ReCamMaster重塑视频视角 | PLADIS优化Diffusion推理 | Impossible Videos探索反现实【AI周报】
ReCamMaster重塑视频视角 | PLADIS优化Diffusion推理 | Impossible Videos探索反现实【AI周报】

摘要
本周亮点:ReCamMaster通过摄像机轨迹调整实现视频再渲染;PLADIS采用稀疏注意力优化扩散推理;Impossible Videos提出IPV-Bench评估体系,探索反现实视频生成;Hunyuan3D2.0高效生成高精度3D资产。
目录
- ReCamMaster:从单个视频生成新视角和运动轨迹视频的框架
- PLADIS:利用稀疏性在推理阶段突破Diffusion模型中的注意力限制
- Personalize Anything:基于Diffusion Transformer的个性化图像生成
- Impossible Videos:探索反事实与反现实视频的生成与理解
- Hunyuan3D 2.0:腾讯推出的高精度3D资产生成系统
- StarVector:从图像和文本生成可缩放矢量图形代码
ReCamMaster:从单个视频生成新视角和运动轨迹视频的框架
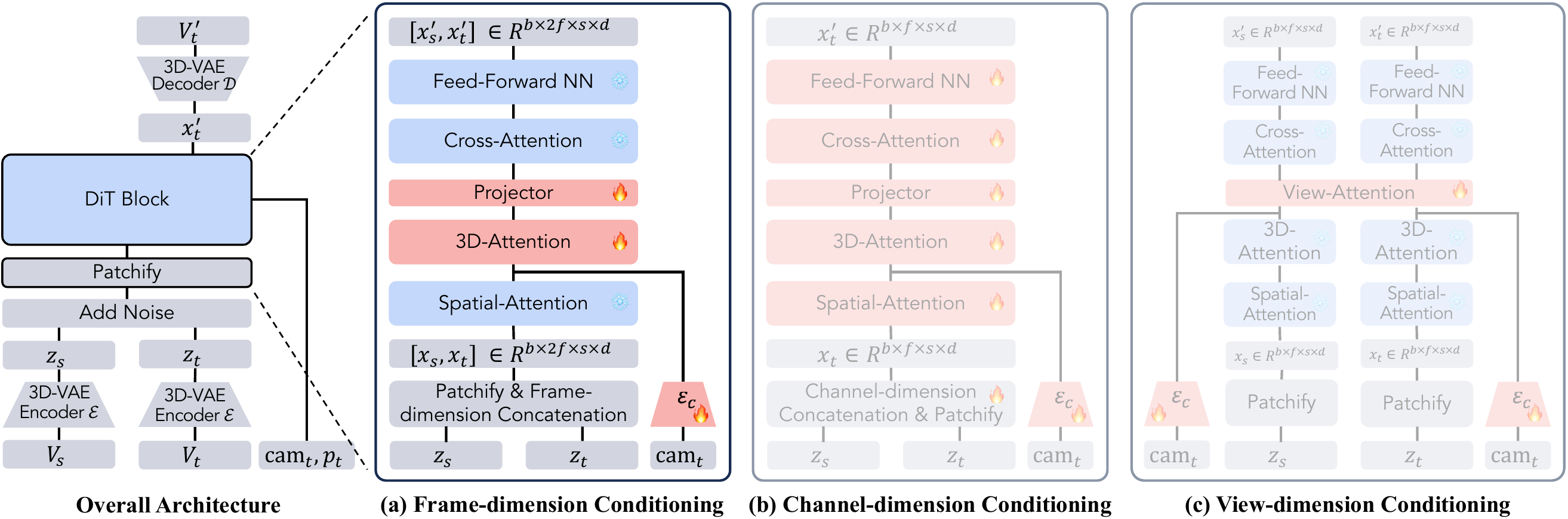
概要:ReCamMaster 是由 浙江大学、快手科技、香港中文大学 和 华中科技大学 联合开发的创新框架,旨在从单个视频生成具有新视角和运动轨迹的视频内容。该框架利用预训练的文本到视频生成模型,并通过精心设计的视频条件机制,实现高质量的视频重渲染。其主要功能包括相机轨迹控制(如平移、旋转、缩放等)、高质量视频生成以及支持大规模数据集。ReCamMaster 可应用于视频稳定化、视频超分辨率、自动驾驶和机器人视觉,以及视频创作和后期制作等领域。
标签:#视频生成 #新视角 #相机轨迹控制 #视频重渲染 #多视角数据增强
PLADIS:利用稀疏性在推理阶段突破Diffusion模型中的注意力限制

概要:PLADIS 是由 三星研究院 提出的一种创新方法,旨在通过在推理阶段利用稀疏注意力机制,提升预训练Diffusion模型(如 U-Net/Transformer)的性能。具体而言,PLADIS 在推理过程中,对交叉注意力层中的查询-键相关性进行外推,无需额外训练或增加神经函数评估(NFEs)。通过利用稀疏注意力的抗噪性,PLADIS 释放了文本到图像Diffusion模型的潜力,使其在之前表现欠佳的领域取得显著效果。该方法可无缝集成到现有的引导技术中,包括引导蒸馏模型。大量实验表明,PLADIS 在文本对齐和人类偏好方面取得了显著改进,提供了一种高效且普遍适用的解决方案。
标签:#Diffusion模型 #稀疏注意力 #推理优化 #文本到图像生成 #模型增强
Personalize Anything:基于Diffusion Transformer的个性化图像生成
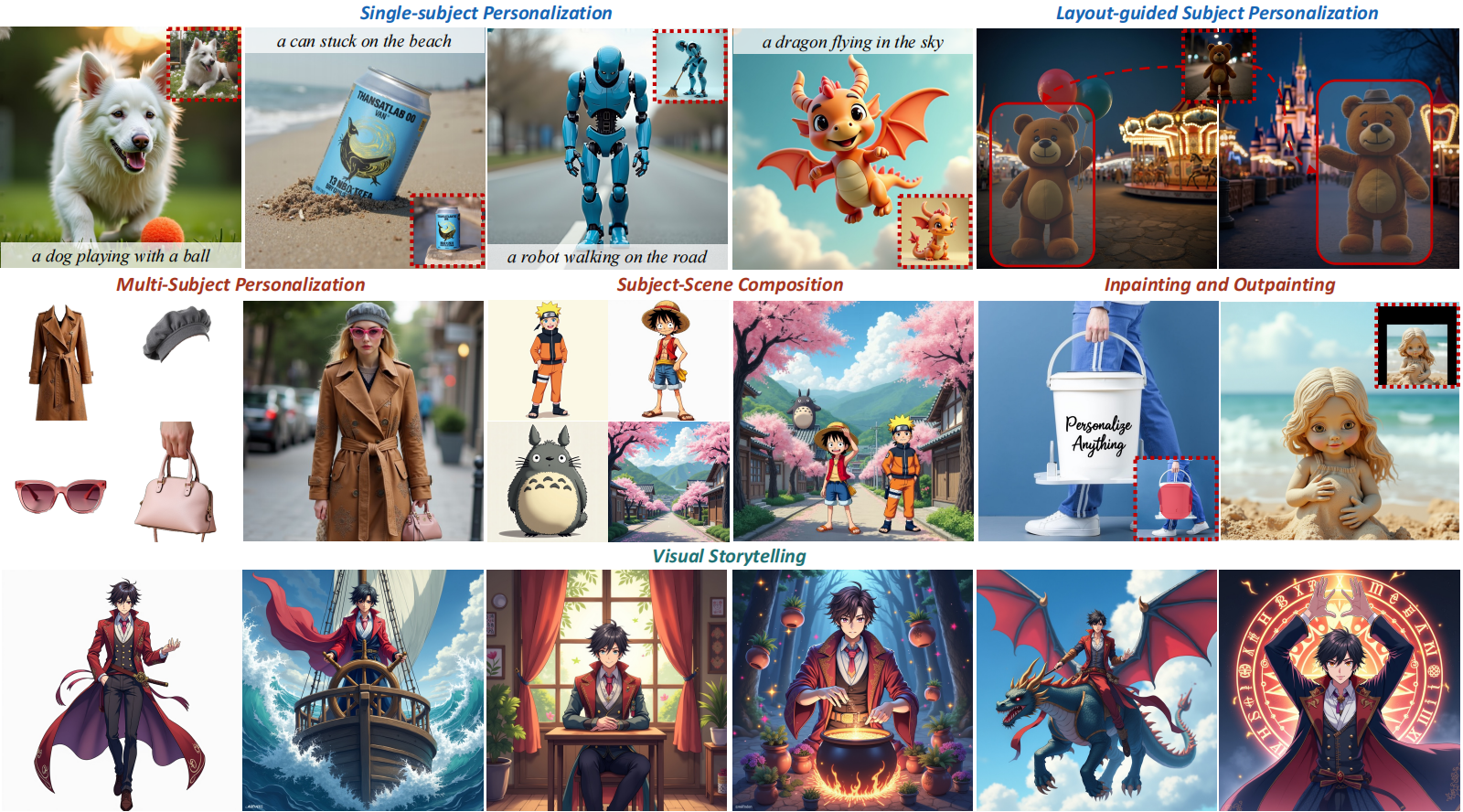
概要:Personalize Anything 是由 清华大学、北京航空航天大学 和 中国人民大学 等机构联合推出的创新框架,旨在利用Diffusion Transformer(DiT)实现个性化的图像生成。该方法通过在DiT中引入时间步自适应的标记替换策略和补丁扰动技术,在无需训练的情况下,实现了对特定主体的高保真图像生成。这一框架支持布局引导生成、多主体个性化以及掩码控制编辑等多种应用场景,展现了在身份保持和多样性方面的卓越性能。
标签:#Personalize Anything #Diffusion Transformer #无训练框架 #标记替换 #补丁扰动
Impossible Videos:探索反事实与反现实视频的生成与理解

概要:Impossible Videos 是由 新加坡国立大学 Show Lab 提出的创新研究,旨在探索生成和理解违反物理、生物、地理或社会规律的反事实与反现实视频内容。研究团队构建了一个名为 IPV-Bench 的基准,包括涵盖4个领域、14个类别的分类体系,以及用于评估视频生成模型的提示集和用于评估视频理解模型的视频基准。通过对现有视频生成和理解模型的综合评估,研究揭示了这些模型在处理不可能视频内容时的局限性,并为未来的视频模型研究指明了方向。
标签:#Show lab #视频生成 #视频理解 #IPV-Bench #反事实
Hunyuan3D 2.0:腾讯推出的高精度3D资产生成系统

概要:Hunyuan3D 2.0 是由 腾讯 推出的开源3D生成大模型,采用几何与纹理分离的两阶段架构,专注于从文本和图像高效生成高分辨率3D模型。 该系统首先生成无纹理的几何模型,然后合成高分辨率纹理贴图,有效提升了3D生成的精度与效率。其性能在几何细节、条件对齐和纹理质量等方面表现出色,超越了现有的开源和闭源模型。
标签:#3D生成 #开源模型 #几何与纹理分离 #高分辨率 #腾讯
StarVector:从图像和文本生成可缩放矢量图形代码

概要:StarVector 是由 Mila – 魁北克人工智能研究所 等机构提出的一种多模态大型语言模型,旨在从图像和文本生成可缩放矢量图形(SVG)代码。该模型利用 CLIP 图像编码器提取视觉表示,通过适配器模块将其转换为视觉标记,并结合 StarCoder 模型生成精确的 SVG 代码。为训练 StarVector,研究团队构建了包含 200 万个样本的多样化数据集 SVG-Stack,使模型能够广泛泛化于矢量化任务,并精确使用椭圆、多边形和文本等 SVG 基元。实验结果表明,StarVector 在视觉质量和复杂性处理方面实现了最新性能,生成的 SVG 更加紧凑且语义丰富。
标签:#SVG生成 #多模态模型 #大型语言模型 #图像矢量化 #视觉质量
参考链接
- ReCamMaster 官网
- ReCamMaster GitHub
- ReCamMaster 论文
- PLADIS 官网
- PLADIS GitHub
- PLADIS 论文
- Personalize Anything 官网
- Personalize Anything GitHub
- Personalize Anything 论文
- Impossible Videos 官网
- Impossible Videos GitHub
- Impossible Videos 论文
- InfiniteYou 官网
- InfiniteYou GitHub
- InfiniteYou 论文
- Hunyuan3D 2.0 官网
- Hunyuan3D 2.0 GitHub
- StarVector 官网
- StarVector GitHub
- StarVector 论文