MiniMax-01扩展长文本处理|Seaweed-APT一步视频生成|AnyDressing个性化虚拟试衣【AI周报】
MiniMax-01扩展长文本处理|Seaweed-APT一步视频生成|AnyDressing个性化虚拟试衣【AI周报】

摘要
本周亮点:MiniMax-01采用Lightning Attention支持超长文本处理,提升多模态理解;Seaweed-APT通过对抗性后训练实现高分辨率视频的即时生成;AnyDressing利用定制化网络提供多服装虚拟试衣。详情见正文。
目录
- MiniMax-01:扩展基础模型的长上下文处理能力
- MangaNinja:精确参考引导的线稿上色
- Seaweed-APT:一步式视频生成的扩散对抗后训练
- LayerAnimate:动画的层级控制
- AnyDressing:可定制的多服装虚拟试衣模型
- MicroDiffusion:基于稀疏Transformer的扩散模型优化训练方法
MiniMax-01:扩展基础模型的长上下文处理能力

概要:MiniMax-01 系列模型由 MiniMax 公司推出,包括 MiniMax-Text-01 和 MiniMax-VL-01,旨在提供更长上下文处理能力。通过引入高效的 Lightning Attention 机制,这些模型在处理长达数百万标记的上下文时,仍能保持高效的训练和推理性能。其中,MiniMax-Text-01 在标准基准测试中表现出色,可在推理阶段处理多达 400 万标记的上下文。MiniMax-VL-01 则通过持续训练 5120 亿视觉语言标记,展示了卓越的多模态理解能力。实验结果表明,这些模型在性能上可与 GPT-4o 和 Claude-3.5-Sonnet 等顶级模型媲美,同时提供了长达 20-32 倍的上下文窗口。
标签:#MiniMax-01 #MiniMax-Text-01 #MiniMax-VL-01 #LightningAttention #长上下文 #多模态理解
MangaNinja:精确参考引导的线稿上色

概要:MangaNinja 是由 香港大学、香港科技大学、同济实验室 和 蚂蚁集团 的研究者联合提出的一种基于参考的线稿上色方法,旨在实现精确的角色细节转移。该方法引入了两个关键设计:一个是Patch Shuffling 模块,用于在参考彩色图像和目标线稿之间建立对应关系;另一个是点驱动控制方案,允许用户进行细粒度的颜色匹配。实验结果表明,MangaNinja 在处理具有显著差异的参考图像和线稿时,能够保持细节的一致性,超越了现有的解决方案。此外,用户可以通过点控制实现更复杂的任务,如处理极端姿势和阴影、跨角色上色以及多参考图像的融合等。
标签:#MangaNinja #线稿上色 #参考引导 #深度学习
Seaweed-APT:一步式视频生成的扩散对抗后训练

概要:Seaweed-APT 是由 字节跳动 的研究团队提出的一种新颖的视频生成模型,旨在通过对抗性后训练(APT)技术,实现一步式高分辨率视频生成。传统的扩散模型在视频生成任务中需要多次神经网络评估,导致生成速度缓慢。Seaweed-APT 通过在扩散预训练后进行对抗性后训练,仅需一步推理即可生成高质量的视频。实验结果表明,该模型能够实时生成 2 秒、1280×720 分辨率、24 帧/秒的视频,同时在一步式图像生成任务中也表现出与当前最先进方法相当的质量。
标签:#SeaweedAPT #一步式视频生成 #扩散模型 #对抗性后训练 #字节跳动
LayerAnimate:动画的层级控制
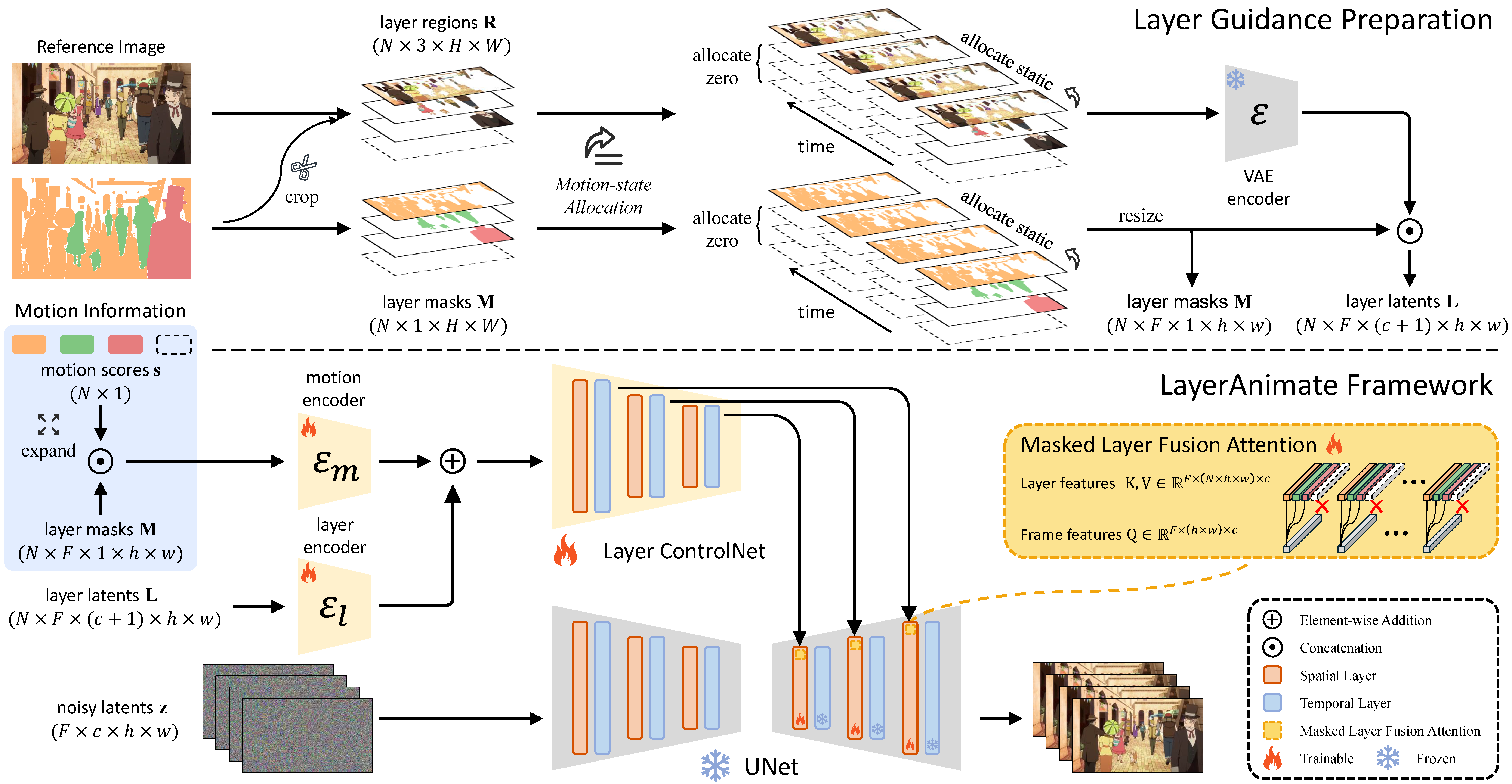
概要:LayerAnimate 是由 中国科学院自动化研究所 和 中国科学院大学 的研究人员提出的一种新颖的动画控制生成框架,旨在通过视频扩散模型对动画的各个层级进行精细控制。该方法允许用户独立操控前景和背景元素,提供冻结特定元素、使用部分草图动画角色以及切换静态或动态背景等功能。为了解决层级数据有限的问题,研究者设计了一个数据处理流程,包括自动元素分割、运动状态的层次合并以及运动一致性优化。实验结果表明,LayerAnimate 在动画质量、控制精度和可用性方面均优于现有方法,为专业动画师和业余爱好者提供了新的创作工具。
标签:#LayerAnimate #动画生成 #层级控制 #视频扩散模型
AnyDressing:可定制的多服装虚拟试衣模型

概要:AnyDressing 是由 字节跳动 和 清华大学 提出的虚拟试衣模型,可根据多服装和文本提示生成个性化人物图像。模型包括 GarmentsNet 和 DressingNet 两个核心模块,分别负责服装特征提取和多服装纹理融合。通过 Dressing Attention (DA) 和 Garment-Enhanced Texture Learning (GTL),实现了高质量服装纹理表达和精准区域控制。实验结果表明,AnyDressing 在复杂服装试衣任务中表现优异实验结果表明,AnyDressing 在多种场景和复杂服装的虚拟试衣任务中表现出色,并且兼容 LoRA、ControlNet 和 FaceID 等插件,提升了合成图像的多样性和可控性。
标签:#AnyDressing #虚拟试衣 #多服装 #生成模型 #字节跳动 #清华大学
MicroDiffusion:微预算下的大规模扩散模型训练

概要:MicroDiffusion 是 索尼研究团队 提出的一种高效低成本的扩散模型训练方法。与传统直接训练扩散模型的方式不同,MicroDiffusion 通过训练一个稀疏 Transformer 来取代标准的扩散模型,显著降低了计算需求。模型设计上,采用稀疏注意力机制,在保留生成能力的同时减少参数数量,提高了内存利用效率。通过仅使用 3700 万张公开的真实与合成图像,该方法以极低的成本(约 1890 美元)完成了从头训练。实验结果显示,该模型在 COCO 数据集上的零样本生成任务中,达到了 12.7 的 FID 分数,尽管计算资源极其有限,却实现了与传统扩散模型媲美的生成质量。
标签:#MicroDiffusion #扩散模型 #低预算 #COCO #图像生成