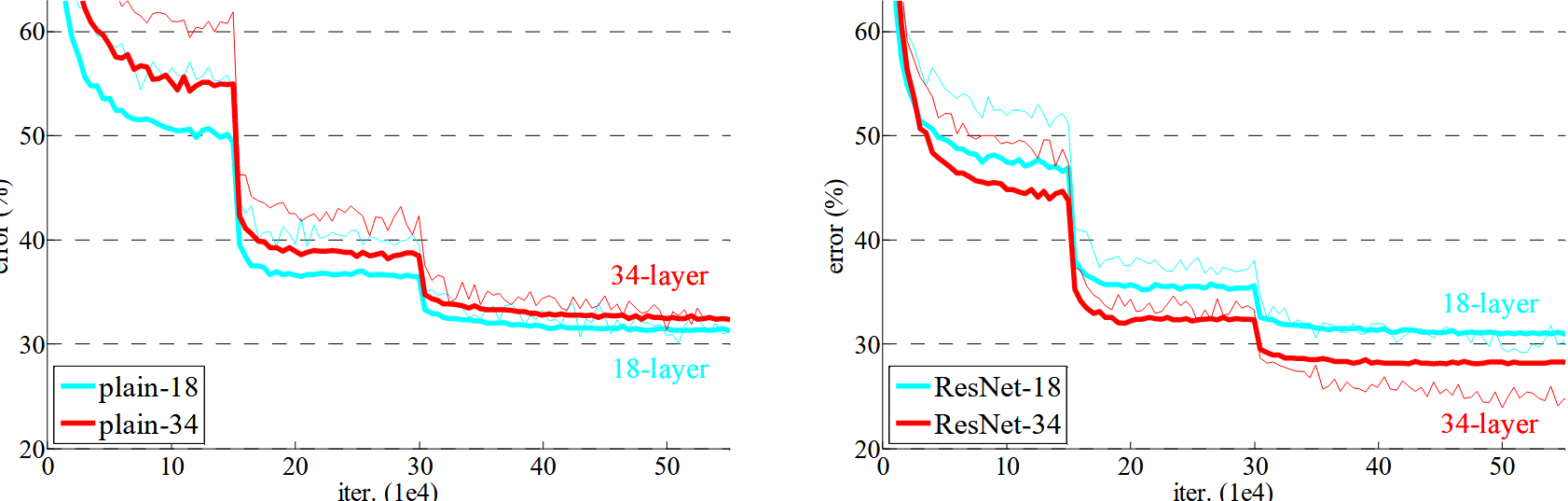
- 普通 CNN:34 层 plain 网络的训练误差高于 18 层,深度增加导致优化困难。
- ResNet:通过残差学习,34 层 ResNet 的性能优于 18 层 ResNet。
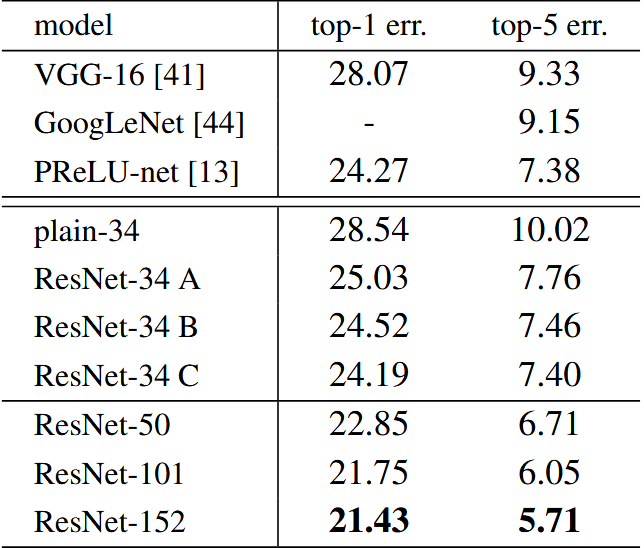
ResNet 在 ImageNet 上的训练和验证误差
- ResNet 训练误差下降更快,最终验证误差更低。
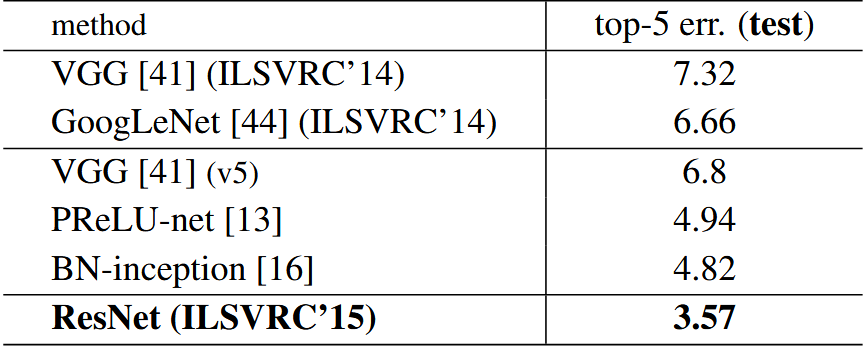
- 152 层 ResNet 的单模型 Top-5 验证错误率仅为 3.57%,优于 GoogLeNet 近一倍。
CIFAR-10 超深网络实验
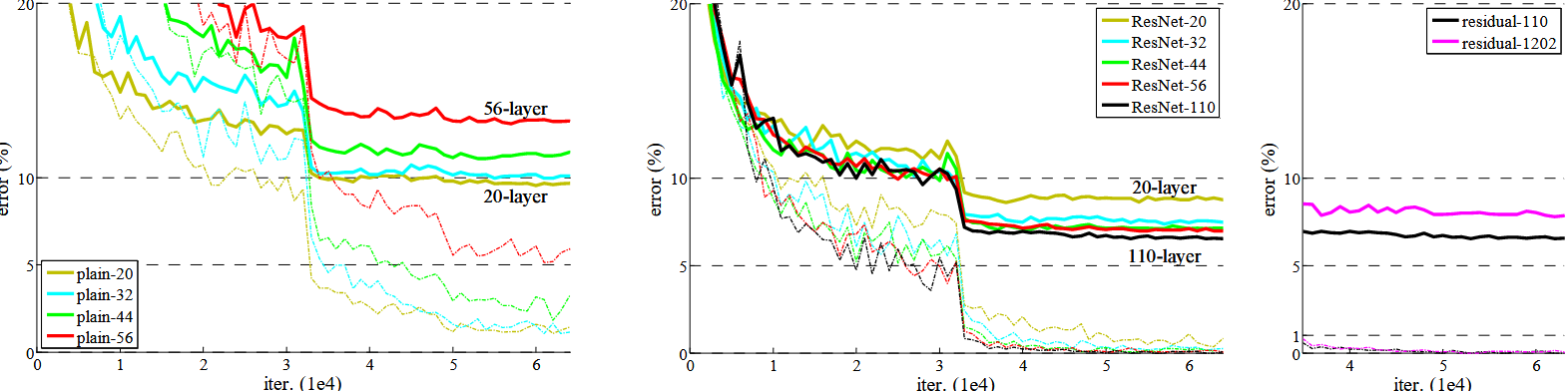
Plain 网络 vs ResNet
- 普通 CNN:深度增加导致训练误差和测试误差上升,表现不稳定。
- ResNet:ResNet-110 训练误差低,测试误差较低,深度对其影响较小。
CIFAR-10 上超深 ResNet(110 层 vs 1202 层)
- 1202 层 ResNet 训练误差几乎为 0,但测试误差略高,表明可能过拟合。
Shortcut 选项实验
- Option B(投影连接) 在计算量可接受的情况下,性能最佳。
- Option C(全投影连接) 效果稍好,但计算量过大。
目标检测实验(COCO & Pascal VOC)
COCO 数据集上 Faster R-CNN 目标检测 mAP

-*ResNet-101 替换 VGG-16 后,mAP 提升 5.8%。
PASCAL VOC 数据集上 Faster R-CNN 目标检测 mAP

- 在 PASCAL VOC 数据集上,mAP 提升 3.5%。
模型启发与方法延伸
ResNet 的残差学习框架影响深远,催生了多个优化模型,并在不同领域得到广泛应用。
深度网络的优化
- ResNeXt:通过 分组卷积 降低计算量,提高计算效率。
- DenseNet:采用 密集连接,增强特征复用,减少参数冗余。
- EfficientNet:结合 NAS(神经架构搜索)优化深度、宽度、分辨率的比例,提高计算效率。
残差思想的跨领域应用
- NLP:Transformer 采用 残差连接 改善梯度流动,提升训练稳定性。
- 蛋白质结构预测:AlphaFold 2 利用 ResNet 结构建模远程依赖,提高预测精度。
- GAN:BigGAN 通过残差连接提升生成器的稳定性,缓解模式崩溃问题。
轻量化与高效网络
- MobileNetV2:使用 倒残差(Inverted Residuals) 结构,提高移动端计算效率。
- ShuffleNet:结合 ResNet 和分组卷积,优化计算资源分配。
- GhostNet:降低冗余计算,提高模型推理速度。
结论与未来展望
ResNet 通过残差学习成功解决了深度网络的训练瓶颈,但仍有优化空间:
计算效率优化
- 问题:深层 ResNet(如 ResNet-152)计算成本高,参数冗余。
- 改进:ResNeXt 采用 分组卷积 降低计算量,EfficientNet 通过 NAS 进行结构优化。
特征复用与梯度流动
- 问题:部分残差块学习冗余特征,网络利用率不足。
- 改进:DenseNet 通过 跨层连接 增强特征复用,Stochastic Depth 随机丢弃残差块提升泛化能力。
多任务学习与模型适应性
- 问题:ResNet 主要针对单任务优化,难以适应多模态任务。
- 改进:结合 Transformer 结构 提高跨任务泛化能力,探索 动态深度网络 以提高计算效率。
理论研究与优化
- 问题:残差学习为何有效?最优深度如何确定?退化问题的数学原理仍不明确。
- 改进:进一步研究 梯度行为、最优深度估计 及更稳健的优化方法。