YuE赋能长篇AI音乐创作|VACE统一视频编辑|MagicInfinite无限制视频生成【AI周报】
YuE赋能长篇AI音乐创作|VACE统一视频编辑|MagicInfinite无限制视频生成【AI周报】

摘要
本周亮点:YuE 基于 LLaMA2 架构,实现长篇 AI 音乐创作与风格转换;VACE 采用 Video Condition Unit,统一视频生成与编辑任务;VideoPainter 提出双分支框架,提升视频修复质量与身份一致性;ConsisLoRA 解决 LoRA 风格迁移中的一致性问题。
目录
- YuE:基于LLaMA架构的开源长篇音乐生成模型
- VACE:一体化视频生成与编辑框架
- MagicInfinite:基于文本和语音生成无限制的动态视频
- EasyControl:为Diffusion Transformer添加高效且灵活的控制
- VideoPainter:任意长度视频修复与编辑的即插即用上下文控制
- ConsisLoRA:增强基于LoRA的风格迁移的一致性
YuE:基于LLaMA架构的开源长篇音乐生成模型
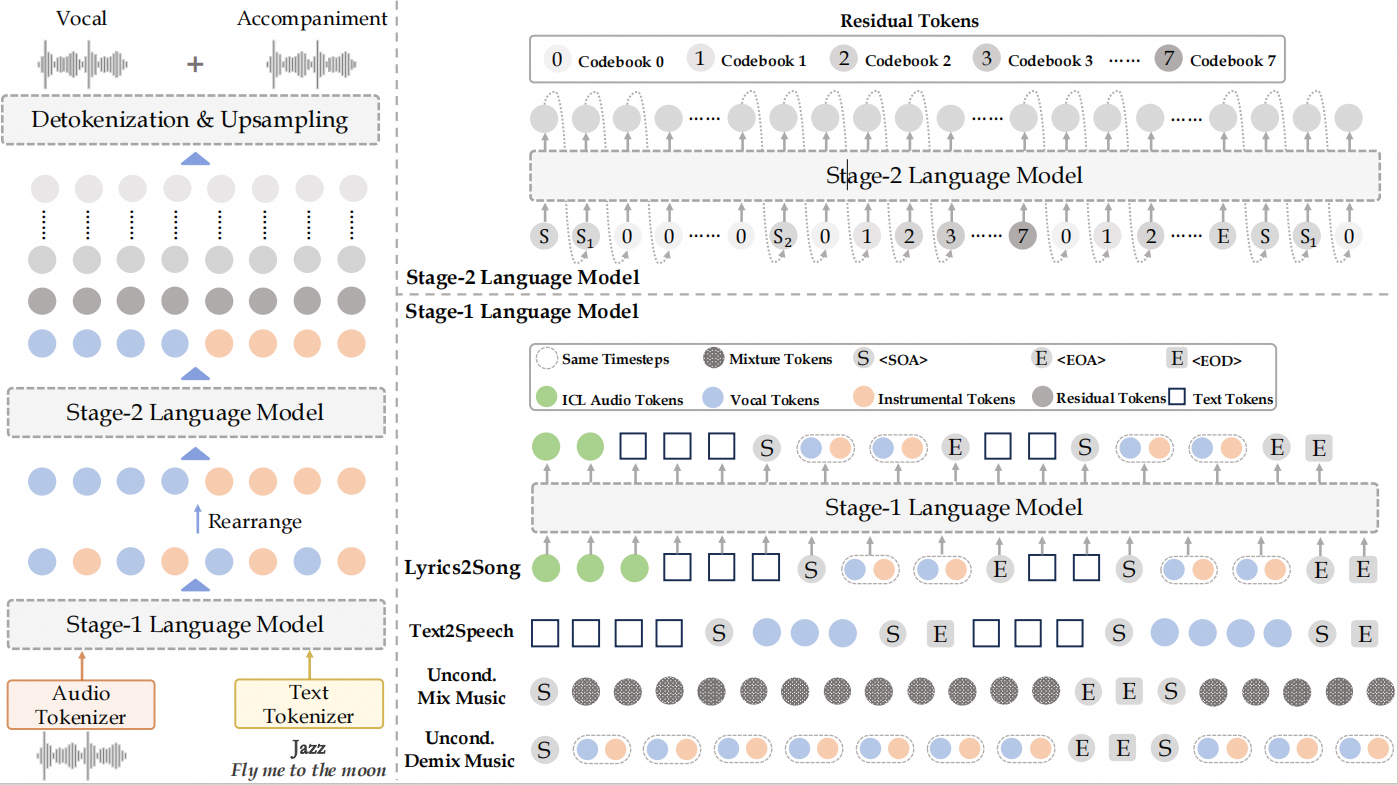
概要:YuE 是由 Multimodal Art Projection (M-A-P) 提出的开源长篇音乐生成模型,旨在解决歌词到歌曲生成的挑战。基于 LLaMA2 架构,YuE 可以生成最多五分钟的音乐,保持歌词与音乐结构的对齐,并提供引人入胜的旋律和伴奏。YuE采用了几种关键技术,包括基于轨道的下一个标记预测、结构性渐进条件和多任务预训练等,确保长文本和歌词的对齐。此外,YuE还支持风格转移,能够将不同语言或风格的歌曲转化为新的形式,如将日本城市流行转为英文嘻哈,同时保持伴奏不变。通过广泛的评估,YuE在音乐性和人声灵活性方面超越了部分专有系统。YuE不仅可以用于生成,还能够应用于音乐理解任务,并在 MARBLE 基准测试中超越了现有技术。
标签:#YuE #AI音乐生成 #LLaMA2 #长篇音乐生成 #歌词到歌曲 #开源 #风格转移
VACE:一体化视频生成与编辑框架
概要:VACE 是由 Tongyi Lab 提出的统一视频生成与编辑框架,基于 Diffusion Transformer 设计,支持 参考图像到视频生成、视频编辑、掩码视频编辑 等多种任务。由于视频合成需同时保持时空一致性,实现统一的生成与编辑框架极具挑战。VACE 通过引入 视频条件单元(Video Condition Unit, VCU),将编辑、参考、掩码等任务需求组织为统一接口,并结合 上下文适配器(Context Adapter) 结构,利用时空维度的任务表示,使模型能灵活适应不同的视频任务。实验表明,VACE 在多个子任务上的表现可与专用模型媲美,同时支持灵活的任务组合,拓展了视频生成与编辑的应用边界。
标签:#VACE #视频生成 #视频编辑 #扩散变换器 #时空一致性 #多任务学习
MagicInfinite:基于文本和语音生成无限制的动态视频

概要:MagicInfinite 是由 Hedra Inc. 推出的创新性 Diffusion Transformer (DiT) 框架,旨在突破传统肖像动画的限制,生成高保真度的动态视频。该模型支持多种角色类型,包括真实人类、全身人物和风格化的动漫角色,能够处理各种面部姿态(如背面视角)和多角色场景中的精确说话人指定。其主要创新包括:1. 采用 3D 全注意力机制结合滑动窗口去噪策略,实现无限制的视频生成,确保时间一致性和视觉质量;2. 通过两阶段课程学习方案,整合音频以实现唇形同步,利用文本增强表达动态,并通过参考图像保持身份一致性,从而实现对长序列的多模态控制;3. 使用区域特定的掩码和自适应损失函数,在全局文本控制和局部音频指导之间取得平衡,支持特定说话人的动画。该方法的效率通过创新的统一步长和 CFG 蒸馏技术得到提升,相比基础模型,推理速度提高了20倍。实验结果显示,MagicInfinite 在音频唇形同步、身份保持和动作自然性方面表现优异。
标签:#Diffusion Transformer #肖像动画 #多模态控制 #视频生成 #计算机视觉
EasyControl:为Diffusion Transformer添加高效且灵活的控制
概要:EasyControl是一种创新框架,旨在为Diffusion Transformer(DiT)架构引入高效且灵活的控制机制。该方法通过以下关键创新实现:首先,提出了轻量级的条件注入LoRA模块,作为即插即用的解决方案,能够在不修改基础模型权重的情况下,灵活地引入多样化的条件信号。值得注意的是,即使仅在单一条件数据上进行训练,该模块也支持在零样本情况下的多条件泛化。其次,提出了位置感知训练范式,通过将输入条件标准化为固定分辨率,允许生成任意纵横比和灵活分辨率的图像,同时优化计算效率。最后,开发了因果注意力机制,结合KV缓存技术,适用于条件生成任务,显著降低了图像合成的延迟,提高了整体框架的效率。通过广泛的实验,EasyControl在各种应用场景中表现出卓越的性能。
标签:#Diffusion Transformer #条件生成 #LoRA模块 #位置感知 #因果注意力机制 #KV缓存
VideoPainter:任意长度视频修复与编辑的即插即用上下文控制

概要:VideoPainter 是由 香港中文大学 和 腾讯ARC实验室 等机构联合推出的一种高效的双分支视频修复与编辑框架,旨在解决当前视频修复方法在处理完全遮挡对象、背景保留与前景生成平衡,以及长视频中身份一致性维护等方面的挑战。该框架引入了一个轻量级的上下文编码器,以即插即用的方式将背景指导信息注入预训练的视频扩散Transformer中,从而增强背景整合与前景生成能力,并支持用户自定义控制。此外,VideoPainter 提出了目标区域ID重采样策略,以在任意长度的视频修复中保持身份一致性。为了支持大规模训练和评估,研究团队构建了目前最大的包含分割掩码和密集字幕标注的视频修复数据集VPData和评估基准VPBench。实验结果表明,VideoPainter 在视频质量、掩码区域保留和文本一致性等关键指标上实现了最新的性能,并在视频编辑等下游应用中展现出良好的潜力。
标签:#视频修复 #视频编辑 #扩散模型 #双分支架构 #上下文控制
ConsisLoRA:增强基于LoRA的风格迁移的一致性

概要:ConsisLoRA 是由 中山大学 等机构提出的一种创新方法,旨在解决现有LoRA(Low-Rank Adaptation)风格迁移方法中存在的内容不一致、风格错位和内容泄漏等问题。该方法通过优化LoRA权重,使模型直接预测原始图像而非噪声,从而增强内容和风格的一致性。此外,ConsisLoRA 提出了两步训练策略,将参考图像的内容和风格学习解耦合,并引入逐步损失过渡策略,以有效捕捉内容图像的全局结构和局部细节。在推理阶段,该方法还提供了引导机制,允许对内容和风格强度进行连续控制。通过定性和定量评估,ConsisLoRA 在内容和风格一致性方面表现出显著改进,同时有效减少了内容泄漏。
标签:#风格迁移 #LoRA #内容一致性 #风格一致性 #图像生成