Imagine yourself 无调优图像生成亮相 | NovelAI Diffusion V3 提升生成效率 | BAAI 推出多模态模型 Emu3【AI 周报】
Imagine yourself 无调优图像生成亮相 | NovelAI Diffusion V3 提升生成效率 | BAAI 推出多模态模型 Emu3【AI 周报】
摘要
本周 AI 周报聚焦最新图像生成技术:Imagine yourself 无需调优即可生成个性化图像,NovelAI DiffusionV3 提升了生成效率与质量,智源研究院发布的多模态模型 Emu3 展现跨模态生成强大潜力,为 AI 发展带来更多创新可能。
目录
- Imagine yourself:无需调优的个性化图像生成
- NovelAI Diffusion V3 中对 SDXL 的改进
- Make Pixels Dance: 扩散模型中的动态图像生成
- Molecular Modeling AI Initiative by Allen Institute
- MIMO: Vision Transformer with Multimodal Input
- Emu: BAAI 的多模态大模型项目
- PromptSliders: 基于滑动条的提示优化模型
Imagine yourself:无需调优的个性化图像生成
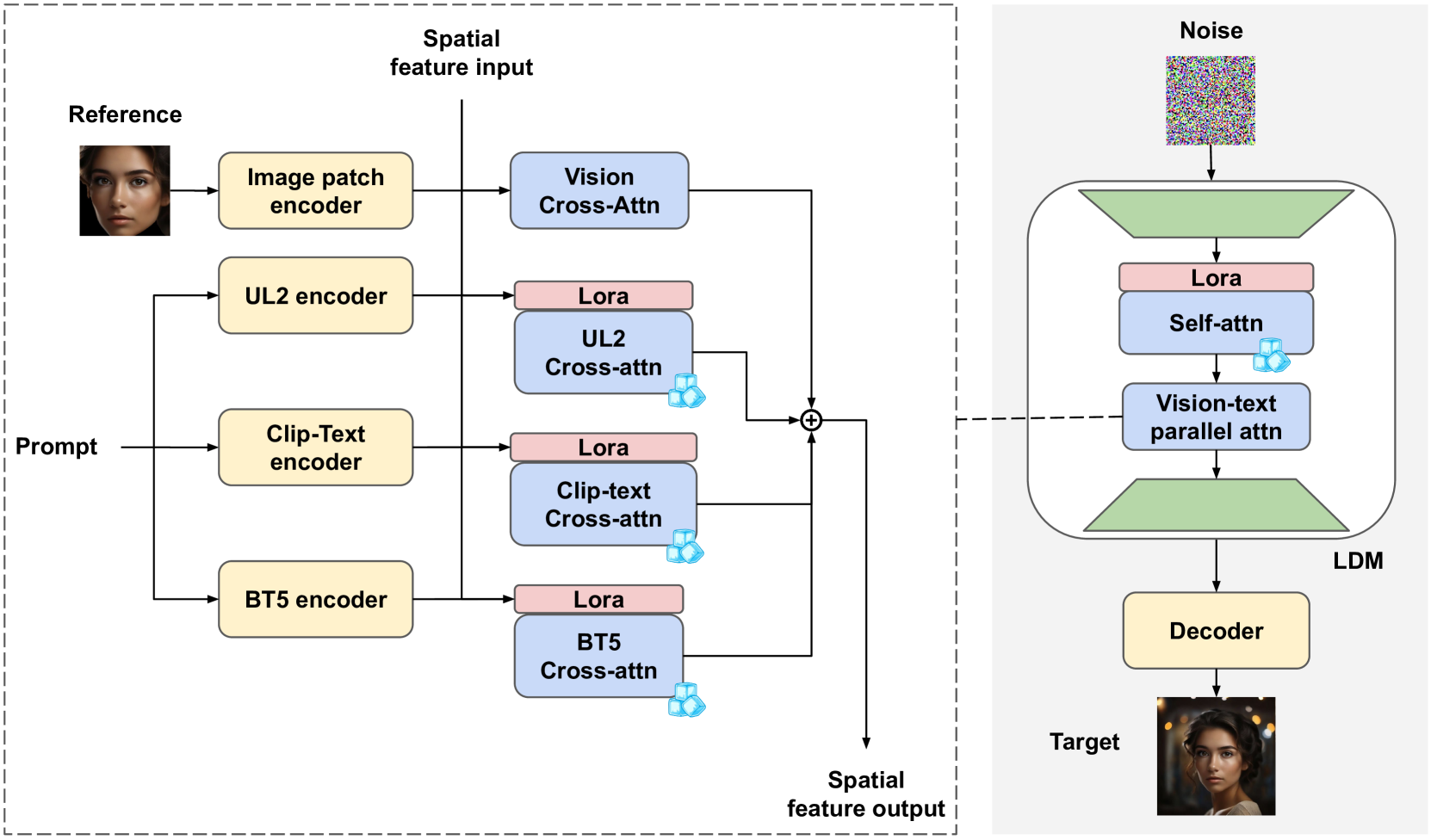
项目一图像描述
概要: 本文介绍了 Imagine yourself,一种无需调优的最先进个性化图像生成模型。与传统的个性化生成模型需要针对每个用户进行特定调优不同,Imagine yourself 采用了一个共享框架,通过提取参考图像的视觉嵌入并将其注入到扩散生成过程中,无需对个体进行额外调整。该模型引入了三大创新:1) 合成配对数据生成机制,提高生成图像的多样性;2) 并行注意力架构,包含三种文本编码器和一个可训练的视觉编码器,以提高文本与图像的对齐性;3) 粗到细多阶段微调方法,逐步提升图像质量。实验表明,Imagine yourself 在身份保持、视觉质量以及文本对齐性方面显著优于现有的个性化生成模型,并在所有评估维度上通过了人类评价的验证。
标签: #个性化图像生成 #Tuning-Free #AI #Diffusion Models #文本对齐 #视觉质量
NovelAI Diffusion V3 中对 SDXL 的改进

Novel Diffusion V3 Demo 图
概要: 在 NovelAI Diffusion V3 中,对 SDXL 进行了多项关键改进,提升了文本到图像生成的质量、效率和灵活性。
- 文本对齐性增强:通过并行注意力机制和多个文本编码器(如 CLIP、UL2、ByT5)的整合,显著改善了文本描述与生成图像的匹配度,尤其在复杂场景生成中效果突出。
- 图像质量提升:多阶段微调策略和合成配对数据机制提升了生成图像的细节和多样性,增强了模型处理变化和复杂场景的能力。
- 标签系统优化:引入动态排序和优先级管理,帮助用户更精准地检索和生成符合需求的图像。
- 4. 生成速度加快:通过更高效的推理机制,生成时间缩短,资源消耗降低。
这些改进让 NovelAI 的图像生成在准确性、视觉效果和生成效率方面都达到了新的高度。
标签: #SDXL #NovelAI #文本对齐 #图像生成 #标签优化
Make Pixels Dance: 扩散模型中的动态图像生成

Make Pixels Dance 的 Demo 图
概要: Make Pixels Dance 项目探索了如何通过扩散模型生成具有动态效果的图像,特别是应用于动画和视觉艺术领域。该项目的核心目标是将扩散模型用于生成不只是静态的图像,而是具有运动感和动态表现的视觉内容。其主要创新点包括:
- 动态图像生成:通过调整扩散模型的参数,生成具有动态感的连续帧图像,为动画创作带来全新的可能性。
- 艺术与技术结合:将生成模型与艺术创作相结合,生成更具表现力的视觉效果,适用于动画、数字艺术等领域。
- 可调节性强:用户可以通过改变模型的参数和输入条件,生成不同风格、运动速度和图像细节的动态内容。
Make Pixels Dance 展示了生成模型在创意视觉和动画领域的潜力,进一步拓宽了扩散模型的应用边界。
标签: #动态图像生成 #扩散模型 #AI 创意艺术 #动画生成
MIMO:具有多模态输入的视觉 Transformer

MIMO 的 Teaser 图
概要: MIMO (Multimodal Input Vision Transformer) 是一种基于 Vision Transformer 的新型模型,专门用于处理多模态输入,包括图像、文本和其他形式的数据。该模型的核心设计是同时处理多种输入模态,从而提升视觉任务的表现。其主要特点包括:
- 多模态融合:MIMO 模型能够同时处理图像、文本等多种数据源,利用跨模态的信息融合,提升视觉理解和任务完成的精度。
- 高效的 Transformer 架构:基于 Vision Transformer(ViT)的设计,使得 MIMO 能够在视觉任务中高效处理大量数据,并在复杂场景中表现出色。
- 多任务学习:MIMO 支持多任务学习,适用于需要同时处理多种输入类型的任务,如图像分类、目标检测以及场景理解等。
MIMO 模型展示了多模态输入在提升视觉任务表现方面的潜力,特别是在复杂场景中的应用,如自动驾驶、智能监控等。
标签: #VisionTransformer #多模态输入 #AI #深度学习 #计算机视觉
Emu: BAAI 的多模态大模型项目

Emu 的 Architecture 图
概要: Emu3是由北京智源人工智能研究院(BAAI)开发的多模态大模型,专注于整合视觉、语言和其他模态数据进行理解和生成。Emu3是该项目的最新版本,结合了最先进的 Transformer 架构,提升了多模态任务的处理能力。其主要特点包括:
- 多模态融合:Emu3 能够同时处理图像、文本等多种模态的数据,支持图像生成、文本理解和跨模态任务,如图文生成和问答。
- 强大的生成能力:Emu3 通过深度学习模型进行训练,能够生成高质量的图像,并且在图像生成和文本生成之间建立更好的语义联系。
- 开源社区支持:Emu 项目在 GitHub 上开源,鼓励开发者和研究人员参与贡献和优化,推动多模态大模型的应用和发展。
Emu3 项目展示了多模态模型在理解和生成复杂信息方面的强大能力,适用于智能助手、内容创作、图像生成等多种应用场景。
标签: #多模态 #生成模型 #Emu #AI #视觉与语言融合
PromptSliders: 通过文本嵌入进行高效的提示优化与图像编辑
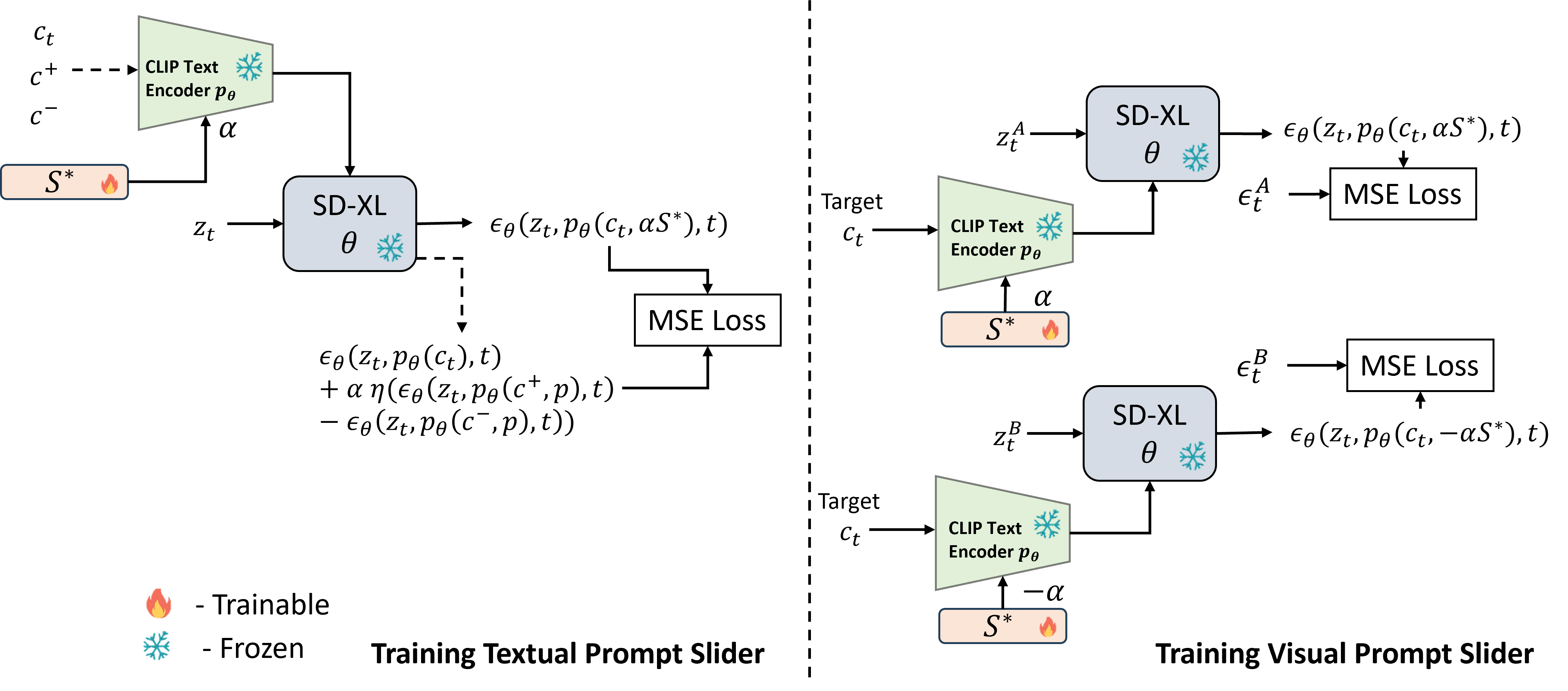
PromptSliders 的 Architecture 图
概要: PromptSliders 是一种基于文本嵌入的图像生成和编辑优化方法,旨在通过精确控制生成图像中的属性来实现高效的提示调整。与传统的 Low-Rank Adapters (LoRAs) 方法相比,PromptSliders 不仅更快,而且消耗更少的计算资源。该方法可以跨不同的扩散模型版本(如 Stable Diffusion v1.5 和 SD-XL)共享使用,特别适用于生成模型中的精细化控制。
- 精细化图像控制:PromptSliders 通过学习文本嵌入来掌握概念(如属性和对象)的控制,不需要为不同模型架构重新训练 LoRAs,使得在多个模型间共享概念成为可能。
- 高效计算:相比使用 LoRAs,PromptSliders 不需要加载和卸载适配器,生成速度提高了 30%,而且每个概念嵌入仅需 3KB 的存储空间,大幅降低了内存和计算成本。
- 概念删除功能:除了学习新概念外,PromptSliders 还可以移除不需要的概念,如某些艺术风格或不适合的内容,使生成结果更加符合用户需求。
- 4. 通用性强:该方法适用于共享相同文本编码器的模型,可以轻松在不同版本的扩散模型间通用,增强了生成模型的灵活性和适应性。
PromptSliders 的提出解决了现有图像编辑方法中的推理效率和概念控制问题,为更高效的图像生成和编辑提供了一个实用的解决方案。
标签: #PromptSliders #文本嵌入 #生成模型 #图像编辑 #高效优化
参考链接
- Imagine yourself:无需调优的个性化图像生成
- NovelAI Diffusion V3 中对 SDXL 的改进
- NovelAI 标签系统
- Generative Agents with Visual Memory
- Make Pixels Dance: 扩散模型中的动态图像生成
- Molecular Modeling AI Initiative by Allen Institute
- MIMO: Vision Transformer with Multimodal Input
- Emu: BAAI 的多模态大模型项目
- Emu3 GitHub 页面
- PromptSliders: 基于滑动条的提示优化模型
- PromptSliders 论文
- PromptSliders GitHub 页面