
Illustrious XL 3.0-3.5-vpred: 2048 Resolution and Natural Language
Illustrious XL 3.0–3.5-vpred represents a major advancement in Stable Diffusion XL (SD XL) modeling, notably supporting resolutions ranging seamlessly from 256 up to 2048. The v3.5-vpred variant particularly emphasizes robust natural language understanding capabilities, comparable in sophistication to miniaturized large language models (LLMs), achieved through extensive simultaneous training of both CLIP and UNet components.
Training Objectives and Summary: eps vs. vpred
The Illustrious v3.0-v3.5 series was designed with two distinct training objectives to explore behavioral differences:
V3.0-epsilon employs epsilon-prediction (noise prediction), establishing itself as a stable "base" model suitable for future training tasks, notably demonstrating compatibility with LoRA training. The model shows distinct, stylish outputs compared to vpred variants at default - sometimes it is best model with certain aesthetic scoring.
V3.0-vpred utilizes velocity-prediction (v-parameterization), demonstrating improved compositional understanding yet initially plagued by significant issues, including catastrophic forgetting, domain shifts, oversaturated colors, and collapsed color palettes due to flawed zero terminal SNR implementation.
V3.5-vpred is trained with experimental setups, to mitigate the mentioned problems. The model has shown significantly more stable colors, however does not naturally generate vibrant colors. The functionality has moved to certain controlling tokens.
Unfortunately, the v-parameterization variants have certain problems regard to finetuning / PEFT, which I consider as very critical feature for Illustrious series. The thoughtful tests are ongoing regard to the model to resolve the method for stable finetuning. I will include the current hypothesis regarding to the phenomenon.

 58.46% of the pixels are 'exactly white, #FFFFFF'. This is an abnormal result, which shows how v-parameterization objective models can collapse.
58.46% of the pixels are 'exactly white, #FFFFFF'. This is an abnormal result, which shows how v-parameterization objective models can collapse.
Technical Challenges in V-Parameterization
The primary issue with v-parameterization involved incorrect variance estimation attributed to zero terminal SNR. This miscalculation caused the model to excessively remove noise early on, overestimating the clarity of images prematurely, thus resulting in saturated or unrealistic colors that persisted throughout denoising steps.
Despite these challenges, the v-parameterization brought substantial compositional improvements. For example, the model successfully interpreted complex directional prompts (e.g., "left is black, right is red"), a significant achievement previously unattainable with epsilon-based models.
(Epsilon models, however, has shown significant improvements on compositions which can't be explained with just randomness. See below).
The Comparative Tests—Color Separation, Really Complex Prompts
I showcase here the following three distinct setups:
- Simple Prompt: Simple enough (<75 tokens) prompts are given, and model is asked for inference.
- Complex Prompt (424 tokens): The really long, complicated, and 'paraphrased' sentences are given to confuse the model.
- FFT with simple prompts: The model intermediate latents are decoded and analyzed with Fast Fourier Transform, to analyze low frequency signal changes.

The model is partially following the prompt, "There are two girls in the image. The girl in the left is red hair with sea-black eyes. The girl in the right is blue hair, and firey ruby eyes" with high success rate, however exposes oversaturation in colors.
The simple prompt based inference result, also shows the interesting results in v3.0 models.
v3.0 Epsilon also shows significant improvement, which is still not explained well by myself.
"Two girls are depicted in the image, the left side is red hair girl with yellow eyes, blue skirt. The right side is blue-toned silver hair girl with yellow earring, blue pupils and silver dress." With , Sampler: Euler, Schedule type: Normal, CFG scale: 7.5.

v3.0-epsilon inference result. surprisingly, epsilon model sometimes works well, here 23/25 success.

v3.0-vpred’s inference result. The model shows oversaturated colors at default.

v3.5-vpred’s inference result. The model shows mid-range colors with separation.
Complex Prompt Inference Result
Here is the prompt used for inference:
A breathtaking scene unfolds with two girls standing together, a striking contrast in both appearance and demeanor. The girl on the left has flowing, deep red hair, cascading in soft waves down her shoulders, with strands illuminated by the ambient light. Her eyes are a mesmerizing shade of sea-black, like the ocean at midnight, deep and endless, reflecting a quiet mystery. She has a gentle, thoughtful expression, her lips slightly parted as if about to speak, her gaze filled with an unspoken story. She wears an elegant, dark-blue dress with silver embroidery resembling delicate ocean waves, flowing like liquid silk around her slender frame. The gentle breeze lifts the fabric slightly, giving her an ethereal presence.
Beside her, the girl on the right is a vivid contrast—her hair is a brilliant shade of blue, short yet tousled with an electric vibrancy, strands catching the light like crystalline ice. Her fiery ruby-red eyes burn with intensity, gleaming with an almost supernatural glow. Her sharp, confident smirk reveals her bold personality, a spirit unafraid of the world. She is clad in a striking ensemble—black with intricate red patterns resembling flickering flames, an outfit that exudes strength and energy. The contrast of her fiery eyes against her cool-toned hair creates an almost otherworldly effect, as if she embodies the elements themselves.
The setting complements their striking presence—perhaps a twilight sky over a vast ocean, where the last remnants of the sun cast a golden glow across the waves, mixing with the incoming darkness. The wind rustles through their hair as they stand close, an unspoken connection between them. Or maybe they are in a futuristic cityscape, neon lights reflecting in their eyes, the bustling energy of the world around them barely touching the silent understanding they share. Their postures mirror their personalities—one calm, introspective, a quiet storm; the other bold, fiery, a force of nature.
The image captures the balance between them—opposites yet intertwined, like fire and water, night and day. Their expressions, their outfits, and the atmosphere all tell a story waiting to be unraveled. masterpiece

The inference result from v3.0-vpred. The model was not able to generate stable outputs, and exposed oversaturation.

The inference result from community-driven v-parameterization model. The model also exposed oversaturation, and was unable to follow the prompts.


Generation results from other popular epsilon prediction models. The prompt exposed certain problem on the models.

Generation result from v3.0-epsilon. The model was able to generate somehow, the stylish result among all the results with more stability.

Generation result from Flux.1-Schnell. The model has followed the prompt distinctly well with lack of stylization.

Generation result from Illustrious-v3.5-vpred. The model has shown significantly stable generation results similar to Flux somehow, however lost stylish generation unlike v3.0-epsilon. I note here that Flux’s prompt following is “distinctly good and robust” whilst v3.5-vpred’s prompt following “can be limited” - it highly depends on the given prompt format.
Denoising Pattern Analysis
All inference used empty black background prompt with DDIM 10 steps.

v3.0-epsilon

v3.0-vpred

v3.5-vpred
Mathematical Insights and Adjustments
Post-analysis, mathematical adjustments to variance calculations stabilized the vpred training process, significantly enhancing prompt comprehension. The epsilon model, conversely, retained issues with accurately following complex conditioning due to an overreliance on initial noise sampling, despite the ability to generate the stylized outputs.
The "golden noise" phenomenon referenced from recent research underscored the importance of good initial noise conditions for optimal model performance, reinforcing the superiority of vpred methods in complex prompt scenarios.
In easy words, epsilon model follows the low frequency features, and cannot overcome the color domain, which causes anatomy / bad initial conditioning afterwards.
Whileas, v-parameterization models can overcome this problem with high noise removal in initial steps.

In fact, the zero terminal SNR / or v-parameterization makes "first initial step very strong" but not for other steps. After the first step - the colors are mostly 'fixed', - low frequency features are 'fixed', so model does not expect to change main colors after that.
However, the "snr estimation" -or variances are 'errored' - the colors are reverted one step.

The phenomenon is complicated - this appears regardless of samplers, schedulers, or even with / without zero terminal SNR in inference.
Without CFG, the model shows some better visualization - the "mid range steps" - they are actually trying to generate artificial high frequency features!
Since model is NOT extensively trained with "empty images" - as a result, the model natively assumes that "some reasonable high frequency feature should be placed", same to epsilon objective. This is the bias.
The img2img process, also shows notable behavior : the overshooting latents shows significantly 'inverted' latent colors after initial step. This means that "somehow model learnt to fix overshooting" - I might have some idea to validate & improve this phenomenon even further, currently planning some more setups. The initial thought, is to test samplers & schedulers, which would make sense to use the initial steps behavior and exponentially decrease- which would make sense.
I will introduce Illustrious v4 - when I am prepared mathematically, to solve the proposed overshooting problem.
Dataset Insights and Color Control
The correct control of colors in v-parameterization variants, however exposes other problem-
The model would follow the average color of dataset. It is wrong to expect model to generate vibrant colors naturally without dataset being dominantly vibrant.
But, in fact, the "variant colored" images are less than 10% - the model naturally does NOT show the vibrant colors.
Here is simple color analysis:
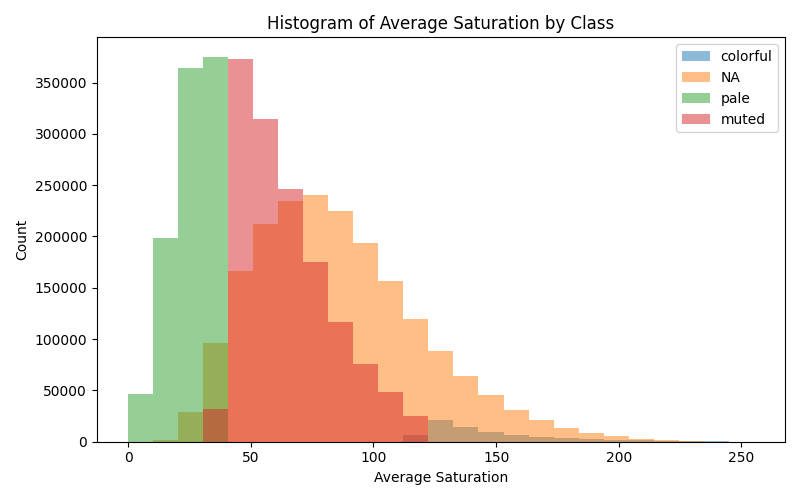
We can call the image is "colorful" when its saturation is above 120, but with saturation stdev < 50 (variable colors saturation). In 4.4M image sample analysis, the result is not surprising - most of the images, are not "colorful" or 'saturated' - then how would model learn the "vibrant colors"?
Very small portion of the dataset have 'vibrant or colorful' images.
How would we control colors if most of the image are not vibrant, without sacrificing muted color - not making model biased toward certain colors?
The answer was, doing some more analysis on the datasets & introducing controlling tokens.
Here, we introduce the "control tokens" - explicitly tagged by image analysis:
Contrast: 'low contrast', 'medium contrast', 'high contrast', 'very high contrast'
Brightness: 'dark', 'normal brightness', 'bright', 'very bright'
Sharpness: 'blurry', 'slightly sharp', 'sharp', 'very sharp'
Dynamic Colors: 'static colors', 'medium dynamic colors', 'high dynamic colors', 'very dynamic colors'
Colorfulness: 'monotonic color', 'medium colorfulness', 'high colorfulness', 'very high colorfulness'
Saturation: 'muted colors', 'average colors', 'vibrant colors', 'very vibrant colors'
The control token, works specifically in v3.0-epsilon and v3.5-vpred model, however, v3.0-vpred model may not work well the token. However, the visual result may be "appealing" due to vibrant colors - you might like the result when proper prompt was used with the model.
The idea is quite simple, however some cases are not well-handled, there are extremely small amount of "very dark" or "very white" images, this is near opposite of statements which claims "model requires #000000 or #FFFFFF".
Also, common phrase, "dark" is contaminated - "black theme" might be better for usecases.
Unfortunately, I didn't have time to spend on finding which region contains those HSV-exact colors - will do some analysis on it.
The Academical Naming Convention
Here is the result from v3.0-epsilon, and v3.5-vpred:


With this 2 results, you might think "Oh the first one is v3.5-vpred and second one is v3.0-epsilon" — however its not! the first one is v3.0-epsilon, the second one is v3.5-vpred.
The namings, are purely academical, especially the "3" means it is "3rd academical breakthrough".
Some prompts - may obviously work better on certain versions.
The demo will be offered as soon as possible, so you would be able to compare & experiment soon.
LoRA Training Is Suffering
The LoRA training on v-parameterization models did not go well - this is also well known on v0.1-vpred model, and noobai vpred models, and flow based models as well. One hypothesis is - the low frequency features were not supposed to be 'trained' with limited dataset - it is far more fragile than high frequency features. Since v-parameterization models upsample the importance of low snr steps, they naturally also make model exposed to low frequency features - however, this causes drastic collapse of denoising kernels. Since LoRA training dataset is uncomparably small, it is fragile and nearly impossible to prevent.
One ongoing idea is to prevent this with sampling timesteps with weighting instead - since model seems to be more affected by low snr steps. and adding some robustness - I might have to check this as well. I hope I can showcase the good results very soon.
Ongoing Research and Future Directions
The Lumina-2.0-Illustrious (name can be changed), is currently being trained by OnomaAI's support, despite within limited budget.
Here are some samples, I'd say the model is currently '20% toward v0.1 level' - We spent several thousand dollars again on the training with various trial and errors. The model is currently being carefully tested for estimating total compute budget, but after we cover the certain budget, the training can be accelerated. We promise the model to be open sourced right after being prepared, which would foster the new ecosystem.



In theory, when the training is successfully done, it will be similar-sized natural language understanding DiT model.
Unlike flux, this would cost far less budget for LoRA training - and in worst case, it can work as smallest illustration "draft" generator, which robustly understands the natural language prompting for various setups & poses. In best case scenario, we would be able to generate text-in-image one shot!
Flux is good - but obviously training compute is big, and model itself is big. This was also why we were supporting who tries to train / reduce the Flux model's size within budget- this was secret, but it was disclosed now. We will definitely continue to contribute to open source, maybe secretly or publicly. Well, yes, we tried and opened about SD3.5 model finetuning too. You might be already watching some results.
I'm preparing a lot of stuff to be disclosed soon. See you later!