Conceptrol精准概念控制 | ChatAnyone实时数字人|Lumina-Image 2.0突【AI周报】
Conceptrol精准概念控制 | ChatAnyone实时数字人|Lumina-Image 2.0突【AI周报】

摘要
本周亮点:Conceptrol实现精细风格控制;SMS优化视频表征;FAR提升长时序理解;ChatAnyone风格化数字人;Lumina-Image-2.0加速扩散模型推理;CFG-Zero⋆优化无分类器引导,增强生成质量,其余详见正文。
目录
- Conceptrol:零样本个性化图像生成的概念控制
- SMS:基于 Style Matching Score 的平衡图像风格化
- FAR:基于自回归模型的长视频生成
- EditCLIP:面向图像编辑的表示学习
- ChatAnyone:基于分层运动扩散模型的实时风格化肖像视频生成
- Lumina-Image 2.0:统一高效的文本生成图像框架
- CFG-Zero⋆:改进流匹配模型的无分类器引导方法
Conceptrol:零样本个性化图像生成的概念控制

概要:Conceptrol 是由 新加坡国立大学 提出的一种创新方法,旨在提升零样本适配器在个性化图像生成中的性能。现有方法在平衡个性化内容保留和文本提示遵循方面存在困难。Conceptrol 通过引入文本概念掩码,约束视觉规范的注意力机制,从而增强个性化内容的生成能力。该方法无需额外训练或数据,即可在 Stable Diffusion、SDXL 和 FLUX 等模型上实现高效的个性化图像生成。实验结果显示,Conceptrol 相较于传统零样本适配器,在个性化基准测试中性能提升高达89%,并且在某些情况下超越了如 DreamBooth LoRA 等需要微调的模型。
标签:#个性化图像生成 #零样本学习 #概念控制 #Stable Diffusion #新加坡国立大学
SMS:基于 Style Matching Score 的平衡图像风格化

概要:SMS(Style Matching Score)是由 新加坡国立大学 等机构提出的一种创新图像风格化方法,旨在平衡风格迁移中的风格匹配与内容保留。该方法将图像风格化视为风格分布匹配问题,通过设计精巧的评分函数,从预训练的风格相关 LoRA 模型中估计目标风格分布。为自适应地保留内容信息,SMS 提出了渐进式频谱正则化(Progressive Spectrum Regularization),在频域中引导风格化过程,从低频布局逐步过渡到高频细节。此外,SMS 引入了语义感知梯度优化技术(Semantic-Aware Gradient Refinement),利用扩散模型的语义先验生成的相关性图,选择性地对语义重要区域进行风格化。该优化方法将风格化从像素空间扩展到参数空间,可直接应用于轻量级前馈生成器,实现高效的一步风格化。实验结果表明,SMS 在风格对齐和内容保留方面优于现有方法。
标签:#图像风格化 #风格匹配 #内容保留 #扩散模型 #LoRA
FAR:基于自回归模型的长视频生成
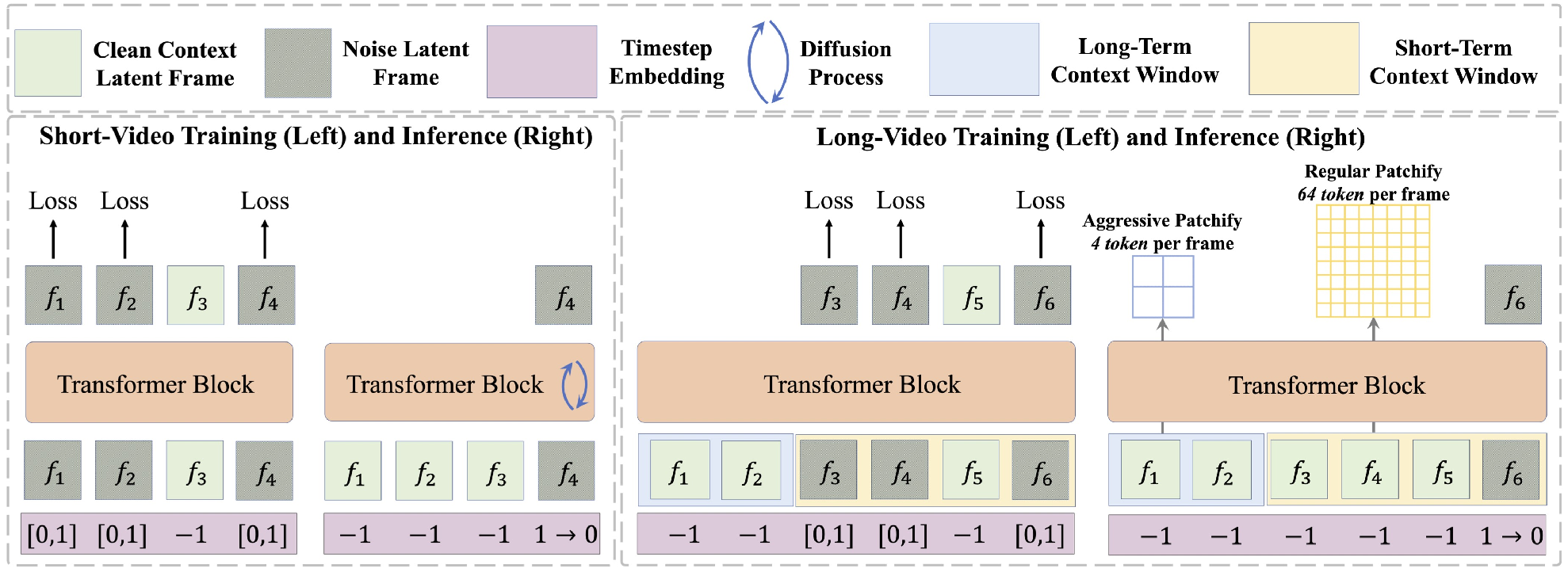
概要:FAR(Frame AutoRegressive)是由 新加坡国立大学 提出的一种视频自回归建模方法,旨在提升长视频生成的质量和效率。该模型通过预测连续帧之间的时间因果关系,实现了比传统基于离散标记的自回归模型更好的收敛性。FAR引入了FlexRoPE技术,在测试时为旋转位置编码添加灵活的时间衰减,支持将视频长度扩展至训练时的16倍。此外,FAR采用长短期上下文建模策略,结合高分辨率的短期窗口和低分辨率的长期窗口,平衡了局部细节和全局信息,显著提升了长视频的生成质量和时间一致性。
标签:#视频生成 #自回归模型 #长视频建模 #FlexRoPE #时间一致性
EditCLIP:面向图像编辑的表示学习

概要:EditCLIP 由 沙特阿卜杜拉国王科技大学(KAUST) 提出,旨在通过联合编码原始图像及其编辑版本,学习统一的编辑表示。该方法在示例引导的图像编辑和自动编辑评估任务中表现出色。具体而言,EditCLIP用参考图像对的嵌入替代 InstructPix2Pix 中的文本指令,实现高效且多样化的编辑效果。此外,EditCLIP 通过测量图像对的嵌入相似度,提供与人类判断高度一致的编辑质量评估指标。
标签:#图像编辑 #表示学习 #CLIP #InstructPix2Pix #自动评估
ChatAnyone:基于分层运动扩散模型的实时风格化肖像视频生成

概要:ChatAnyone 是由 阿里巴巴通义实验室 推出的一种实时风格化肖像视频生成框架,旨在通过音频输入生成具有丰富表情和上半身动作的肖像视频。该方法采用高效的分层运动扩散模型,结合显式和隐式运动表示,实现头部与身体动作的同步生成,并支持细粒度的风格控制。此外,ChatAnyone 引入了混合控制融合技术,通过注入手部控制信号和面部细化模块,生成更为真实和生动的上半身动作,包括手势和面部表情。该框架支持最高 512×768 分辨率、30fps 的实时生成,适用于交互式视频聊天等应用场景。
标签:#实时视频生成 #肖像动画 #分层运动扩散模型 #风格化 #交互式视频聊天
Lumina-Image 2.0:统一高效的文本生成图像框架

概要:Lumina-Image 2.0 是由 Alpha-VLLM 团队推出的先进文本生成图像框架,旨在提升图像生成的质量和效率。该模型采用统一的 Next-DiT 架构,将文本和图像标记视为联合序列,实现自然的跨模态交互,并支持无缝任务扩展。此外,引入了统一的描述生成器(UniCap),专为文本生成图像任务设计,能够生成全面且准确的图像描述,促进模型收敛并增强对提示词的响应能力。在训练方面,Lumina-Image 2.0 采用多阶段渐进式策略,引入高质量数据集和辅助损失,提升图像细节和质量。在推理阶段,模型通过改进的采样方法,实现高效的图像生成。评估结果显示,尽管参数量仅为 26 亿,Lumina-Image 2.0 在多个基准测试中表现出色,体现了其良好的可扩展性和设计效率。
标签:#文本生成图像 #DiT #高效训练 #图像生成 #Lumina
CFG-Zero⋆:改进流匹配模型的无分类器引导方法

概要:CFG-Zero⋆ 是由 南洋理工大学 和 普渡大学 联合提出的改进型无分类器引导(Classifier-Free Guidance, CFG)方法,旨在提升流匹配(Flow Matching)模型在图像和视频生成任务中的质量和可控性。传统的 CFG 方法在模型训练初期可能因速度估计不准确,导致样本偏离最优轨迹。为解决这一问题,CFG-Zero⋆ 引入了两个关键改进:1. 优化缩放因子(Optimized Scale):通过引入可优化的缩放因子,校正条件和无条件速度场之间的偏差,提升引导的准确性。2. 零初始化(Zero-Init):在 ODE 求解器的前几步中将预测速度设为零,避免初始阶段的错误引导,确保样本沿正确轨迹生成。
标签:#CFG #流匹配模型 #图像生成 #视频生成